内容
GLM-5.1 是我们面向智能体工程(agentic engineering)的下一代旗舰模型,其编码能力较前代显著增强。它在 SWE-Bench Pro 上达到当前最优(state-of-the-art)表现,并在 NL2Repo(仓库生成)和 Terminal-Bench 2.0(真实世界终端任务)上大幅领先 GLM-5。
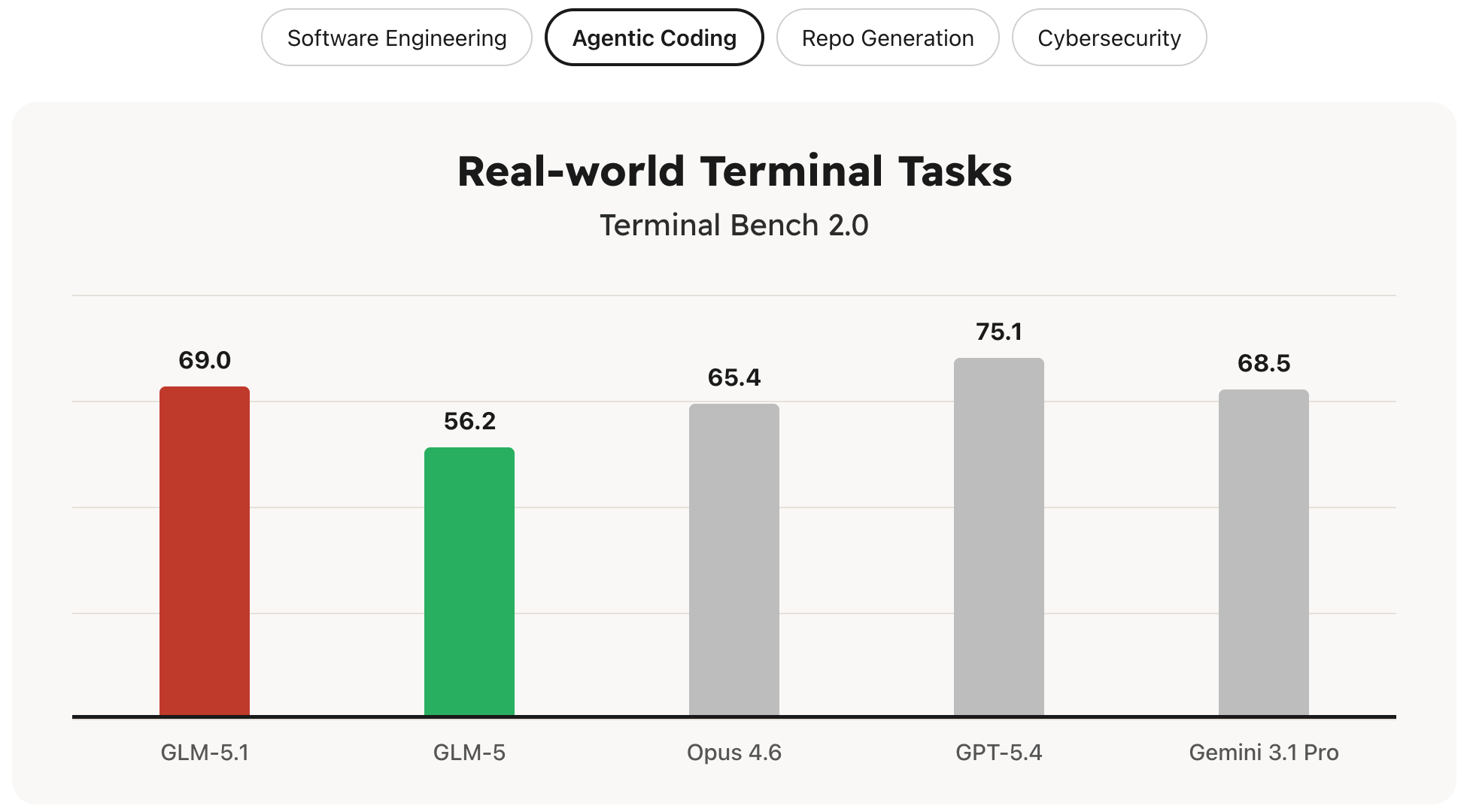
GLM-5.1 在复杂软件工程任务上达到了当前最优表现。
但更有意义的飞跃,并不止于首轮表现。以往的模型——包括 GLM-5——往往会很快耗尽其“招数库”:它们先用熟悉的方法迅速取得初步收益,随后便陷入平台期。即使给它们更多时间,也无济于事。
相比之下,GLM-5.1 从设计上就能够在更长时间跨度内,持续高效地处理智能体任务。我们发现,这个模型在面对模糊问题时判断力更强,也能在更长会话中保持生产力。它能够拆解复杂问题、运行实验、读取结果,并且非常精准地识别阻塞点。通过反复迭代,不断回看自身推理并修正策略,GLM-5.1 可以在数百轮、数千次工具调用中持续优化。运行得越久,结果往往越好。
我们通过三类任务展示这一点,这些任务的反馈结构依次变得更弱:一个仅以单一数值指标评分的向量检索优化问题;一个按单题加速比衡量的 GPU 内核基准;以及一个完全开放式的 Web 应用构建任务,在这里根本没有指标可供优化——只有模型自己判断下一步该改进什么。
场景 1:在 600 次迭代中优化向量数据库
VectorDBBench 是一个开源编码挑战,用于评估模型构建高性能数据库以执行近似最近邻搜索(approximate nearest neighbor search)的能力。模型会获得一个 Rust 骨架工程,其中包含 HTTP API 端点和空的实现桩,然后通过基于工具调用的智能体读取和写入文件、编译、测试、性能分析——这一切都必须在 50 轮工具调用预算内完成。最终结果会在 SIFT-1M 数据集上进行基准测试:在 Recall ≥ 95% 的约束下,模型按 QPS 排名。在这一设定下,迄今最佳结果为 3,547 QPS,由 Claude Opus 4.6 取得。
一个很自然的问题是:50 轮预算是否就是瓶颈?我们使用 Claude Code 框架,将评测重构为一个外层优化循环:在每次迭代中,模型可以根据需要使用任意数量的工具调用来编辑代码、编译、测试和分析性能,然后提交一个新版本进行基准测试。模型会自主决定何时提交,以及下一步尝试什么。
