内容
能力创造者现在可以帮助你写评估、运行基准测试和确保你的技能在模型演进中持续工作。这些更新现在可在Claude.ai和Cowork中找到,作为Claude Code的插件,以及在我们的仓库中。
自从推出Agent技能以来,我们注意到大多数作者都是领域专家,而不是工程师。他们了解自己的工作流程,但没有工具来确定技能是否仍然与新模型兼容、是否在适当时触发、以及是否在编辑后是否真正改善。
今天,我们宣布了能力创造者增强功能,帮助作者以更大的信心进行创作。我们将软件开发中的严谨性(测试、基准测试、迭代改进)带到了技能创作中,而不需要任何人编写代码。
两种类型的技能
技能通常分为两类:
能力提升技能帮助Claude完成基准模型无法完成或无法一致完成的任务。我们的文档创建技能是很好的例子。它们编码了生产比仅靠提示更好的输出的技术和模式。
编码偏好技能记录了Claude可以完成每个部分,但技能按您的团队的流程排列的工作流程。例如:技能可以按照特定标准检查NDA审查流程,或者技能可以根据来自各种MCP的数据编写每周更新。
这个区别很重要,因为这两种类型的技能可能需要测试的原因不同:
- 能力提升技能可能随着模型的改进而变得不再必要。评估告诉你何时发生了这种情况。
- 编码偏好技能更具持久性,但只有当它们对您的实际工作流程的忠诚度足够高时才有价值。评估验证了这一忠诚度。
无论哪种情况,测试都将一个似乎有效的技能转变为一个已知有效的技能。
使用评估测试和改进技能
能力创造者现在可以帮助你写评估,这些评估检查Claude是否按照你的期望处理特定提示。如果你编写过软件测试,这会感觉很熟悉:定义一些测试提示(如果需要,还包括文件),描述什么是好的,能力创造者就会告诉你技能是否有效。
我们的PDF技能以前在处理非填充表单时遇到困难。Claude需要在没有定义任何指引的精确坐标上放置文本。评估隔离了失败,我们推出了一个修复方案,通过将定位与提取文本坐标进行锚定。
评估有很多用途,但两个重要的用途是捕捉质量回归和了解模型进展。
首先,捕捉质量回归。随着模型和围绕它们的基础设施演进,一个在上个月有效的技能可能在今天表现不同。运行评估对新模型会给你一个早期信号,告诉你什么时候会发生变化,何时会影响你的团队的工作。
