内容
你的安全支出是否超过了攻击者的成本?
上周,我们了解到 Anthropic 推出的新 LLM——Mythos。这款模型在计算机安全任务方面“表现惊人”,以至于 Anthropic 并未将其公开发布。相反,仅向关键软件开发商开放了访问权限,以便他们有足够时间加固自身系统。
面对这一重大 AI 进展,我们迅速走过了处理此类声明的常规阶段:震惊、存在性焦虑、炒作、怀疑、批评,最后转向下一个话题。我建议大家采取观望态度,因为安全能力往往专为惊艳演示而设计。寻找漏洞本质上是一个定义明确、可验证的搜索问题。你并非在构建复杂系统,而是在对一个已存在的系统进行试探——这正适合用海量 tokens 来暴力破解。
昨天,第三方分析结果出炉,由AI 安全研究所(AISI)发布,基本支持 Anthropic 的说法。Mythos 确实 非常出色,“相比此前前沿模型已有显著提升,而当时网络安全性能本身就在快速进步。”
该报告值得通读,但我特别关注以下图表,它详细展示了不同模型成功完成模拟复杂企业网络攻击的能力:
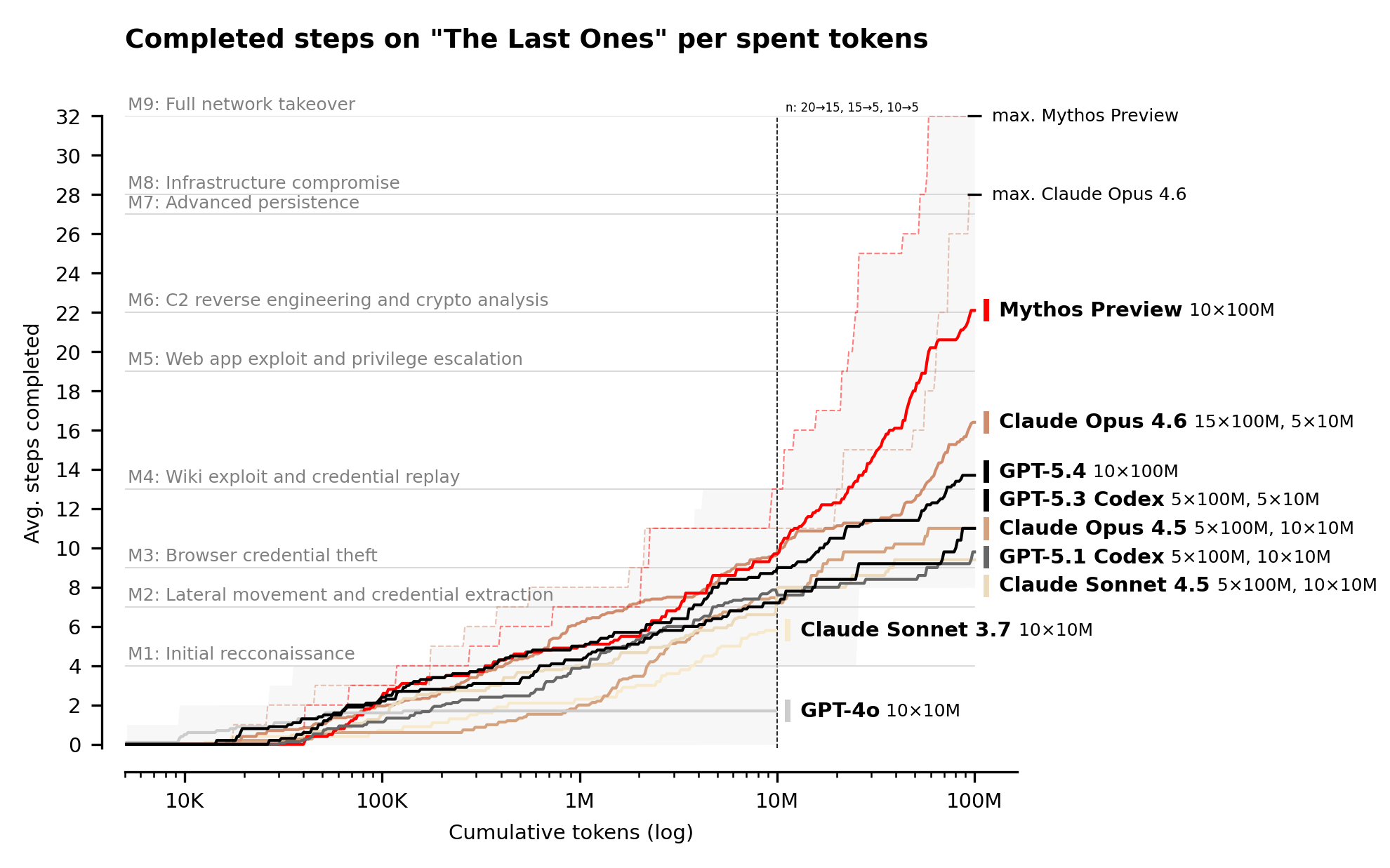
“The Last Ones”是一项包含 32 个步骤的企业网络攻击模拟,涵盖从初始侦察到完全控制网络的整个过程,AISI 估计人类需耗时 20 小时才能完成。图中线条代表多次运行(Mythos、Opus 4.6 和 GPT-5.4 各 10 次)的平均表现,“最大值”线则显示每组中的最佳成绩。Mythos 是唯一一个在 10 次尝试中成功完成任务的模型。
此图揭示了一个有趣的网络安全经济现象:要加固系统,我们必须投入比攻击者更多 tokens 来发现漏洞。
AISI 为每次尝试预算了 1 亿 tokens,即 Mythos 单次尝试成本达 1.25 万美元,十次完整运行总计 12.5 万美元。令人担忧的是,所有模型在 1 亿 tokens 预算下均未出现收益递减迹象。AISI 指出:“随着 token 预算增加,模型持续取得进展。”
如果 Mythos 能持续发现漏洞,只要不断投入资金,那么安全就简化为一个残酷等式:要加固系统,你必须花费比攻击者更多 tokens 来发现漏洞。