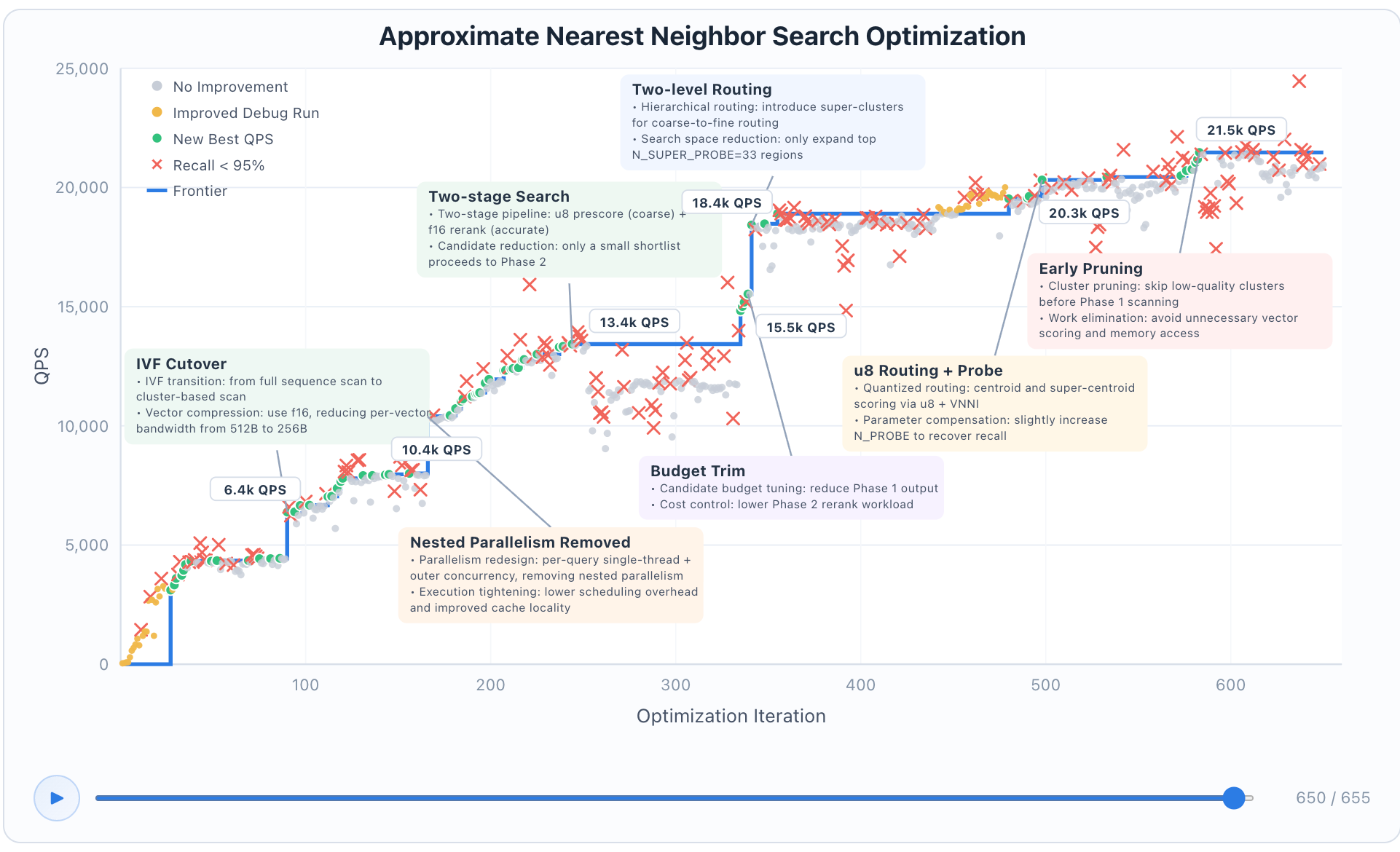
GLM-5.1 并没有在 50 次或 100 次提交后进入平台期,而是在 600+ 次迭代、6,000+ 次工具调用中持续发现有意义的改进,最终达到 21.5k QPS——大约是单次 50 轮会话下最佳结果的 6 倍。其优化轨迹呈现出典型的“阶梯状”模式:在固定策略内先经历一段渐进调优期,然后通过结构性变化将性能前沿整体推高。
其中有两次转变尤其能说明这一模式。大约在第 90 次迭代时,模型从全量语料扫描切换到带 f16 向量压缩的 IVF 聚类探测,QPS 跃升至 6.4k。大约在第 240 次迭代时,它引入了一个两阶段流水线——先用 u8 进行预评分,再用 f16 重新排序,QPS 提升到 13.4k。整个运行过程中一共发生了 6 次这样的结构性转变,每一次都是模型在分析自身基准日志、识别当前瓶颈之后主动发起的。图表中的红色叉号标记了 Recall 低于 95% 的迭代——这些点大多集中在每次重大转变附近,因为模型在探索新方向时会暂时打破约束,随后再调整回来以恢复约束。
场景 2:在 1,000+ 轮中优化机器学习工作负载
KernelBench 用于评估模型是否能够基于参考 PyTorch 实现,产出一个输出完全一致但更快的 GPU 内核。该基准分为三个层级,优化范围和系统复杂度逐级提升:Level 1 涵盖单个算子,Level 2 涵盖融合算子序列,Level 3 则涵盖完整架构(如 MobileNet、VGG、MiniGPT 和 Mamba)的端到端全模型优化,共计 50 个问题。作为参考,默认设置下的 torch.compile 在这些问题上可实现 1.15× 加速;启用 max-autotune 后可达 1.49×。我们在 Level 3 上测试了四个模型,并报告其在全部 50 个问题上的几何平均加速比,横轴为工具使用轮数。
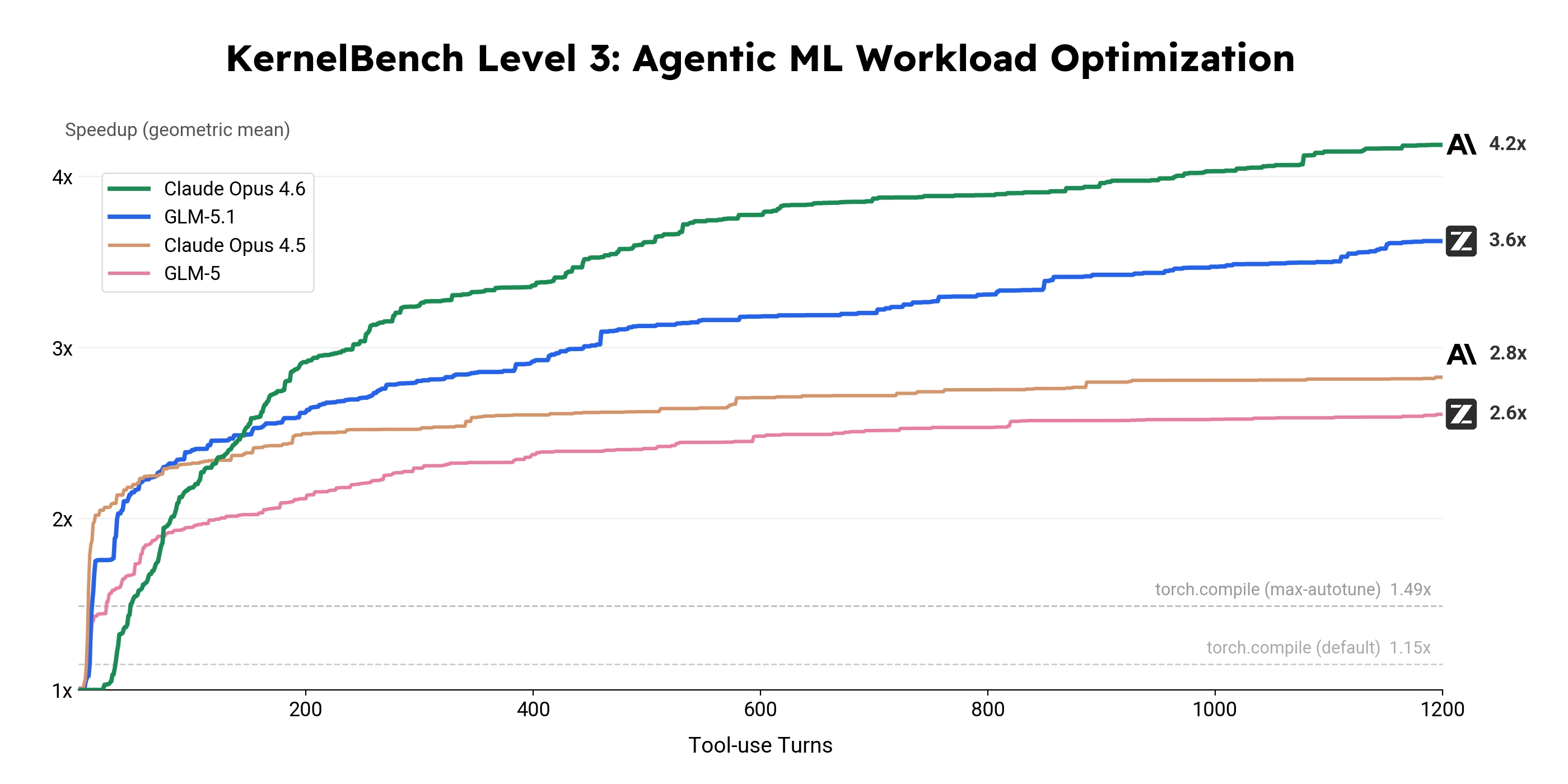
这些轨迹凸显了模型在长周期优化行为上的差异。GLM-5 起初提升很快,但相对较早就趋于平缓。Claude Opus 4.5 能再持续一段时间,但在后期收益也开始减弱。GLM-5.1 则把这一前沿进一步向前推进,实现了 3.6× 加速,并且在运行相当后期时仍持续取得进展。虽然它的改进速率也会随着时间推移而放缓,但相比 GLM-5,它能在明显更长的时间里保持有效优化。Claude Opus 4.6 仍然是这一设定下最强的模型,最终达到 4.2×,且在结束时依然显示出进一步提升空间。
