为智能体准备的 Markdown
内容
在线内容和商业的发现方式正在迅速变化。过去,流量来自传统的搜索引擎,SEO 决定了谁能被首先找到。现在,流量越来越多地来自于 AI 爬虫和智能体,它们需要在为人类构建的通常是无结构的网络中获取结构化的数据。
作为一家企业,为了继续保持领先地位,现在是时候考虑不仅要考虑人类访客或传统的 SEO 优化方法,还要像对待人类访客一样对待智能体。
为什么 Markdown 很重要
将原始 HTML 提供给 AI 就像按字数付费阅读包装而不是信件内容。在 Markdown 中,页面上的一个简单的 ## 关于我们 大约消耗 3 个 token;而其 HTML 等价物 <h2>关于我们</h2> 则消耗 12-15 个 token,这还不包括为每个真实网页添加的 <div> 包装、导航栏和脚本标签,它们具有零语义价值。
这篇博客文章在 HTML 中需要 16,180 个 token,而转换为 Markdown 后仅需要 3,150 个 token。这意味着减少了 80% 的 token 使用量。
Markdown 已迅速成为智能体和 AI 系统的通用语言。该格式的明确结构使其非常适合 AI 处理,最终可以在减少 token 浪费的情况下获得更好的结果。
问题在于,网络是由 HTML 而不是 Markdown 构建的,多年来页面权重一直在稳步增加,这使得页面难以解析。对于智能体来说,它们的目标是过滤掉所有非必需元素并扫描相关内容。
HTML 到 Markdown 的转换现在是任何 AI 流程中的常见步骤。然而,这个过程远非理想:它会浪费计算资源,增加成本和处理复杂性,最重要的是,它可能不是内容创建者最初希望内容被使用的方式。
如果 AI 智能体可以直接从源头获取结构化的 Markdown 而不是绕过意图分析和文档转换的复杂性,那该多好。
自动将 HTML 转换为 Markdown
Cloudflare 网络现在支持在源头上进行实时内容转换,对于已启用的区域,使用内容协商 头部。现在,当 AI 系统请求启用了 Markdown for Agents 的任何网站的页面时,它们可以在请求中表示对 text/markdown 的偏好。我们的网络将在可能的情况下自动高效地将 HTML 转换为 Markdown。
以下是其工作原理。要从启用了 Markdown for Agents 的区域获取任何页面的 Markdown 版本,客户端需要在请求中添加带有 text/markdown 作为选项之一的 Accept 协商头部。Cloudflare 将检测到这一点,从源获取原始 HTML 版本,并在将其提供给客户端之前将其转换为 Markdown。
下面是一个使用 curl 示例,带有 Accept 协商头部,请求我们的开发者文档页面:
curl https://developers.cloudflare.com/fundamentals/reference/markdown-for-agents/ \
-H "Accept: text/markdown"
或者,如果您正在使用 Workers 构建 AI 智能体,可以使用 TypeScript:
const r = await fetch(
`https://developers.cloudflare.com/fundamentals/reference/markdown-for-agents/`, {
headers: {
Accept: "text/markdown, text/html",
},
},
);
const tokenCount = r.headers.get("x-markdown-tokens");
const markdown = await r.text();
我们已经看到今天最流行的编码智能体(如 Claude Code 和 OpenCode)都会在其内容请求中发送这些接受头部。现在,对此请求的响应是以 Markdown 格式的。就是这么简单。
HTTP/2 200
date: Wed, 11 Feb 2026 11:44:48 GMT
content-type: text/markdown; charset=utf-8
content-length: 2899
vary: accept
x-markdown-tokens: 725
content-signal: ai-train=yes, search=yes, ai-input=yes
---
title: Markdown for Agents · Cloudflare Agents docs
---
## 什么是 Markdown for Agents
解析和转换 HTML 为 Markdown 的能力已成为 AI 的基础。
...
