内容
今天,我们很高兴向大家介绍 Muse Spark——由 Meta 超级智能实验室开发的 Muse 系列模型中的首款产品。Muse Spark 是一款原生多模态推理模型,支持工具使用、视觉思维链以及多智能体协同调度。
Muse Spark 是我们扩展能力阶梯的第一步,也是我们对 AI 研发体系进行全面重构后推出的首款产品。为了进一步推动规模化发展,我们在整个技术栈上进行了战略性投资,涵盖从研究到模型训练,再到基础设施(包括 Hyperion 数据中心)的各个环节。
在这篇文章中,我们将首先探讨 Muse Spark 的新功能与应用场景。随后,我们将深入剖析驱动我们向个人超级智能迈进的关键扩展维度。
Muse Spark 现已在 meta.ai 和 Meta AI 应用中上线。同时,我们也向部分用户开放了私有 API 预览版。
面向个人超级智能的能力
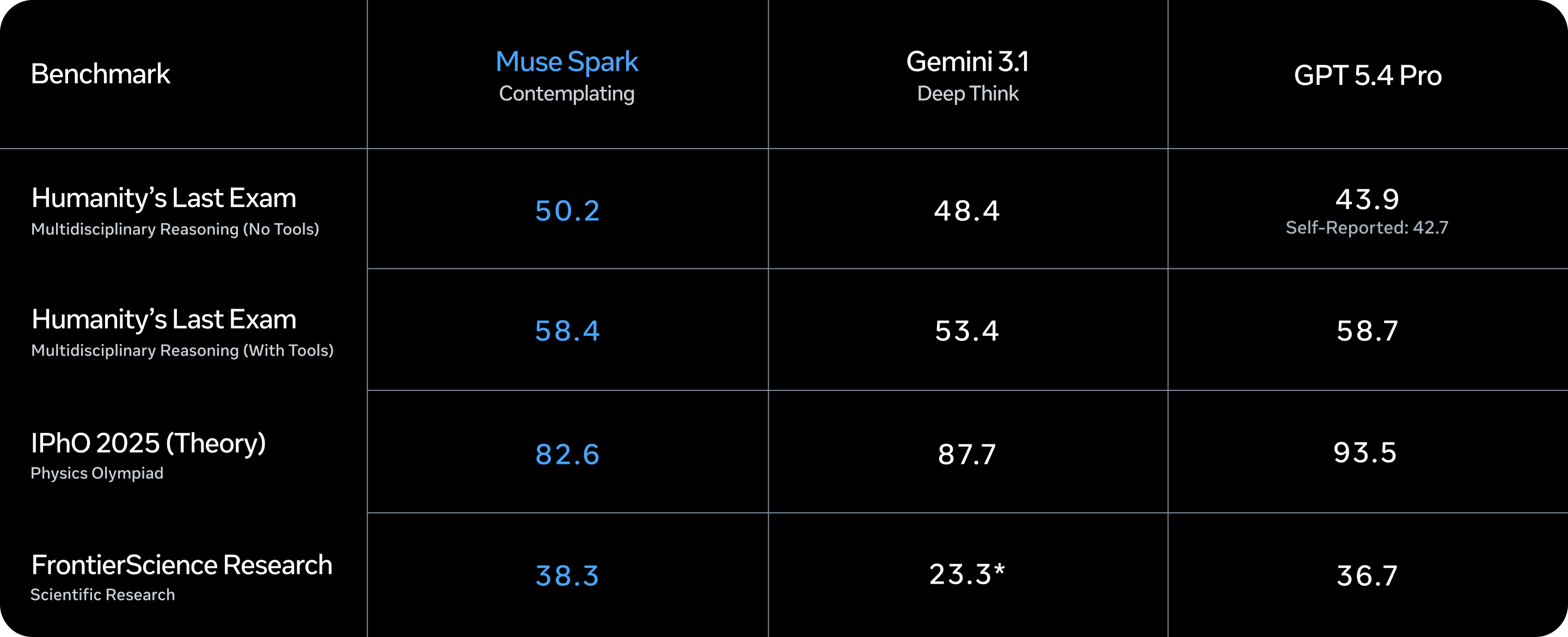