其次,了解模型通用能力是否已经超越了你的技能。这主要适用于能力提升技能。如果基准模型在不加载技能的情况下通过你的评估,那么这意味着技能的技术可能已经被模型的默认行为所包含。技能并没有破裂;它只是不再必要了。
我们还添加了一个基准测试模式,使用你的评估进行标准化评估。这是你可以在模型更新后或在技能自身迭代时运行的东西。它跟踪评估通过率、耗时和令牌使用情况。
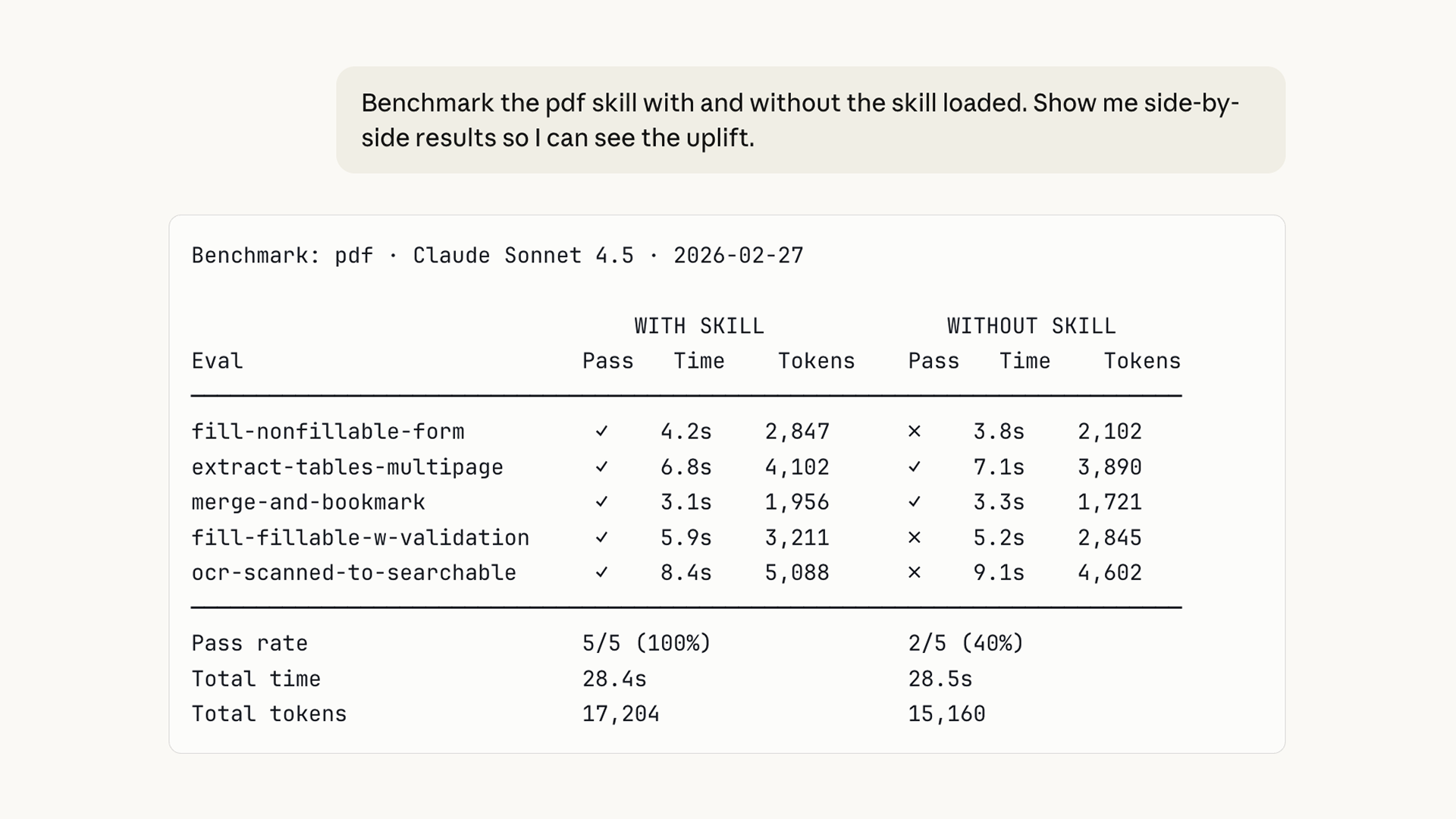
你的评估和结果都属于你。将它们存储在本地,整合到仪表板中,或者将它们插入CI系统中。
使用多代理支持进行更快、更一致的评估
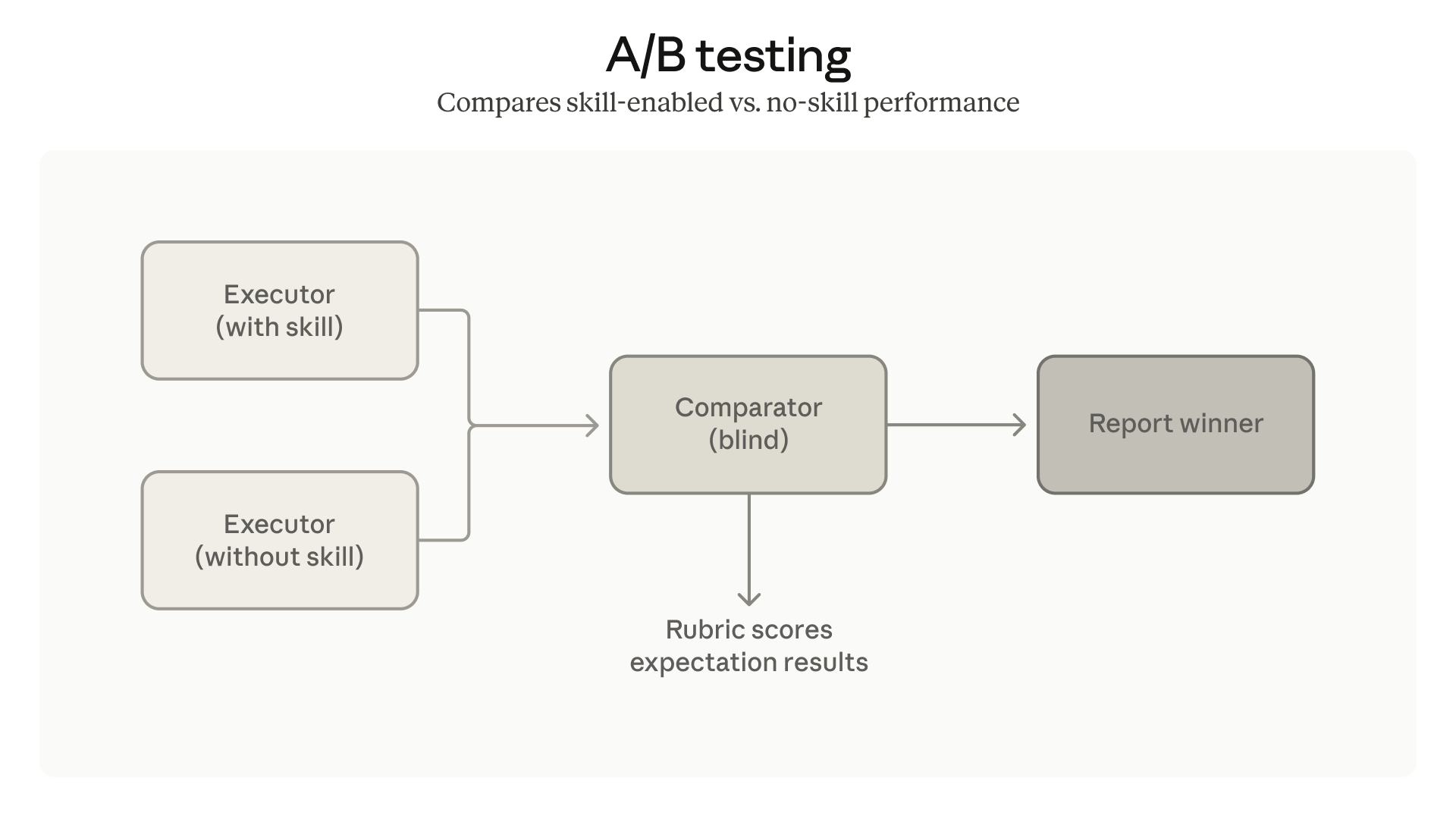
顺序运行评估可能会很慢,积累的上下文会在测试运行之间溢出。能力创造者现在可以启动独立代理来并行运行评估——每个代理都在干净的上下文中,具有自己的令牌和计时指标。更快的结果,避免了交叉污染。
我们还添加了比较代理用于A/B比较:两个技能版本,或者技能与无技能。它们评估输出而不知道哪一个是哪一个,所以你可以告诉一个变化是否真正有帮助。