请注意,我们在转换后的响应中包含一个 x-markdown-tokens 头部,指示 Markdown 文档中估计的 token 数量。您可以在流程中使用此值,例如计算上下文窗口的大小或决定分块策略。
以下是其工作原理的示意图:
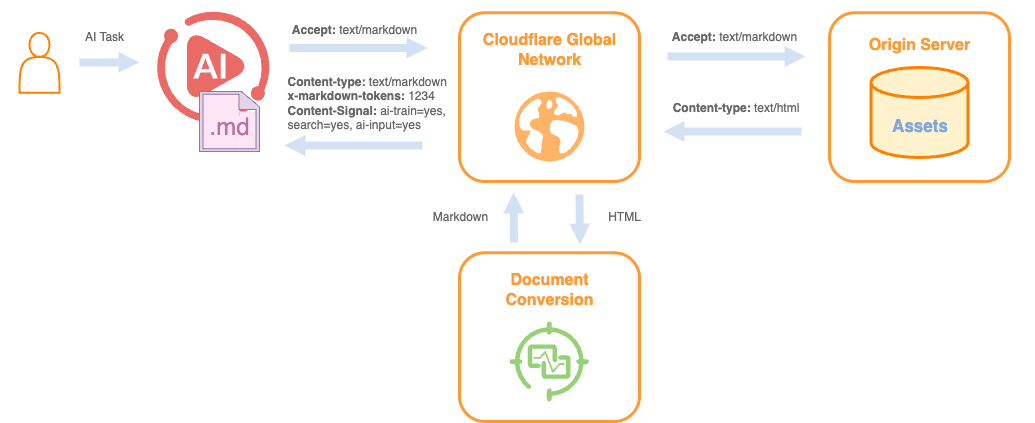
内容信号策略
在我们的上一次生日周,Cloudflare 宣布 了内容信号 - 一个框架,允许任何人表达其内容在访问后可以被使用的偏好。
当您返回 Markdown 时,您需要确保您的内容正在被智能体或 AI 爬虫使用。这就是为什么 Markdown for Agents 转换的响应中包含 Content-Signal: ai-train=yes, search=yes, ai-input=yes 头部信号,指示内容可以用于 AI 训练、搜索结果和 AI 输入,这包括智能体使用。Markdown for Agents 将在未来提供自定义内容信号策略的选项。
有关此框架的更多信息,请查看我们的专用 Content Signals 页面。
在 Cloudflare 博客和开发者文档中试用
我们在我们的开发者文档和博客中启用了此功能,邀请所有 AI 爬虫和智能体使用 Markdown 而不是 HTML 消费我们的内容。
现在通过请求此博客并使用 Accept: text/markdown 试用:
curl https: //blog.cloudflare.com/introducing-markdown-for-agents/ \
-H "Accept: text/markdown"
结果是:
---
description: 在线内容发现的方式正在从传统的搜索引擎转向需要来自为人类构建的网络的结构化数据的 AI 智能体。现在是时候考虑不仅要考虑人类访客,还要像对待人类访客一样对待智能体。
title: 为智能体引入 Markdown
image: https://cf-assets.www.cloudflare.com/zkvhlag99gkb/rzmAhLxuiqzCffB9yZrdf/91858defbc03196c5f074a26117248f9/BLOG-3162_1.png
---
# 为智能体引入 Markdown
在线内容和商业的发现方式正在迅速变化。过去,流量来自传统的搜索引擎,SEO 决定了谁能被首先找到。现在,流量越来越多地来自于 AI 爬虫和智能体,它们需要在为人类构建的通常是无结构的网络中获取结构化的数据。
...