场景 3:用 8 小时构建一个 Linux 桌面
前两个场景都有明确的数值目标——QPS、加速比——模型可以据此进行基准比较。而网站生成本质上更具主观性:给定一段自然语言提示,生成一个可用的 Web 应用。这里没有单一指标可供优化;“好”的标准取决于功能完整度、视觉打磨程度以及交互质量。
我们用一个刻意设定得颇具挑战性的提示词来测试这一点:构建一个 Linux 风格的桌面环境 Web 应用。没有起始代码,没有设计稿,也没有中间指导。在单次运行中,大多数模型——包括更早版本的 GLM——都会很快“放弃”:它们只生成一个基础骨架,带静态任务栏和一两个占位窗口,然后就宣布任务完成。模型本身没有机制停下来反思:到底还缺了什么?
我们为 GLM-5.1 包装了一个简单的执行框架,改变了这一点:每轮执行后,模型会回看自己的输出,识别可改进之处——缺失功能、粗糙样式、失效交互——然后继续推进。这个循环持续运行了 8 小时,差异非常明显。
在早期,GLM-5.1 先交付了一个基础布局,包含任务栏和简单窗口——这与短会话通常会生成的结果相似。但它并没有停在那里。随着持续迭代,整个系统逐步丰富起来:文件浏览器、终端、文本编辑器、系统监视器、计算器、游戏——每个新增模块都被整合进一个连贯统一的 UI 中,而不是事后生硬拼接。样式更加精致,交互更加顺滑,边界情况也得到了处理。到最后,结果已经是一个完整、视觉风格一致、可在浏览器中运行的桌面环境——这清楚地说明了:当模型同时拥有足够时间和持续改进的能力时,会产生怎样的可能性。
在这三种设定中,关键变量不只是运行时间本身,而是额外的运行时间是否仍然有价值。GLM-5.1 将这种“有效工作时长”显著延伸到了 GLM-5 之上;而像 KernelBench 这类任务上的剩余差距也表明,长周期优化仍然是一个尚待开拓的前沿领域。这里仍有许多重要挑战:当渐进调优不再奏效时,如何更早跳出局部最优;如何在跨越数千次工具调用的执行轨迹中保持一致性;以及——也许最重要的是——如何为那些没有数值指标可优化的任务建立可靠的自我评估能力。GLM-5.1 是我们朝这个方向迈出的第一步,我们也将继续在这些方面推进。
| 基准 | GLM-5.1 | GLM-5 | Qwen3.6-Plus | MiniMax M2.7 | DeepSeek-V3.2 | Kimi K2.5 | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|---|---|---|---|---|