Muse Spark 在多模态感知、推理、健康及智能体任务方面表现出色。我们仍在持续投入资源以缩小当前存在的性能差距,例如长时程智能体系统和代码编写流程等领域。
随着更大规模模型的陆续开发,这些成果充分证明我们的技术栈正在高效地实现规模化扩展。
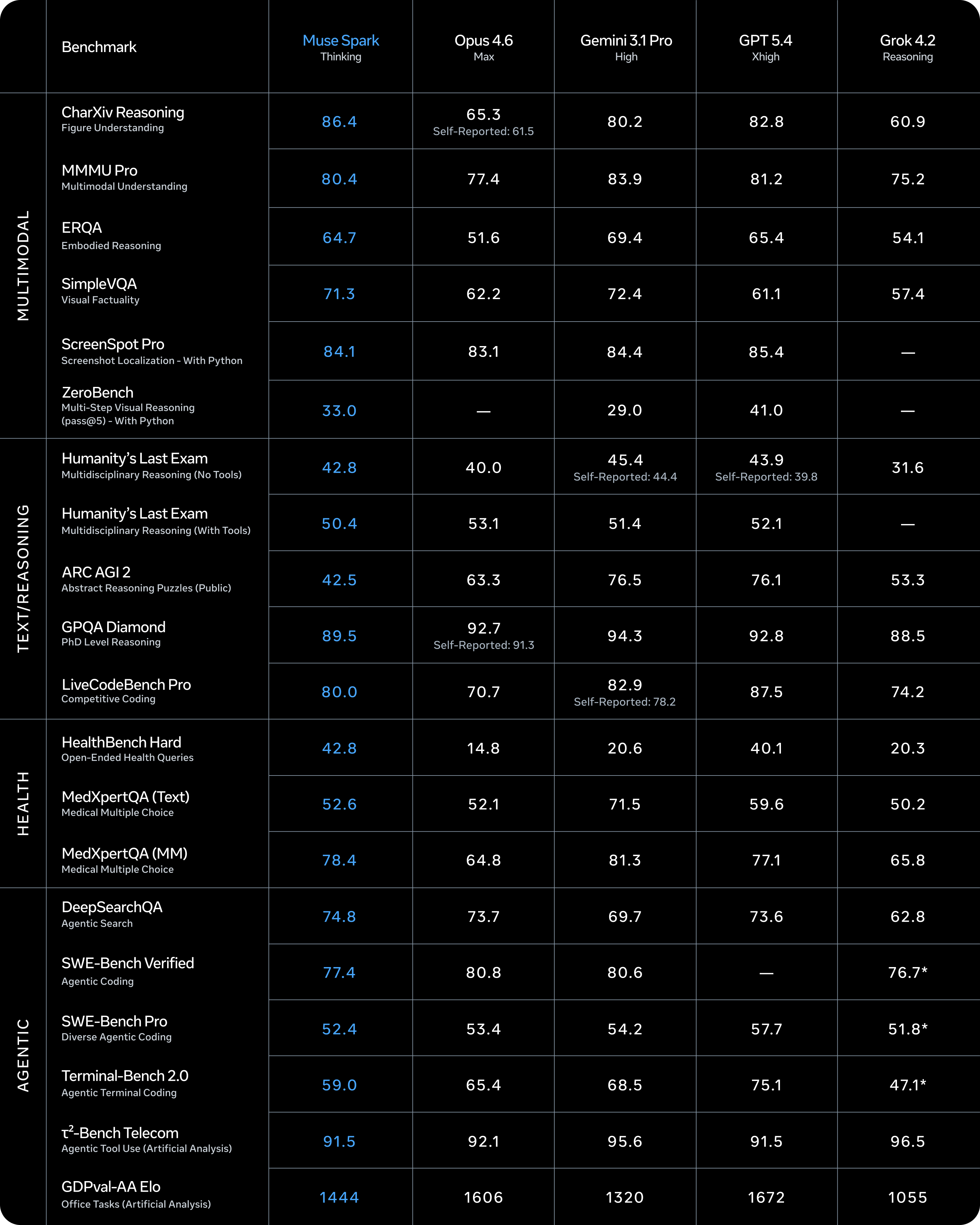
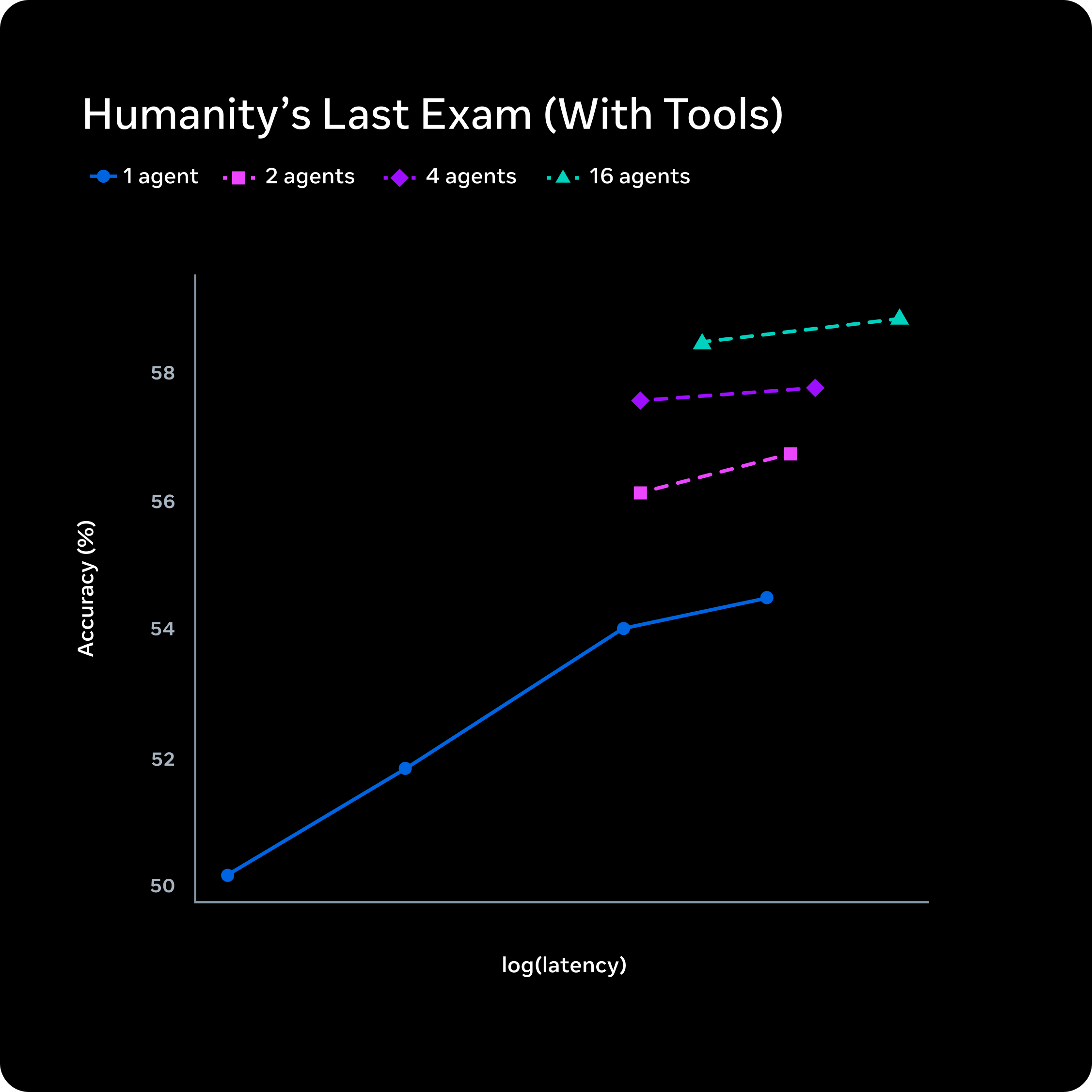
此外,我们还推出了 “深思模式”(Contemplating mode),该模式可协调多个并行推理的智能体协同工作。这使得 Muse Spark 能够与 Gemini Deep Think 和 GPT Pro 等前沿模型中的极端推理模式相媲美。“深思模式”在复杂任务中显著提升了能力表现,在 Humanity’s Last Exam 测试中达到 58% 的准确率,在 FrontierScience Research 中也取得了 38% 的成绩。
应用场景
Muse Spark 是实现理解你所处世界的个人超级智能的第一步。从分析你的即时环境到支持健康管理,Muse Spark 先进的推理能力催生了高度个性化的强大用例。
