内容
今天,我们全新系列模型 DeepSeek-V4 的预览版本正式上线并同步开源。
DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。模型按大小分为两个版本:

即日起登录官网 chat.deepseek.com 或官方App , 即可与最新的 DeepSeek-V4 对话,探索 1M 超长上下文记忆的全新体验。API 服务已同步更新,通过修改 model_name 为 deepseek-v4-pro 或 deepseek-v4-flash 即可调用。
DeepSeek-V4-Pro:性能比肩顶级闭源模型
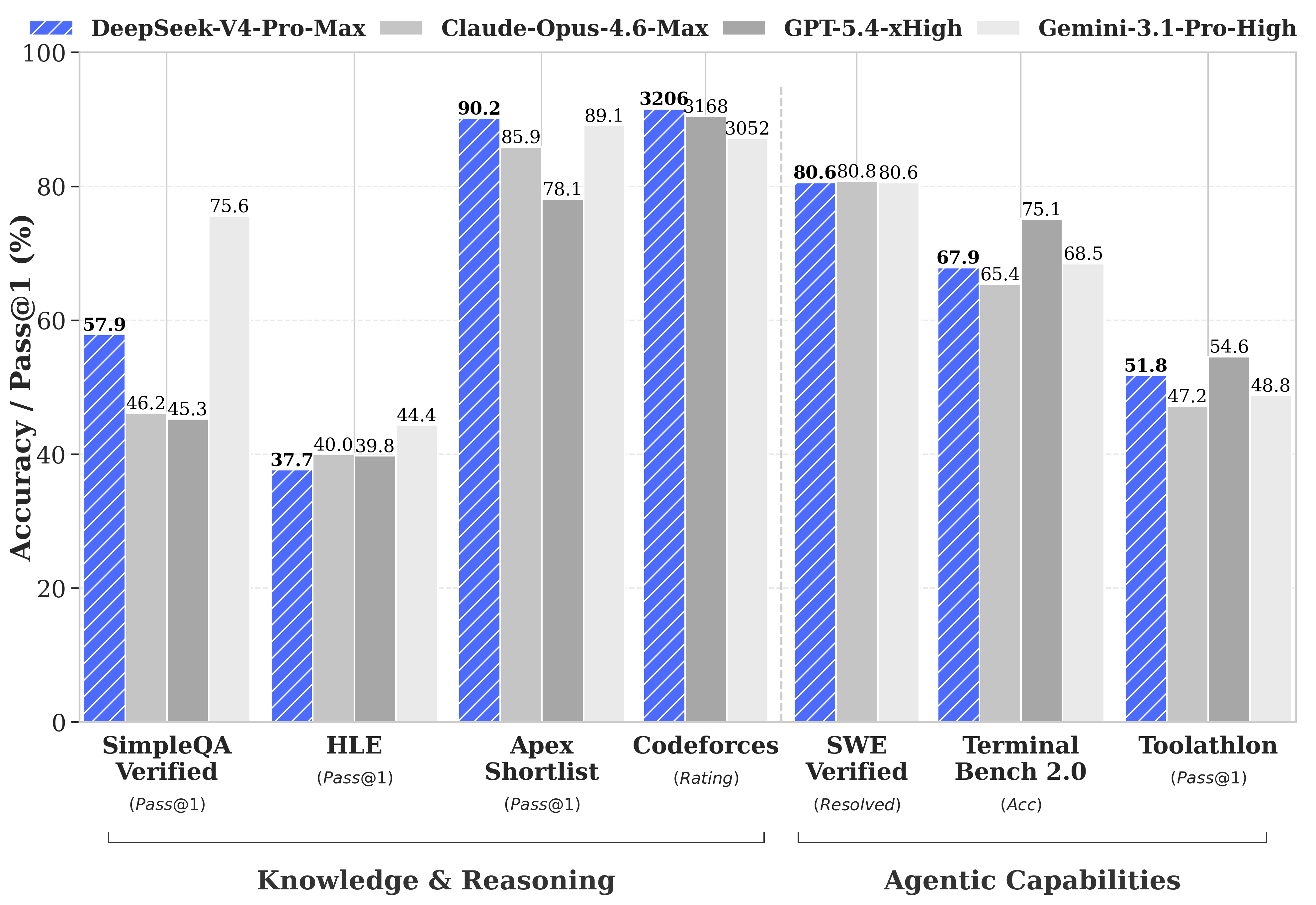
- Agent 能力大幅提高: 相比前代模型,DeepSeek-V4-Pro 的 Agent 能力显著增强。在 Agentic Coding 评测中,V4-Pro 已达到当前开源模型最佳水平,并在其他 Agent 相关评测中同样表现优异。目前 DeepSeek-V4 已成为公司内部员工使用的 Agentic Coding 模型,据评测反馈使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在一定差距。
- 丰富的世界知识: DeepSeek-V4-Pro 在世界知识测评中,大幅领先其他开源模型,仅稍逊于顶尖闭源模型 Gemini-Pro-3.1。
- 世界顶级推理性能: 在数学、STEM、竞赛型代码的测评中,DeepSeek-V4-Pro 超越当前所有已公开评测的开源模型,取得了比肩世界顶级闭源模型的优异成绩。
DeepSeek-V4-Flash:更快捷高效的经济之选