| 推理 | |||||||||
| HLE | 31.0 | 30.5 | 28.8 | 28.0 | 25.1 | 31.5 | 36.7 | 45.0 | 39.8 |
| HLE w/ Tools | 52.3 | 50.4 | 50.6 | - | 40.8 | 51.8 | 53.1* | 51.4* | 52.1* |
| AIME 2026 | 95.3 | 95.4 | 95.1 | 89.8 | 95.1 | 94.5 | 95.6 | 98.2 | 98.7 |
| HMMT 2025 年 11 月 | 94.0 | 96.9 | 94.6 | 81.0 | 90.2 | 91.1 | 96.3 | 94.8 | 95.8 |
| HMMT 2026 年 2 月 | 82.6 | 82.8 | 87.8 | 72.7 | 79.9 | 81.3 | 84.3 | 87.3 | 91.8 |
| IMOAnswerBench | 83.8 | 82.5 | 83.8 | 66.3 | 78.3 | 81.8 | 75.3 | 81.0 | 91.4 |
| GPQA-Diamond | 86.2 | 86.0 | 90.4 | 87.0 | 82.4 | 87.6 | 91.3 | 94.3 | 92.0 |
| 编码 | |||||||||
| SWE-Bench Pro | 58.4 | 55.1 | 56.6 | 56.2 | - | 53.8 | 57.3 | 54.2 | 57.7 |
| NL2Repo | 42.7 | 35.9 | 37.9 | 39.8 | - | 32.0 | 49.8 | 33.4 | 41.3 |
| Terminal-Bench 2.0 Terminus-2 | 63.5 | 56.2 | 61.6 | - | 39.3 | 50.8 | 65.4 | 68.5 | - |
| Terminal-Bench 2.0 最佳自报 harness | 66.5 (Claude Code) | 56.2 (Claude Code) | - | 57.0 (Claude Code) | 46.4 (Claude Code) | - | - | - | 75.1 (Codex) |