这里没有“巧思加分”,胜负只取决于谁投入更多。这类似于加密货币的 工作量证明(PoW)机制——成功与否取决于原始计算量。它更像一场低温彩票:购买 tokens,或许就能找到漏洞。关键在于坚持尝试的时间必须长于攻击者。
这一逻辑带来几个直接启示:
第一,开源软件仍至关重要。
对未接触过 AI 极端主义者的人来说,这句话可能显得荒谬。但近期,在经历 LiteLLM 和 Axios 供应链攻击事件后,许多人主张用编码代理重新实现依赖功能。
几周前,Karpathy 曾如此表示:
传统软件工程认为依赖是好事(就像用砖块建金字塔),但依我看,这一点必须重新评估。正因如此,我对依赖越来越反感,更倾向于在简单可行时,直接用 LLM “截取”(yoink)所需功能。
若安全纯粹取决于向系统投入多少 tokens,那么 Linus 定律——“足够多的眼睛,所有 bug 都将无所遁形”——将扩展为“足够多的 tokens,所有漏洞都将暴露无遗”。若依赖开源库的企业愿意花钱用 tokens 加固这些库,其安全性很可能超出自身预算所能保障的水平。当然,这也带来复杂性:攻破广受欢迎的开源包天然比黑掉一次性实现更具价值,从而激励攻击者加大对 OSS 目标的投入。
第二,加固将成为代理编码流程的独立阶段。
开发者早已将流程拆分为开发、代码审查两个步骤,并常使用不同模型分别处理。随着技术发展,专用工具正契合这一模式。Anthropic 推出了 代码审查 产品,每次审查收费 15–20 美元。
若上述 Mythos 的能力属实,我推测未来将形成三阶段循环:开发、审查、加固。
- 开发:快速实现功能,依赖人类直觉和用户反馈迭代。
- 审查:异步进行文档编写、重构等维护工作,每轮 PR 应用最佳实践。
- 加固:自主识别漏洞,直至预算耗尽。
关键点是:第一阶段受限于人力,最后阶段受限于资金。这种本质差异决定了它们必须是独立阶段(为何在未开发前就花钱加固?)。过去安全审计罕见、零散且不一致;如今我们可在最优(希望如此!)预算内持续实施。
代码本身依然廉价,除非它需要安全。即便推理优化使成本下降,除非模型出现安全收益递减,否则你仍需购买比攻击者更多的 tokens。漏洞的市场价值决定了成本上限。