一个数据中心拥有多少算力?
内容
每天都会冒出一些关于建设 AI 数据中心所需巨额投资的新报道。《华尔街日报》报道称,如果按 GDP 占比来算,仅 2026 年一年的 AI 资本支出,就将超过当年美国在长达十年的全国铁路系统建设、联邦政府打造州际高速公路系统的支出,或整个阿波罗计划的总投入。彭博社报道,AI 数据中心支出最高可能达到 3 万亿美元。电力研究院(Electric Power Research Institute)预测,到 2030 年,数据中心将消耗美国全部电力的最高 17%。
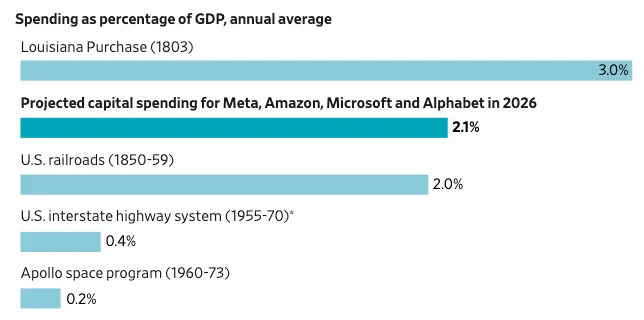
但如果只用花了多少钱、耗了多少电来谈论数据中心,多少还是有些抽象:它并不能像“铺了多少英里铁轨”或“修了多少英里公路”那样,让我们直观理解我们实际正在建设的基础设施究竟具备怎样的能力,或者说其规模到底有多大。我想更清楚地了解一下,这轮数据中心建设如果换算成计算能力,究竟是什么样子。
AI 与计算
推动 AI 数据中心建设热潮的最大因素,毫无疑问是缩放定律(scaling laws)。简单来说,用于训练 AI 模型的数据越多,模型本身越大、计算开销越高,模型表现通常就越好。因此,要打造更好、更强大的 AI 模型,就需要越来越多的计算资源来进行训练和运行,而数据中心正是这些计算发生的地方。