| CyberGym | 68.7 | 48.3 | - | - | 17.3 | 41.3 | 66.6 | - | - |
| 智能体 | |||||||||
| BrowseComp | 68.0 | 62.0 | - | - | 51.4 | 60.6 | - | - | - |
| BrowseComp w/ Context Manage | 79.3 | 75.9 | - | - | 67.6 | 74.9 | 84.0 | 85.9 | 82.7 |
| 𝜏³-Bench | 70.6 | 69.2 | 70.7 | 67.6 | 69.2 | 66.0 | 72.4 | 67.1 | 72.9 |
| MCP-Atlas Public Set | 71.8 | 69.2 | 74.1 | 48.8 | 62.2 | 63.8 | 73.8 | 69.2 | 67.2 |
| Tool-Decathlon | 40.7 | 38.0 | 39.8 | 46.3 | 35.2 | 27.8 | 47.2 | 48.8 | 54.6 |
| Vending Bench 2 | $5,634.00 | $4,432.12 | $5,114.87 | - | $1,034.00 | $1,198.46 | $8,017.59 | $911.21 | $6,144.18 |
GLM-5.1 已以 MIT License 开源发布。
GLM-5.1 也已上线开发者平台 api.z.ai 和 BigModel.cn,并兼容 Claude Code 与 OpenClaw。
开始使用 GLM-5.1
在 GLM Coding Plan 中使用 GLM-5.1
在你喜爱的编码智能体中体验 GLM-5.1——包括 Claude Code、OpenCode、Kilo Code、Roo Code、Cline、Droid 等。 https://docs.z.ai/devpack/overview
针对 GLM Coding Plan 订阅用户: 我们正在向所有 Coding Plan 用户逐步推出 GLM-5.1。你现在即可通过将模型名称更新为 "GLM-5.1" 来启用它(例如在 Claude Code 的 ~/.claude/settings.json 中)。作为我们能力最强的模型,GLM-5.1 在高峰时段按 3× 配额消耗计费,在非高峰时段按 2× 计费。作为截至 4 月底的限时优惠,非高峰时段使用按 1× 计费。(高峰时段为每日 UTC+8(北京时间)14:00–18:00)