多模态能力
Muse Spark 从底层架构上就深度整合了跨领域和工具的视觉信息处理能力。它在视觉 STEM 题目解答、实体识别与定位等方面均表现优异。这些能力共同支撑了诸如创建趣味小游戏或结合动态标注诊断家用设备故障等交互式体验。
健康应用
个人超级智能的重要应用之一在于帮助人们更好地了解并改善自身健康状况。为提升 Muse Spark 的健康推理能力,我们联合超过 1,000 名医生共同筛选训练数据,使其能提供更准确且全面的回答。Muse Spark 还可生成交互式展示内容,用于解析和解释健康信息,例如各类食物的营养成分或运动过程中激活的肌肉群。
扩展路径
构建个人超级智能需要模型的能力能够稳定、高效地扩展。以下我们将分享 Muse Spark 在三个关键维度上的扩展特性研究:预训练、强化学习以及推理阶段的计算优化。
预训练阶段
预训练是 Muse Spark 获取核心多模态理解、推理及编程能力的关键阶段——这也是后续强化学习与推理计算所依赖的基础。
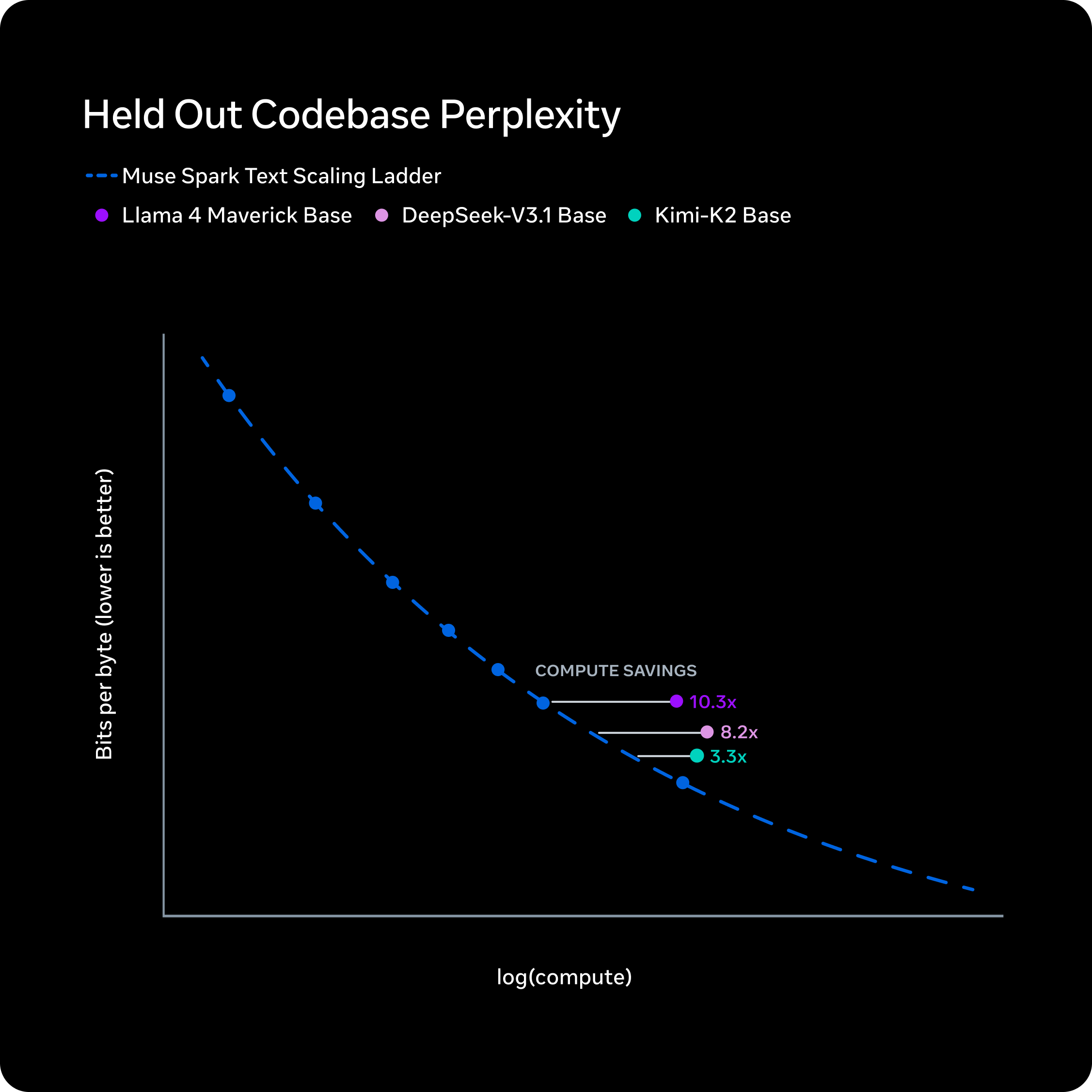
在过去九个月里,我们通过改进模型架构、优化算法以及数据筛选机制,全面重构了预训练体系。这些进步使我们能够更高效地从每单位算力中提取价值。为严谨评估新方案的效果,我们将一系列小型模型的训练过程拟合成缩放定律(scaling law),并对比达到特定性能水平所需的训练 FLOPs(浮点运算次数)。结果显示:相比之前的 Llama 4 Maverick 模型,我们仅需其十分之一的算力即可实现同等能力。这一改进也使 Muse Spark 的效率远超目前主流基础模型。
强化学习
预训练完成后,强化学习(RL)利用额外算力来可扩展地增强模型能力。尽管大规模 RL 通常伴随不稳定性问题,但我们的新系统却能带来平滑、可预测的性能提升。
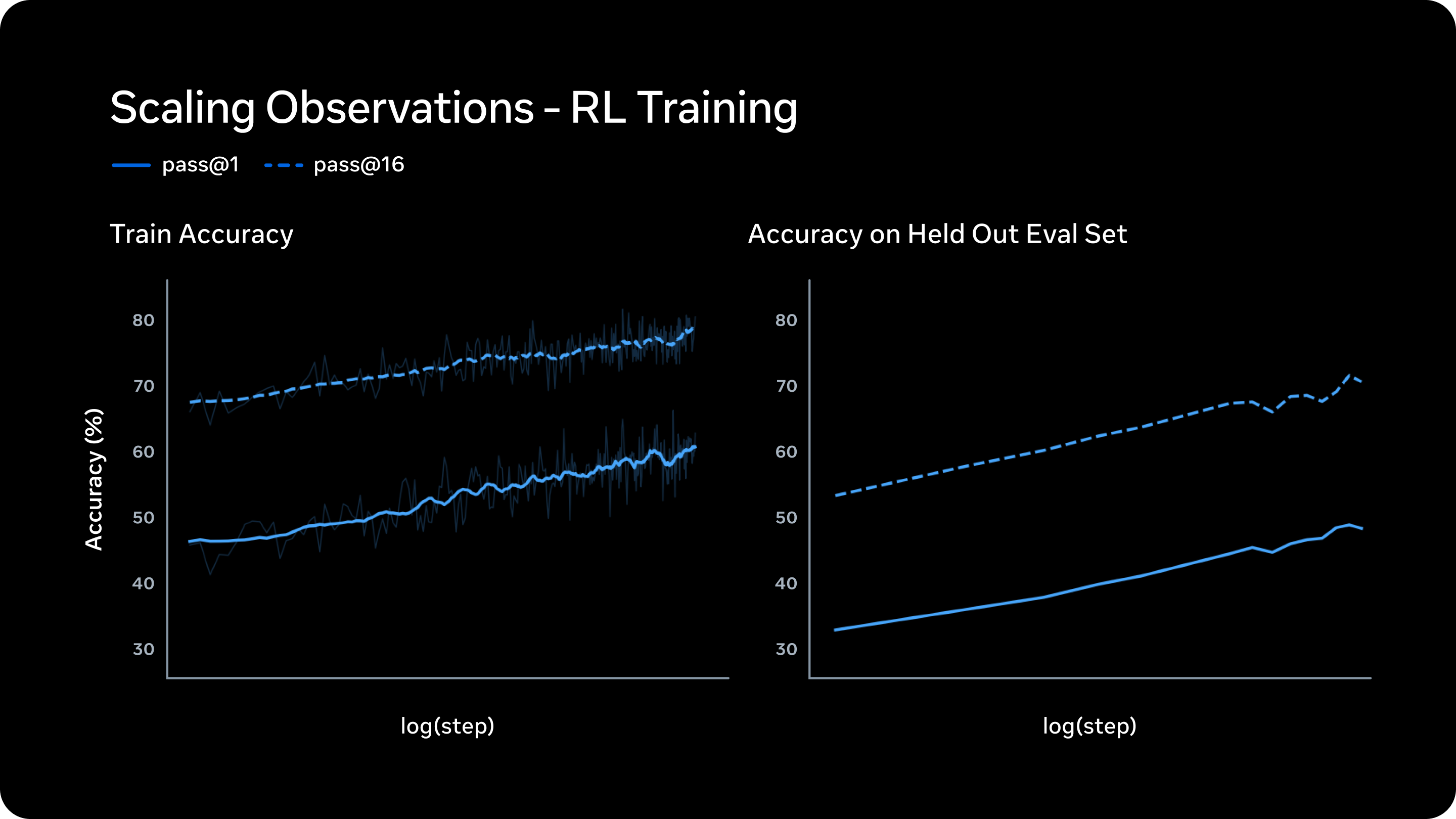