其他转换为 Markdown 的方法
如果您正在构建 AI 系统,需要从 Cloudflare 外部或 Markdown for Agents 无法从内容源转换任意文档,我们提供其他方法将文档转换为 Markdown 供您的应用程序使用:
- Workers AI AI.toMarkdown() 支持多种文档类型,不仅限于 HTML,还支持摘要。
- 浏览器渲染 /markdown REST API 支持 Markdown 转换,如果您需要在将其转换之前在真实浏览器中渲染动态页面或应用程序。
跟踪 Markdown 使用情况
预测 AI 系统浏览网络的方式将发生转变,Cloudflare Radar 现在包括 AI 机器人和爬虫流量内容类型的洞察,全球在 AI Insights 页面和个别机器人信息页面。
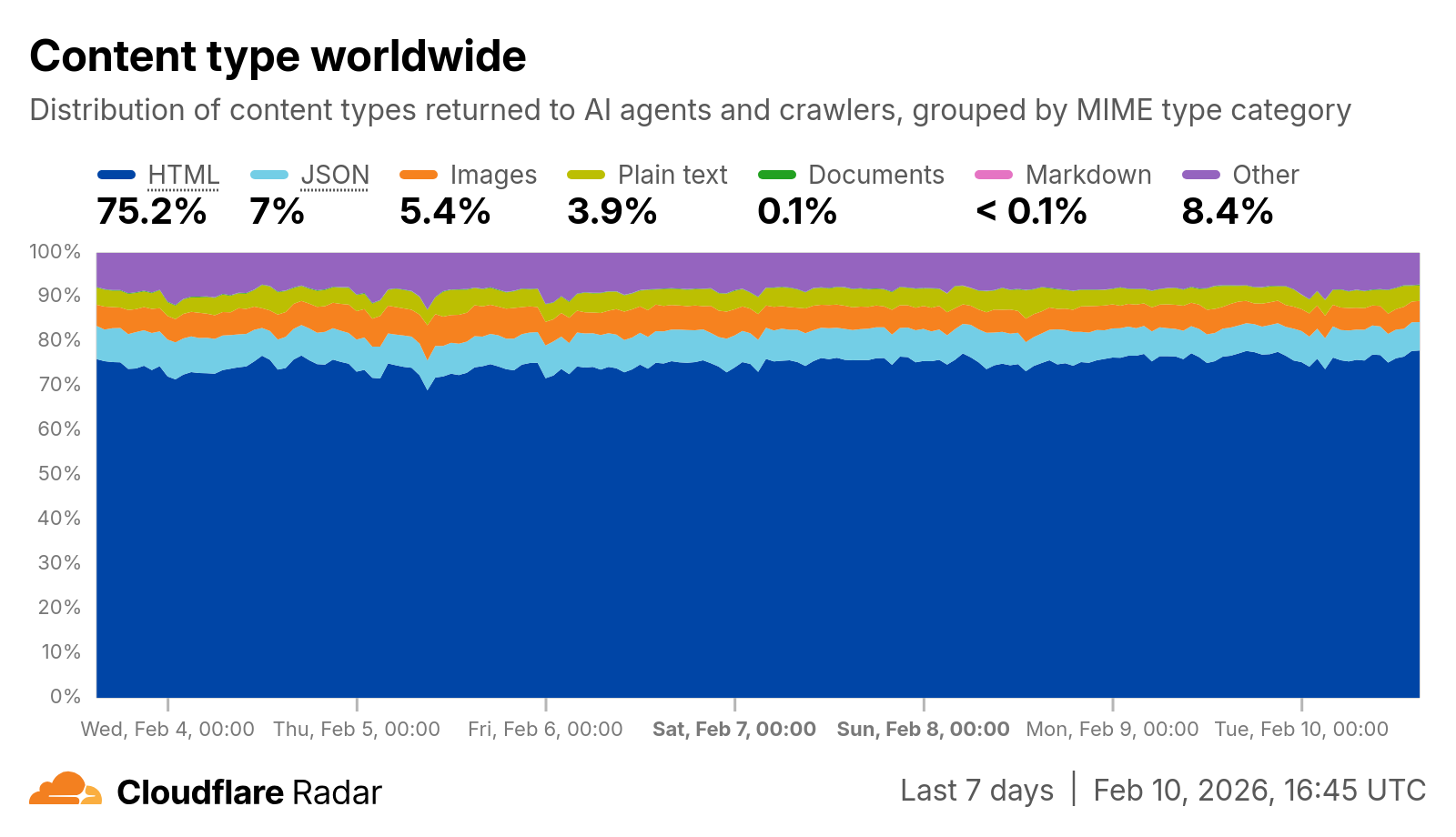
新的 content_type 维度和过滤器显示了返回给 AI 智能体和爬虫的内容类型的分布,按 MIME 类型 分类。
您还可以按特定智能体或爬虫过滤请求 Markdown。以下是返回给 OAI-Searchbot(OpenAI 用于支持 ChatGPT 搜索的爬虫)的 Markdown 请求:
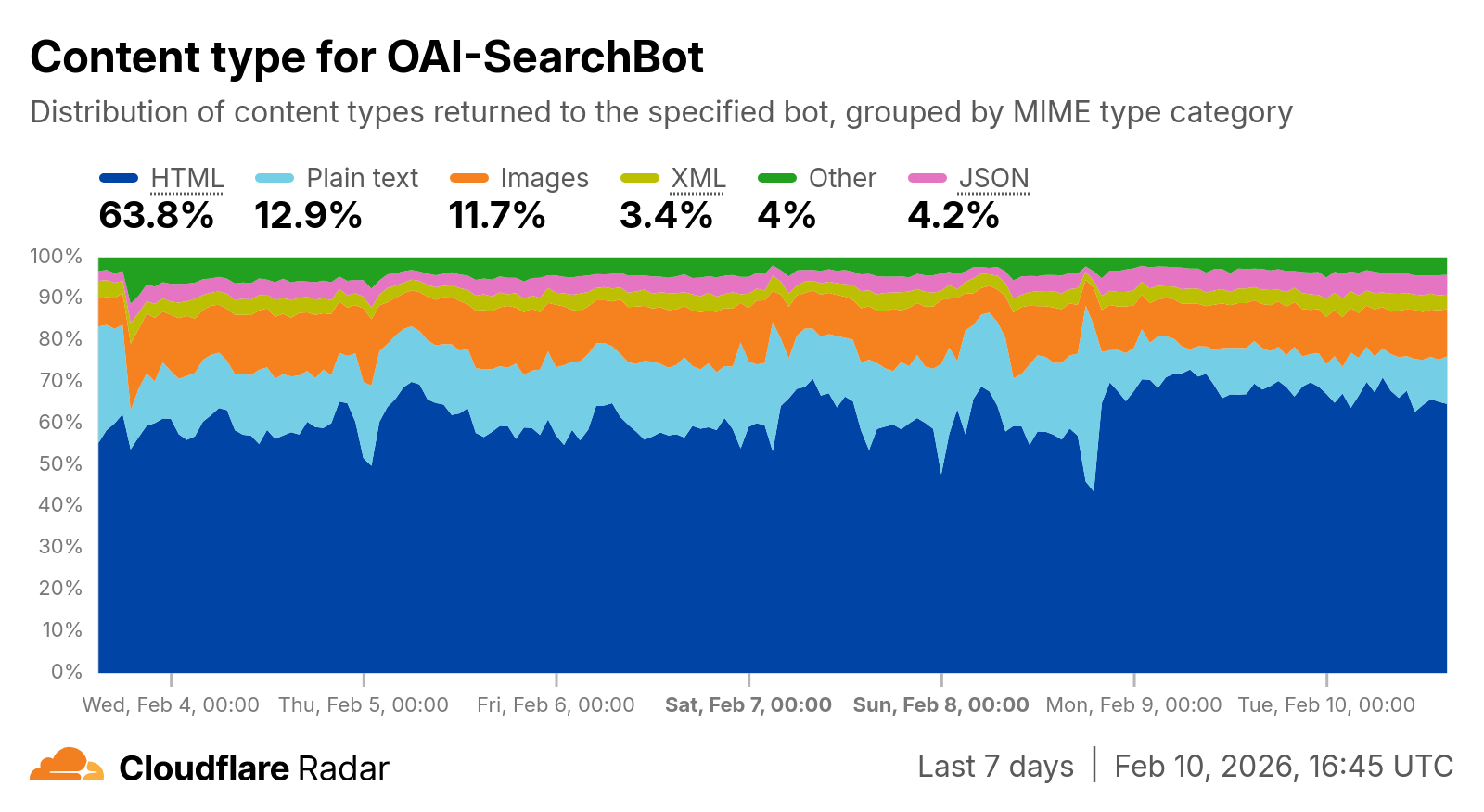
这些新数据将使我们能够跟踪 AI 机器人、爬虫和智能体随时间推移如何消费网络内容。一如既往,Radar 上所有内容都可通过 公共 API 和 Data Explorer 免费访问。
