内容
Pi 现在已成为 Earendil 的一部分,但从重要意义上说,它仍然是 Mario’s 的项目。他与它的问题跟踪器相伴的时间比我更久,也比我更早、更久地接触到了开源项目中这种新型智能体流量的古怪之处。这篇文章主要是我在跟踪器里待得更久、用 Pi 开发 Pi,以及观察至今所学到的一切之后,对自身经验的一些反思。
糊弄问题
不出所料,我们正在用 Pi 来构建 Pi。听起来像个可爱的自我内化用例,但它确实有助于理解我们在做什么。用智能体开发的一个有趣影响是,它会稍微改变问题跟踪器的角色。问题描述不只是用户发给维护者的消息,因为我们也会把它们当作 Pi 会话中提示词的输入。这是我可能会交给我的机器人 1 并对它说的话:“理解这件事,复现它,检查代码,然后提出修复方案。”
这意味着问题的形态以一种新的方式变得重要。糟糕的问题一直都很烦人,但至少很多问题只是含糊。现在我们还要面对另一类问题:5% 是人类写的,95% 是机器人生成的,而且大多是完全不准确的垃圾。一个带着看似合理但实际上错误诊断的糟糕问题,会制造额外工作。
眼下最令人恼火的失败模式,是人们提交的问题不是用自己的语言写的。它们里面包含了某处观察到的问题,但这些内容被扔进了机器人,机器人把它改写了一遍,结果弄得一团糟。通常,提示词写得很差,以至于生成的结论十有八九并不准确,却总是一副胸有成竹的样子。结果就是对根因的彻底瞎猜、伪造的最小复现、建议的实现策略、与相邻但往往并不正确的代码作类比,以及一长串可能有用也可能没用的错误类别。
这比没有诊断还糟。
我不想指向具体的问题,因为我真的不想说任何人的坏话,但这确实很让人沮丧。之所以沮丧,也是因为当我把那个问题交给 Pi 时,Pi 也会看到那个错误诊断。它不会把问题正文当成传闻,而是当成证据。它会很乐意沿着问题已经为它铺好的路线走下去,因为这些文字写得很自信,而代码引用看起来也很像那么回事。我们使用了一个叫作 /is 的自定义斜杠命令,其中明确写着这条指令:
不要相信 issue 中写的分析。请独立验证行为,并根据代码和执行路径得出你自己的分析。
遗憾的是,这并不能完全奏效,因为当人类先把他们的问题扔进机器人那套流程里时,机器人几乎会立刻把范围扩大。原本只是一个非常狭窄、基于事实的 bug 观察,最后会变成一个被大幅扩展、充满各种假设的面。至少就我个人而言,我越来越希望问题报告能被压缩成只有人类实际观察到的内容:
- 我运行了这个命令。
- 我本来预期会这样。
- 结果却发生了这个。
- 这里是确切的错误信息或日志。
这就够了。如果你用 LLM 理解了问题,那很好,也许可以把它作为后续评论补充出来。但 issue 本身和 issue 文本应该是你自己负责的内容。如果你不知道根因,就直接说不知道。我自己也会用机器人,我宁愿自己来做,也不要用你的糊弄内容。如果你的复现只是猜测,也请直说。如果唯一确凿的事实只是一段堆栈跟踪,那就把堆栈跟踪给我,然后到此为止。
糊弄滋生糊弄