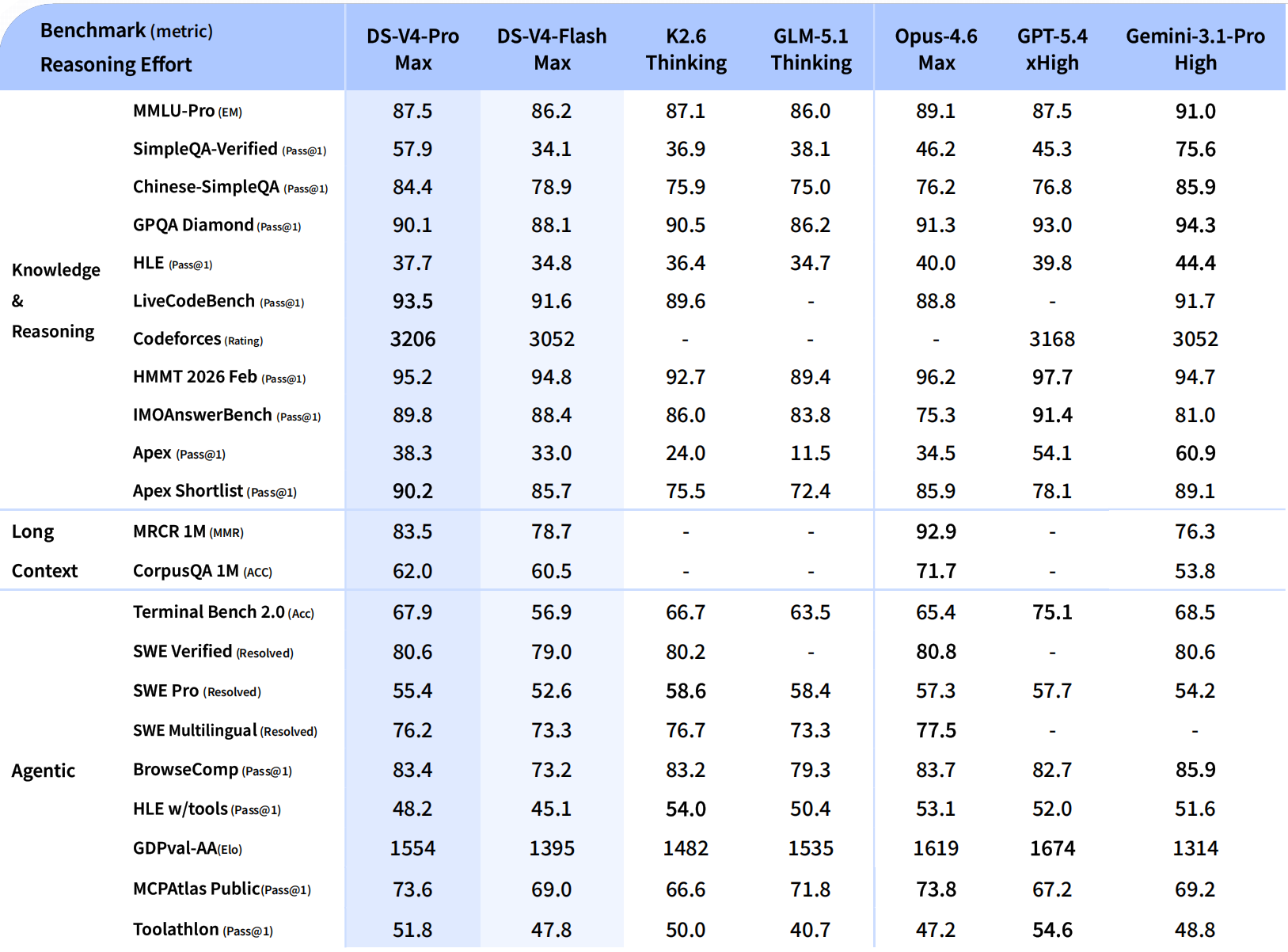
- 相比 DeepSeek-V4-Pro,DeepSeek-V4-Flash 在世界知识储备方面稍逊一筹,但展现出了接近的推理能力。而由于模型参数和激活更小,相较之下 V4-Flash 能够提供更加快捷、经济的 API 服务。
- 在 Agent 测评中,DeepSeek-V4-Flash 在简单任务上与 DeepSeek-V4-Pro 旗鼓相当,但在高难度任务上仍有差距。
结构创新和超高上下文效率
DeepSeek-V4 开创了一种全新的注意力机制,在 token 维度进行压缩,结合 DSA 稀疏注意力(DeepSeek Sparse Attention),实现了全球领先的长上下文能力,并且相比于传统方法大幅降低了对计算和显存的需求。 从现在开始,1M(一百万)上下文将是 DeepSeek 所有官方服务的标配。
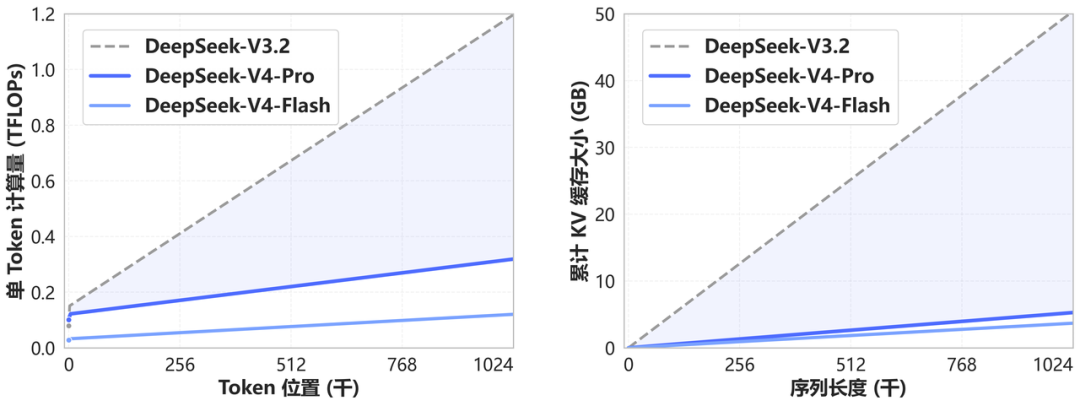
DeepSeek-V4 和 DeepSeek-V3.2 的计算量和显存容量随上下文长度的变化
Agent 能力专项优化
DeepSeek-V4 针对 Claude Code 、OpenClaw、OpenCode、CodeBuddy 等主流的 Agent 产品进行了适配和优化,在代码任务、文档生成任务等方面表现均有提升。下图为 V4-Pro 在某 Agent 框架下生成的 PPT 内页示例:
API 访问
目前, DeepSeek API 已同步上线 V4-Pro 与 V4-Flash ,支持 OpenAI ChatCompletions 接口与 Anthropic 接口。访问新模型时,base_url 不变, model 参数需要改为 deepseek-v4-pro 或 deepseek-v4-flash 。