今天开始使用
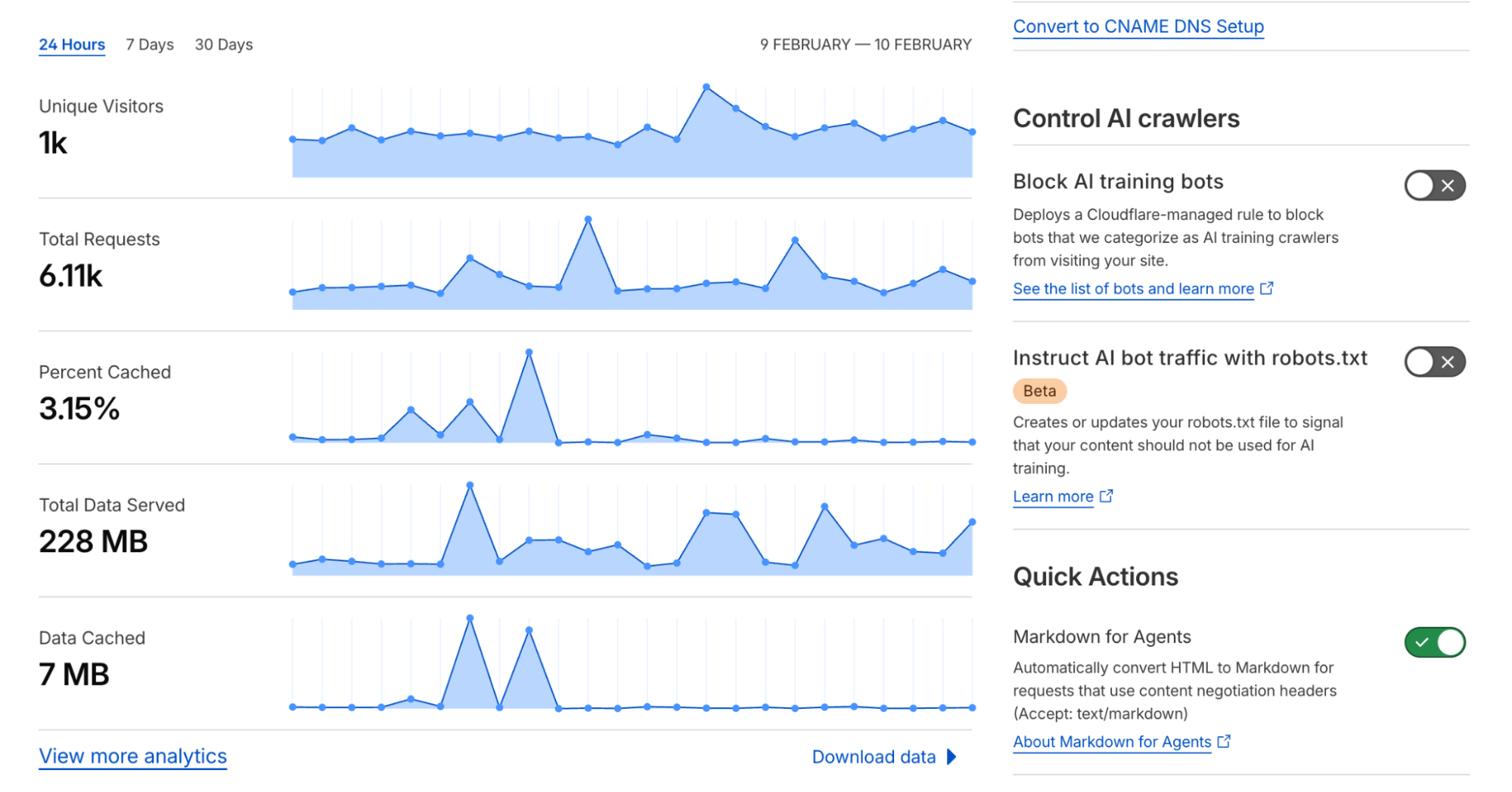
要为您的区域启用 Markdown for Agents,请登录 Cloudflare 仪表盘,选择您的帐户,选择区域,查找快速操作并切换 Markdown for Agents 按钮以启用。此功能现已在 Pro、Business 和 Enterprise 计划以及 SSL for SaaS 客户中免费提供 Beta 版本。
您可以在我们的开发者文档上找到有关 Markdown for Agents 的更多信息。我们欢迎您在继续改进和增强此功能时提供反馈。我们很期待看到 AI 爬虫和智能体如何导航和适应网络的非结构化性质。