衡量 AI 模型计算能力的一个常见指标是 FLOPS,即每秒浮点运算次数(floating-point operations per second)。据估计,OpenAI 的 GPT-2 模型训练耗费了 2.3x10^21 FLOP,而更先进的 GPT-4 则约为 2.1x10^25 FLOP——计算量几乎是 GPT-2 的 1 万倍,超过 2 千万万亿次运算。
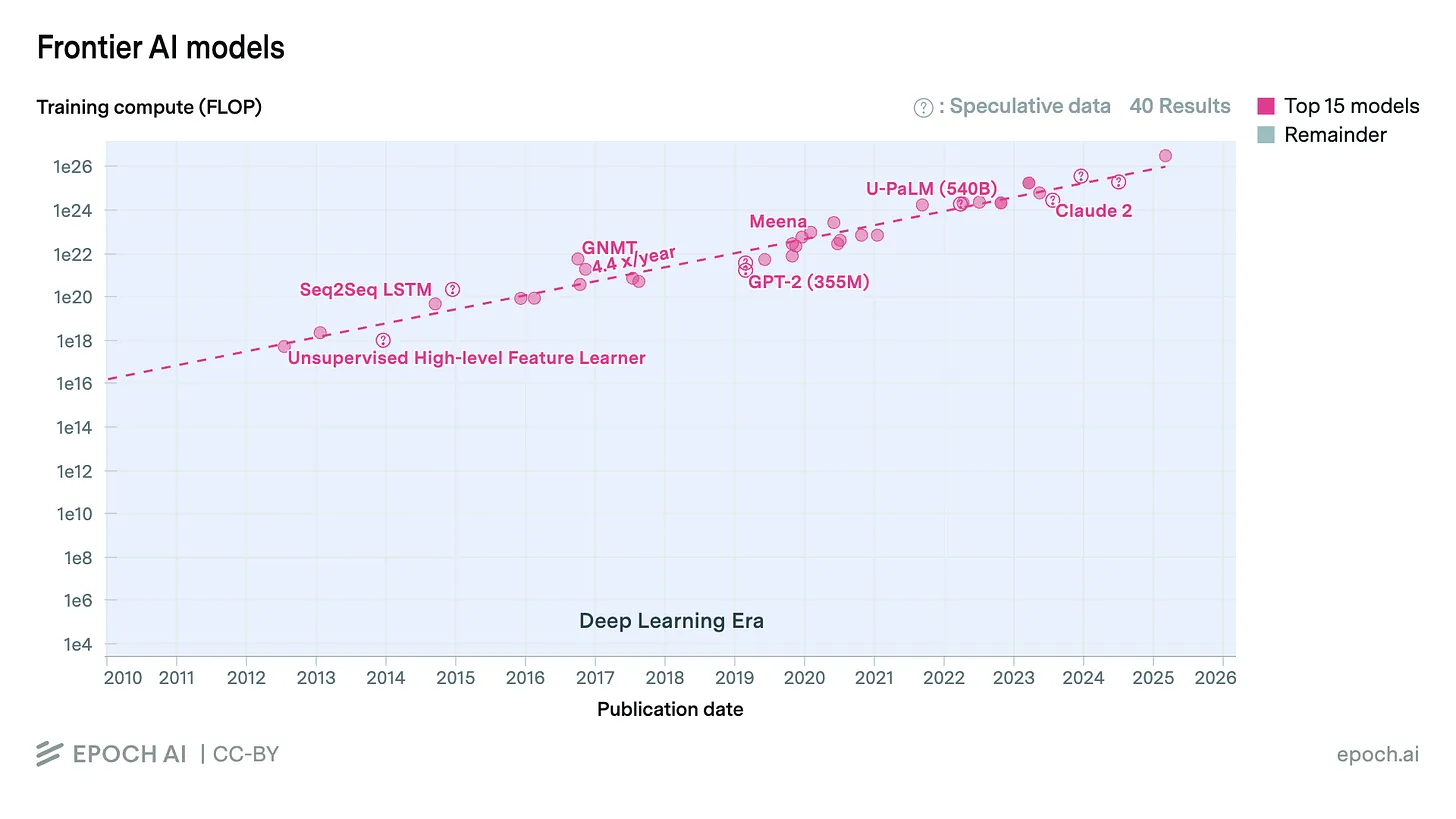
(当然,计算机性能远不止 FLOPS 这一个维度,但它依然是衡量计算能力的一个实用指标,本文也将以它为主。)
所谓浮点运算,顾名思义,就是对浮点数执行数学运算(加、减、乘、除)。浮点数是一种在计算机中以数字方式表示分数或小数的方法,而计算机内部的一切最终都以 0 和 1 的序列来存储。浮点数通常由三部分组成:符号位(sign)(表示正负)、有效数(significand)(某串数字),再乘以一个以指数形式表示的基数幂(base raised to an exponent,用于确定小数点位置)。
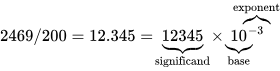
不同的浮点数编码标准,在给定的内存空间下,会为这几个部分分配不同的位数。比如,IEEE 754 浮点运算标准规定,32 位浮点数(通常是通用计算机中使用的浮点数规格)包含 1 位符号位、8 位指数位和 23 位有效数字段。由于可用空间有限,浮点运算的精度在根本上也是有限的:分配的空间越少,数值精度就越低。16 位浮点数的精度低于 32 位,32 位又低于 64 位。(这一点后面会变得很重要。)

那么,一个典型的 AI 数据中心究竟能达到多少 FLOPS 呢?