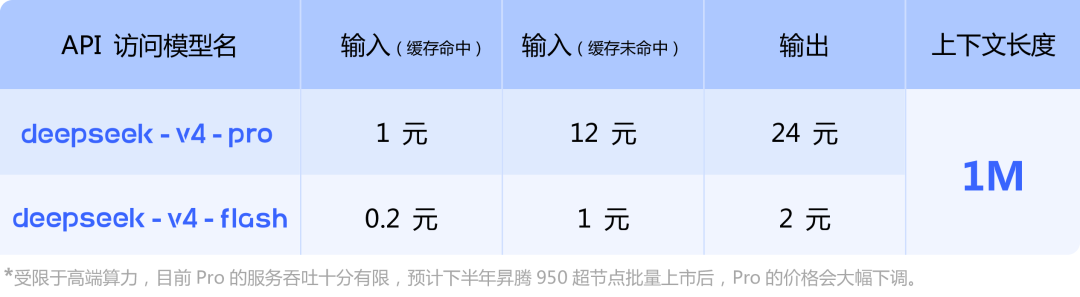
V4-Pro 与 V4-Flash 最大上下文长度为 1M , 均同时支持 非思考模式 与 思考****模式 ,其中思考模式支持 reasoning_effort 参数设置思考强度(high/max)。对于复杂的 Agent 场景建议使用思考模式,并设置强度为 max。模型调用与参数调整方法请参考 API 文档:
https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
请大家注意:旧有的 API 接口的两个模型名 deepseek-chat 与deepseek-reasoner 将于三个月后( 2026-07-24 )停止使用。当前阶段内,这两个模型名分别指向 deepseek-v4-flash 的非思考模式与思考模式 。
开源权重和本地部署
- DeepSeek-V4 模型开源链接:
https://huggingface.co/collections/deepseek-v4
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
- DeepSeek-V4 技术报告:
.https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
写在后面的话
「不诱于誉,不恐于诽,率道而行,端然正己。」
感谢每一位用户的信任与支持,大家的肯定、建议和期许,是我们不竭探索、持续进步的动力,也让我们始终坚守初心,专注于不懈的创新。
我们将始终秉持长期主义的原则理念,在尝试与思考中踏实前行,努力向实现 AGI 的目标不断靠近。