我们之所以会看到充满糊弄内容的问题,不过是这些机器当下质量所致。遗憾的是,它们在创建高质量问题上的失败,也会延伸到大量生成的代码里。不是全部,但确实很多代码都会这样。我一次又一次遇到它们把问题和实现过度设计得离谱。
如果你告诉它们“这个损坏的会话日志会让读取器崩溃”,机器人往往会加一个容错读取器。然后它会再加一个回退,再来一个迁移,再加更多调试输出,然后还会为这一切补上测试。单看每一项,这些做法未必有错,但对整个系统来说,它们可能就是错的。
Pi 的核心是一套设计相当不错的会话日志,其中有必须保持的约束。机器人如今的行为却是假设根本不存在这些约束,而是试图让系统兼容各种畸形数据,并在这个过程中把复杂度炸上天。
几乎总是,正确的修复不是去处理坏状态,而是让坏状态根本不可能出现。对于像 Pi 会话日志这样的持久化数据,这一点尤为重要。它们会被打开、分支、压缩、导出、共享和分析。这里的目标是永远不要写出坏的会话数据。然而如果你放任机器人自由发挥,它就会试图用一个更宽松的读取器去处理会话日志里每一种坏数据情况。
我已经抱怨过很多次了,但在 Pi 的代码库上工作仍然不断印证这一点。这正是 LLM 编写的代码会滋生大量不必要复杂度的方式之一。所有这些模型看到的是局部失败,于是就试图在局部做防御。作为维护者,我们不得不不断把讨论拉回全局约束上;这本不该这么难,而且很耗费精力。
数量才是问题
还有数量上的问题。跟踪器正在收到大量 issue 和 PR,其中相当一部分显然有 LLM 协助。有些还行,没有一个出色,大多数就是差。总吞吐量本身就是一个维护问题。
你可能已经知道,Pi 的 issue 跟踪器会自动关闭所有来自新贡献者的 issue 和拉取请求,而我们有一套人工流程,可能会重新打开其中一些,或者批准某些个人。因此,自动关闭 -> 重新打开 -> 再次关闭,这对我们来说是一个很有意思的统计指标。
我在写这篇文章时,拉取了过去 90 天的公共 GitHub 跟踪器数据。排除 Earendil 成员后,还剩 3,145 个外部 issue 和拉取请求。其中 2,504 个因为来自未获批准的个人而被自动关闭。17% 最终被重新打开,不过这会稍微低估 issue,因为有些在我们修复期间仍保持关闭状态。如果把那些被主分支提交或已合并拉取请求引用的 issue 也算上,这个数字会上升到 26%。对于拉取请求来说情况更糟:714 个被自动关闭的 PR 中,最终有 60 个被合并,大约占 8%。
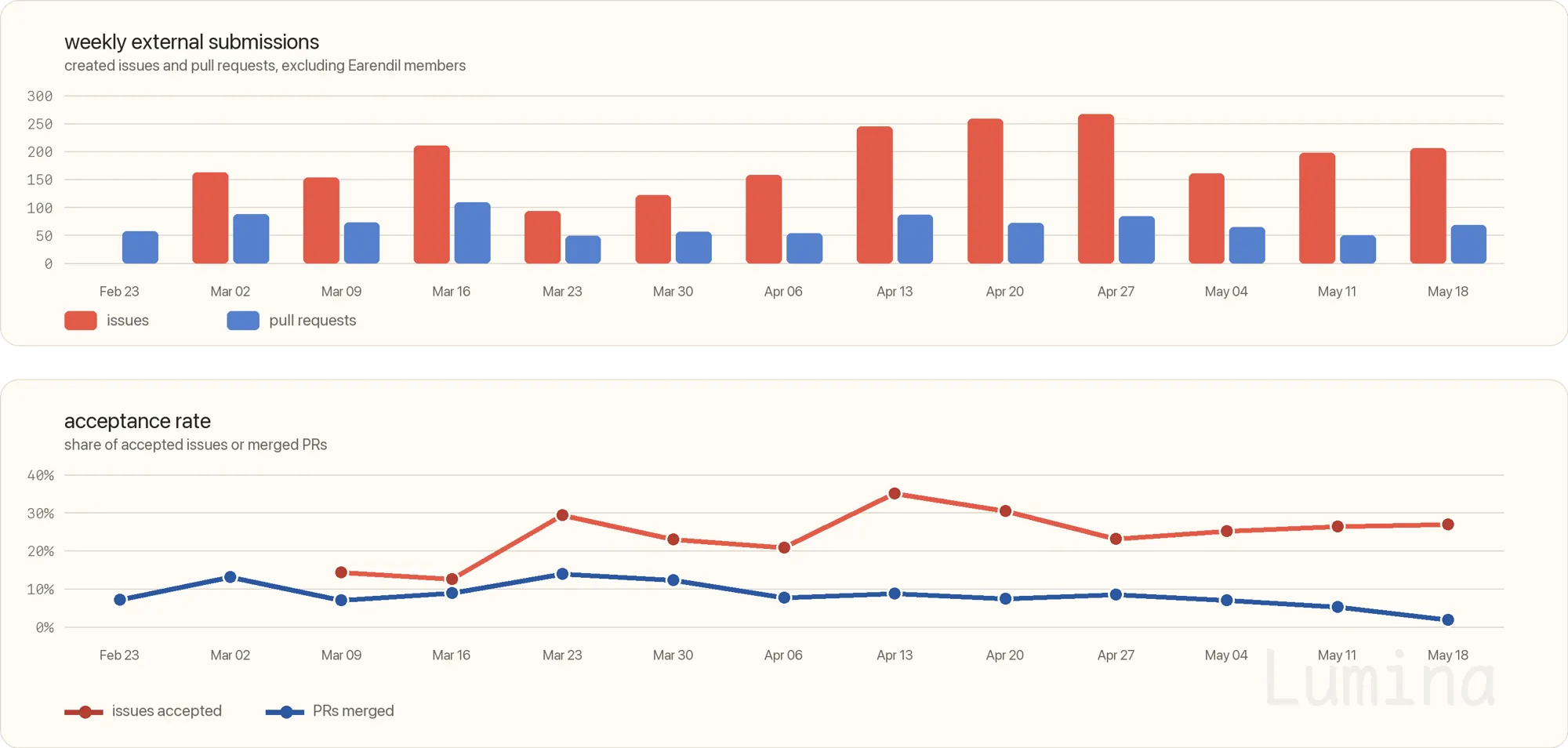
这些 issue 和 PR 里很多都完全是糊弄内容,有些情况下人类甚至都没意识到自己创建了它们。低质量垃圾信息的来源包括 OpenClaw 实例,以及一些人放进上下文里的技能,它们看起来会鼓励创建 issue。
GitHub 显然不是为这种新型开源形态设计的,但我越来越觉得,与其把责任更多归咎于 GitHub,不如归咎于所有让这段体验变得痛苦的人。如果你的机器人把别人的 issue 跟踪器糟蹋了,那不是 GitHub 的错,完全是你自己的错。
谨慎并行