更喜欢图形界面(GUI)?我们提供 Z Code ——一个界面,多智能体协同工作。你可以通过 SSH 在远程机器上开发,或直接用手机发起任务,稍后再回来查看结果。
立即开始构建: https://z.ai/subscribe
在 Z.ai 上与 GLM-5.1 对话
GLM-5.1 将在未来几天内上线 Z.ai。
本地部署 GLM-5.1
GLM-5.1 的模型权重已在 HuggingFace 和 ModelScope 公开提供。对于本地部署,GLM-5.1 支持包括 vLLM 和 SGLang 在内的推理框架。完整的部署说明可在官方 GitHub 仓库中查看。
注释
-
Humanity’s Last Exam(HLE)及其他推理任务:我们使用最长 163,840 tokens 的生成长度进行评测(
temperature=1.0, top_p=0.95, max_new_tokens=163840)。默认报告纯文本子集;标有 * 的结果来自完整集合。我们使用 GPT-5.2(medium)作为裁判模型。对于 HLE-with-tools,我们使用最长 202,752 tokens 的上下文长度。 -
SWE-Bench Pro:我们使用 OpenHands 和定制指令提示词运行 SWE-Bench Pro 套件。设置为:
temperature=1, top_p=0.95, max_new_tokens=32768,上下文窗口为 200K。 -
NL2Repo:我们在 200k 上下文下,以
temperature=1.0, top_p=1.0, max_new_tokens=32768对 NL2Repo 进行评测。为防止攻击,我们先使用基于规则的预检测识别恶意命令(例如未授权的 pip 或 curl 操作),随后再进行基于模型的判定。一旦发现恶意行为,会立即拦截。 -
BrowserComp:在没有上下文管理时,我们保留最近 5 轮的细节;在使用上下文管理时,我们采用与 GLM-5 和 DeepSeek-v3.2 相同的“全部丢弃”策略。
-
Terminal-Bench 2.0(Terminus 2):我们使用 Terminus 框架进行评测,设置为
timeout=3h, temperature=1.0, top_p=1.0, max_new_tokens=8192,上下文窗口为 200K。资源上限为 16 个 CPU 和 32 GB RAM。 -