数据中心中的计算,是通过大量图形处理器(GPU)完成的。GPU 是专门设计来同时执行大量算术运算的专用计算设备。(GPU 最初是为渲染图形而设计的,比如电脑游戏中的图形渲染,而多年以来,英伟达(Nvidia)主要也是一家电脑游戏显卡制造商。)一种常见的 GPU 是 Nvidia 的 H100,它于 2022 年首次发布,至今仍是最受欢迎的 AI 计算 GPU 之一。对数据中心容量的估算,往往会以“H100 等效(H100 equivalents)”来表示。根据 Epoch AI 的大型 GPU 集群数据集,一个典型的 AI 数据中心大约拥有 10 万个 H100 等效,而特别大的数据中心则可能达到 100 万个甚至更多。Meta 计划在路易斯安那州建设的5 吉瓦数据中心园区,在完工后预计将拥有超过 400 万个 H100 等效。
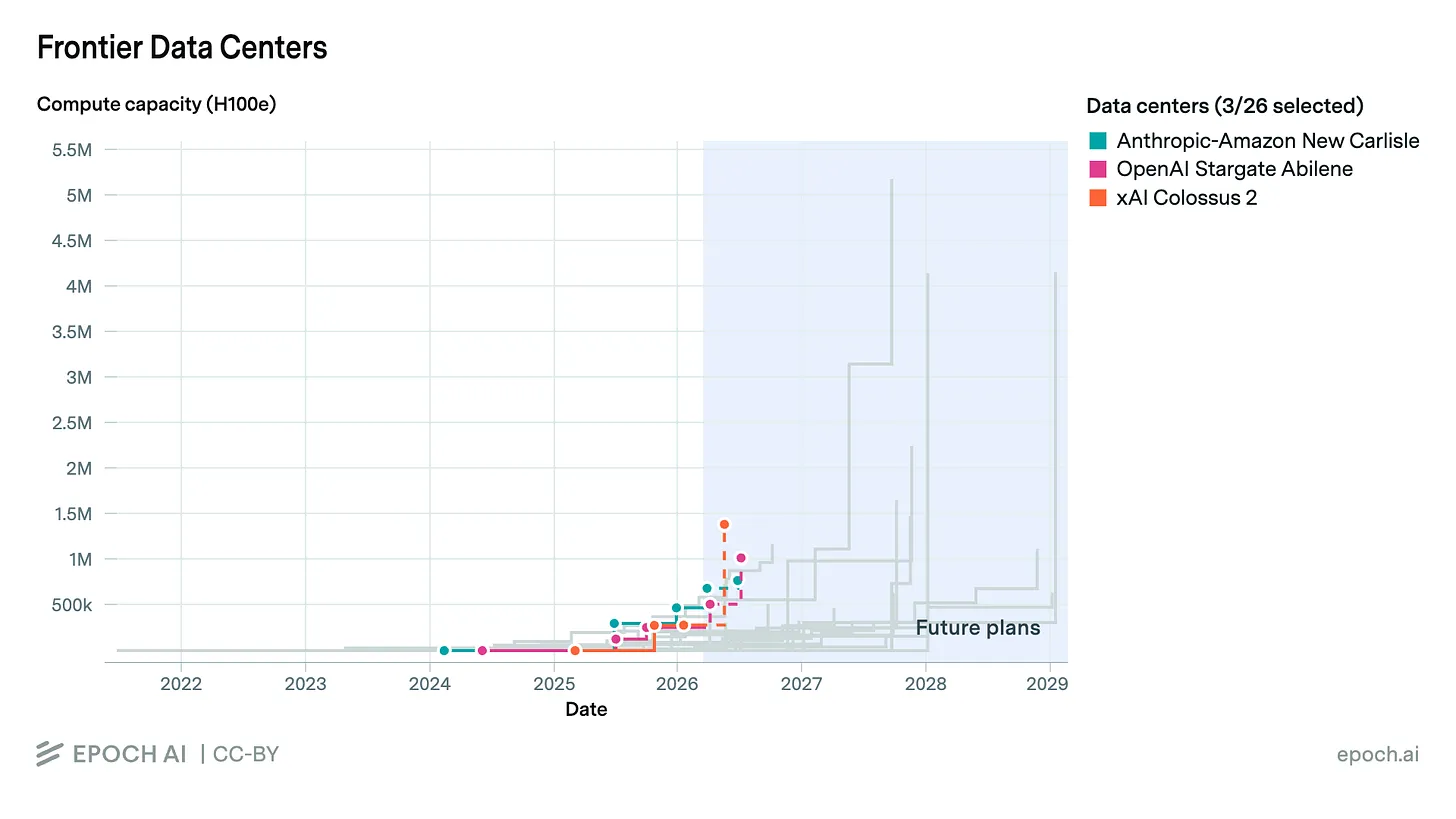
那么,H100 的计算能力到底有多强?