使技能在恰当的时间触发
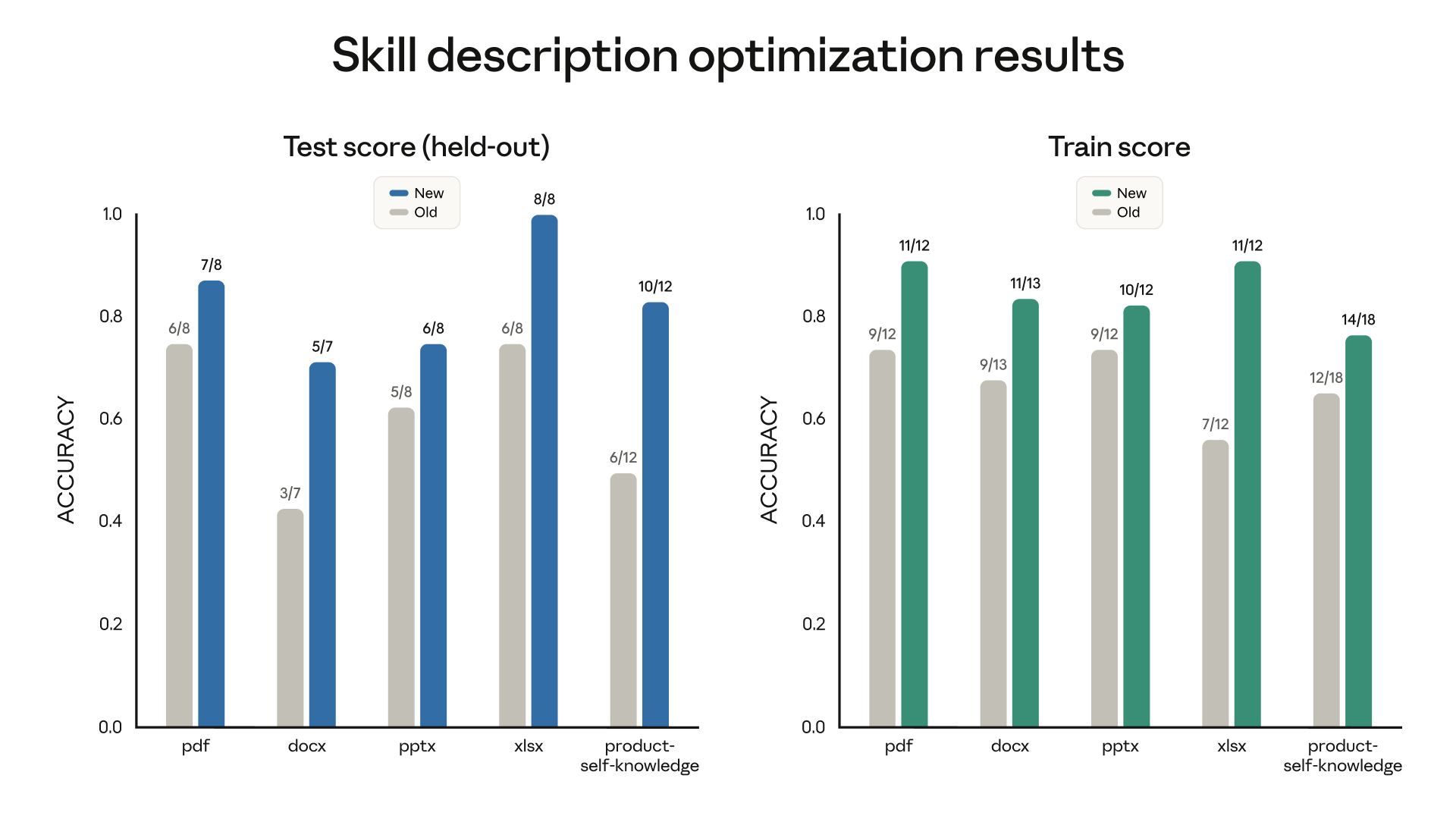
评估衡量输出质量,但只有当你的技能在恰当的时间触发时才有意义。随着技能数量的增长,描述的精确度变得至关重要:过于宽泛会导致假触发,过于狭窄就永远不会触发。能力创造者现在可以帮助你调整描述以实现更可靠的触发——它分析当前的描述与样本提示并建议编辑以减少假阳性和假阴性。
我们在我们的文档创建技能上运行了它,结果在6个公开技能中改进了5个。
未来展望
随着模型的改进,“技能”和“规范”之间的界限可能会变得模糊。今天,一个SKILL.md文件本质上是一个实现计划,提供了详细的说明,告诉Claude如何做什么。随着时间的推移,自然语言描述技能应该做什么可能足够了,模型会自己处理剩下的。
我们今天发布的评估框架是这一方向的步骤。评估已经描述了“什么”。最终,这个描述可能就是技能本身。
开始使用
所有能力创造者更新现在都可在Claude.ai和Cowork中找到。请Claude使用能力创造者来开始使用。