Terminal-Bench 2.0(Claude Code):我们在 Claude Code 2.1.14(think mode)中进行评测,设置为
temperature=1.0, top_p=0.95, max_new_tokens=131072。我们移除了墙钟时间限制,同时保留每个任务的 CPU 和内存约束。我们修复了 Claude Code 引入的环境问题,并同时报告在已验证的 Terminal-Bench 2.0 数据集上的结果,该数据集解决了模糊指令问题(见:https://huggingface.co/datasets/zai-org/terminal-bench-2-verified)。分数为 5 次运行的平均值。 -
CyberGym:我们在 Claude Code 2.1.56(think mode,不启用 web 工具)中进行评测,设置为(
temperature=1.0, top_p=1.0, max_new_tokens=32000),每个任务超时为 250 分钟。结果为 1,507 个任务上的单次运行 Pass@1。 -
MCP-Atlas:所有模型均在 think mode 下,于包含 500 个任务的公开子集上进行评测,每个任务超时 10 分钟。我们使用 Gemini-3.0-Pro 作为评测裁判模型。
-
τ³-bench:我们在所有领域的用户模拟器中额外加入了一段提示词,以避免用户过早结束交互所导致的失败模式。银行领域使用基于终端的智能体搜索检索(terminal_use)。用户模拟器:GPT-5.2(
reasoning_effort: low),4 次试验。 -
Vending Bench 2:运行由 Andon Labs 独立执行。
-
KernelBench Level 3:50 个问题中的每一个都在隔离的 Docker 容器中运行,使用 1 张 H100 GPU,并限制为最多 1200 轮工具使用。正确性(
atol=rtol=1e-4)和性能在独立的 CUDA 上下文中,针对 PyTorch eager 基线分别评估。所有解法都由 Claude Opus 4.6(max effort)和 GPT-5.4(xhigh)独立审计,以检查是否存在基准利用行为:每次审计都会验证该优化未利用基准特定行为、能够适用于任意新的输入,并确保所有计算都在默认 CUDA 流上执行。最终采用各次审计中较低的加速比,并设置 50× 的硬上限,以限制异常值的影响。