Pi 也许是在 Pi 里构建的,但我们今天离 Bun 和 OpenClaw 已经达到的阶段还差得很远:完全脱离人工、自动化的软件工程。也许我们会达到那个阶段,我不知道。就今天而言,似乎我们还不知道怎么搞出一座黑灯工厂,而且也还没有这种意愿。话虽如此,确实已经存在不少并行工作,而且主要是用来复现问题。
我们为此使用的小型配置,由 Pi 自己提交的 .pi 文件夹里的三个小部分组成。/is(用于分析 issue)是一个分析 GitHub issue 的提示词:它会给 issue 打标签并分配负责人,读取完整讨论串和链接,然后明确告诉智能体不要相信 issue 里的分析,而要根据代码自行得出诊断。接着,一个扩展会添加一个 prompt-url-widget,它会在智能体启动前监视提示词,识别 /is(或 PR 对应命令)放进提示词里的 GitHub issue 或 PR URL,用 gh 获取标题和作者,把这些渲染到一个小型 UI 组件中,并重命名会话。它还会在会话启动或切换时重建这份状态,因此如果我们重新打开较早的调查,窗口仍会告诉开发者它对应的是哪个 issue。
实际上,这意味着可以同时打开多个 Pi 窗口,每个窗口都对不同的 issue 运行 /is,而当智能体各自独立进行复现和代码阅读时,界面会让这些调查在视觉上彼此区分开来。等调查完成后,就可以按顺序逐个处理。最后收尾时,/wr(wrap it up)就是对应的收尾提示词:它会从会话中推断 GitHub 上下文,更新变更日志,起草或发布带有免责声明的最终 issue 评论,只提交该会话中改动过的文件,在且仅在只有一个 issue 时添加相应的 closes #...,并从 main 推送。
开源关乎值得解决的难题
你大概已经注意到了,在后 AI 时代,开源正承受着一种奇怪的新压力。我们得到的代码、项目和 issue 都更多了。项目会在没有真正用户,或者只有一个临时受众的情况下出现;即便拥有数千星标的项目,寿命也可能只有几周。
对我们来说,Pi 的支撑层值得认真维护,因为它解决了棘手的协同问题,并打造了一个我们和他人都能在其上构建的平台。我们也知道,协同与合作会让大家都受益。很多时候,正确答案不是在本地绕过问题,而是让上游行为变正确。Mario 一直很坚持,不让 Pi 去粉饰每一个配置错误的网关,我们也在努力保住这种纪律。当网关行为正确时,所有人都受益。
遗憾的是,这种思维正在迅速消失,因为这些机器让本地绕行变得廉价,于是代码开始为每一种异常行为都堆积本地防御。原本应当由人和人讨论修复该放在哪里,结果却变成一个人和一台机器各自孤立地绕开问题。
请记住,AI 并没有增加需要软件的人数,也没有增加可以审查这些软件的维护者人数。它主要只是增加了代码数量,以及争夺注意力的项目数量。其中一部分是健康的,但很大一部分是在把本应共享的努力切碎。
我们需要更强的基础,而不是更弱的基础。开源需要更多协作,而不是更多与机器隔离完成的工作。人类沟通很难,当你能独自和你的机器人待在一起时,很容易想要回避它。但开源的价值并不来自孤立。价值在于社区,以及让项目得以超越原作者生命周期的结构。