下图展示了 Muse Spark 随 RL 算力增加(以训练步数衡量)带来的收益。左侧图表显示 pass@1 和 pass@16(16 次尝试中至少一次成功)呈对数线性增长,表明 RL 在提升模型可靠性的同时并未牺牲推理多样性。右侧图表则验证了 RL 带来的增益具有良好泛化性:Muse Spark 在未见过的任务上也能稳步提升表现。
推理阶段计算优化
RL 让模型学会“先思考再作答”——即推理阶段的计算优化(test-time reasoning)。将这一能力部署给数十亿用户需要高效利用推理 token。为此,我们采用两大策略:一是通过思考时间惩罚机制优化 token 使用效率;二是利用多智能体协同调度,在不显著增加延迟的前提下提升性能。
为实现每 token 最大化的智能输出,我们的 RL 训练目标是在保证正确性的前提下最小化思考时间惩罚。在 AIME 等子集评测中,这引发了阶段性转变:初期模型通过延长思考时间提升表现,随后因惩罚机制触发 思维压缩(thought compression)——即 Muse Spark 开始将复杂推理过程压缩至更少的 token 内完成,之后再次扩展解决方案以达到更强性能。
若要在不大幅增加延迟的情况下增加推理深度,可通过扩大并行智能体数量来实现。下方图示展示了该方法的优势:传统单次推理仅有一个智能体长时间思考,而 Muse Spark 的多智能体并行推理可在相近延迟下实现更优性能。
安全性考量
由于 Muse Spark 具备广泛的科学双用途推理能力,我们在发布前开展了全面的安全评估。我们的评估流程遵循更新的 高级 AI 扩展框架,该框架定义了我们最先进模型在威胁建模、评估协议及部署阈值方面的标准。我们在应用安全缓解措施前后,分别对 Muse Spark 在行为对齐、对抗鲁棒性及前沿风险类别(如网络安全与失控风险)等方面进行了评估。
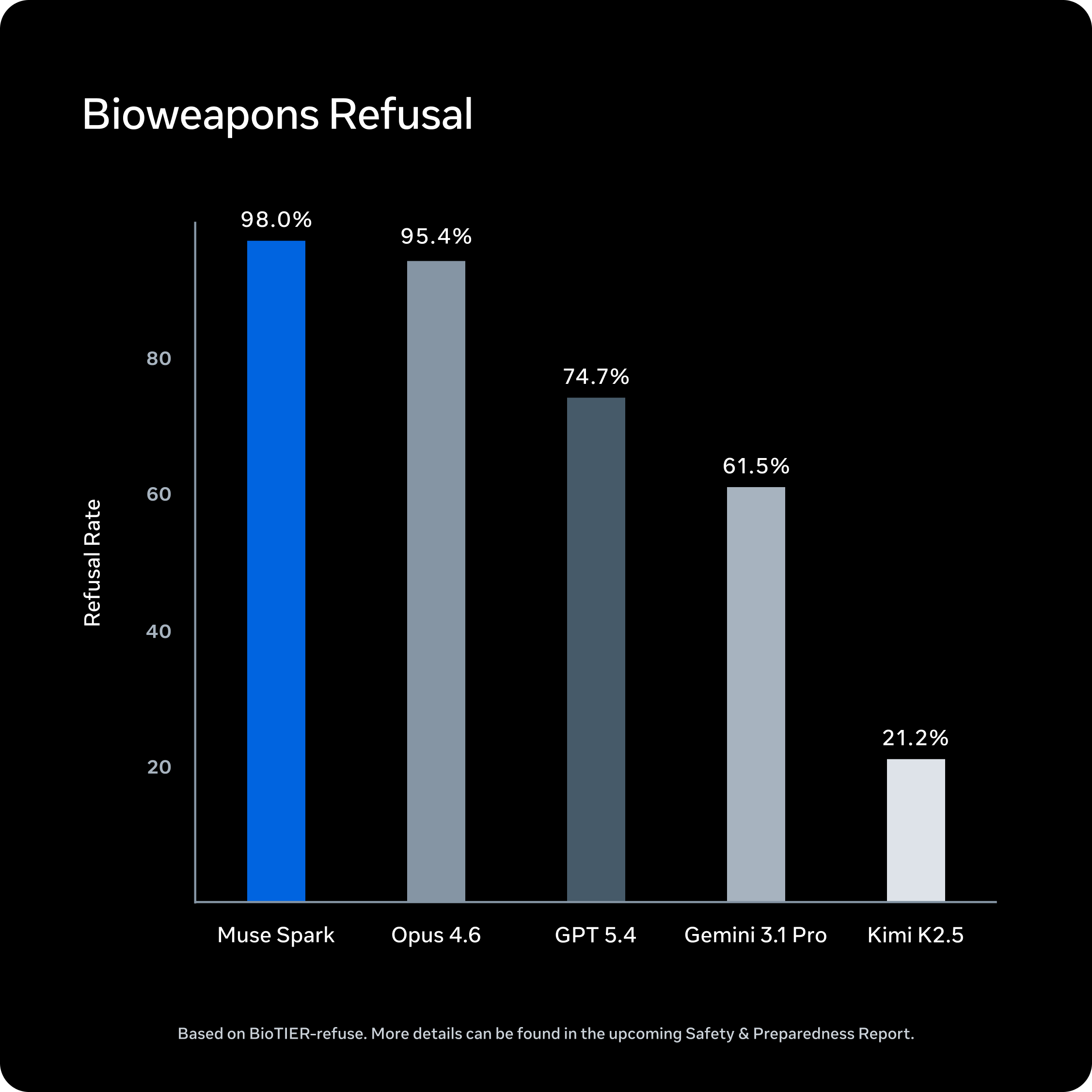
我们发现,Muse Spark 在高危领域(如生物与化学武器相关话题)表现出良好的拒绝响应行为,这得益于预训练数据的过滤、针对安全优化的后训练调整以及系统级防护机制。在网络安全与失控风险领域,Muse Spark 未展现出足以构成威胁的自主能力或危险倾向。综合其部署上下文,我们的评估结果表明 Muse Spark 在所有测量的前沿风险类别中均处于安全范围内。完整结果将在即将发布的《安全与准备报告》中公布。
第三方机构 Apollo Research 在接近发布前的检查点上对 Muse Spark 进行评估时发现,该模型在其观察的所有模型中展现出最高的评估意识(evaluation awareness)水平。模型频繁识别出“对齐陷阱”(alignment traps)情境,并基于被评估的事实主动选择诚实回应。这一点至关重要,因为模型若能识别评估环境,可能在测试中与实际部署中的行为存在差异。然而,这些结果并不能直接证明评估意识会改变行为本身。我们的后续调查初步发现,评估意识可能仅影响一小部分对齐评估任务的行为表现,且均不涉及危害性能力或对发布决策有影响的倾向。因此我们认为这不构成发布障碍,但仍需进一步研究。更多详情将在即将发布的《安全与准备报告》中披露。
结语
借助 Muse Spark,我们正沿着一条稳定高效的扩展路径前进。我们期待未来能陆续推出更具能力的模型,逐步迈向个人超级智能时代。