这里开始变得复杂起来。像 H100 这样面向 AI 任务设计的 GPU,可以在更低精度数字上执行更多计算。对于常见的 32 位浮点数(FP32),H100 依据配置不同可达到 60–67 teraFLOPS:最高可达 67 x 10^12,也就是每秒 67 万亿次浮点运算。而使用 16 位数字(FP16)时,H100 可达到 1,979 teraFLOPS,提升接近 30 倍。使用 8 位浮点数(FP8)时,这一数字还可以再翻倍,达到 3,958 teraFLOPS。
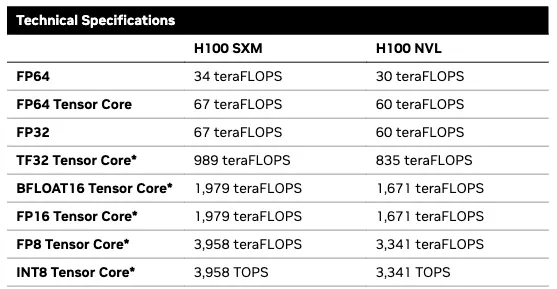
不过,除了 FP32 和 FP64 之外,这些性能水平都依赖一种叫做 稀疏性(sparsity) 的机制。所谓稀疏性,是指矩阵中每四个值组成的一组里,至少有两个是零。在这种情况下,GPU 可以跳过对零值的乘法运算,相当于把必须执行的运算次数减半。如果矩阵不是稀疏的(也就是稠密的),那么标称性能大约会下降一半。
在训练 AI 模型时,稀疏性基本上几乎无法实现;而在运行模型时可以做到,但要利用这一点,通常还需要对模型进行一个额外步骤,即剪枝(pruning)。因此,H100 公布的这些性能指标,实际上只有在特定情况下才能达到。
大多数通用计算通常使用精度更高的 FP32 浮点数。但在训练和运行 AI 模型时,人们发现使用 16 位、8 位,甚至 4 位浮点数,也可以取得不错的效果。
那么,H100 的计算能力和其他类型的计算机相比如何?比如说,和一部 iPhone 相比呢?
iPhone 16 使用苹果的 A18 芯片,Pro 版本配备六核 GPU。对 A18 计算 能力的估算有所不同,但看起来其 FP32 性能大致在 2–3 teraFLOPS 量级,FP16 下可能约为这一数值的两倍。A18 还配备了一颗 16 核神经处理单元(NPU),可实现每秒 35 万亿次运算(TOPS),使用的似乎是 8 位整数(INT8)。相比之下,H100 在 INT8 且启用稀疏性的情况下,最高可达到 3,958 TOPS,提升了 113 倍。(A18 当然也有 CPU,但它在总计算能力上的增量似乎可以忽略不计。)
把这些放在一起看:在进行 32 位浮点运算时,H100 的计算能力约为 iPhone 16 GPU 的 20–30 倍;而在处理 16 位数字时,则约为其 137–275 倍(取决于是否启用稀疏性)。与此同时,H100 的能力约为 A18 NPU 的 56–113 倍。如果我们假设 NPU 和 GPU 都可以同时使用,那么 H100 的计算能力大致相当于 50–100 部 iPhone 16。1 一个拥有 10 万个 H100 等效的典型 AI 数据中心,大致相当于 500 万到 1000 万部 iPhone 16;而一个庞然大物般的 5 GW 数据中心,则大致相当于 2 亿到 4 亿(!)部 iPhone 16。
当然,在现实中,你不可能通过把一堆 iPhone 连起来,就获得接近 H100 的性能;H100 的设计目标就是与成千上万块其他 H100 互联,并且拥有巨大的互连带宽和内存带宽来支撑这一点,而 iPhone 并不具备这些条件。但这个比较至少能帮助我们对其中涉及的计算能力规模形成一个粗略的概念。