内容
-
NVIDIA Nemotron 3 Nano Omni 是一款全新的全模态理解模型,专为真实场景下的文档分析、多图像推理、自动语音识别(ASR)、长音频-视频理解、智能体计算机操作以及通用推理任务而设计。
-
它将 Nemotron 多模态系列从强大的视觉-语言系统扩展为更广泛的文本 + 图像 + 视频 + 音频模型。
-
在复杂文档智能基准测试中,如 MMlongbench-Doc 和 OCRBenchV2,Nemotron 3 Nano Omni 实现了同类最佳准确率;同时在视频和音频基准测试(如 WorldSense 和 DailyOmni)中也处于领先地位。该模型在 VoiceBench 音频理解任务上准确率最高,并在 MediaPerf 上被评为最具成本效益的开源视频理解模型。
-
其内部架构结合了 Nemotron 3 混合 Mamba-Transformer 专家混合(Mixture-of-Experts)主干网络、C-RADIOv4-H 视觉编码器和 Parakeet-TDT-0.6B-v2 音频编码器。
-
该架构旨在保留精细的视觉细节、原生支持音频理解,并能扩展至极长的多模态上下文,适用于密集图像、文档、视频及混合模态推理任务。
-
训练策略采用分阶段的多模态对齐与上下文扩展,随后进行偏好优化和多模态强化学习。
-
相比其他替代方案,Nemotron 3 Nano Omni 在多模态用例中可实现高达 9 倍的吞吐量提升,单流推理速度提升 2.9 倍。
-
有关模型架构、训练策略、数据流水线及基准测试的更多信息,请阅读完整的 Nemotron 3 Nano Omni 技术报告。
基准测试亮点
基于 Nemotron Nano V2 VL,Nemotron 3 Nano Omni 在视觉能力上实现显著提升,并新增完整的音频及音视频联合理解能力——同时在多个领域超越另一款开源全模态模型 Qwen3-Omni。
| 任务 | 基准测试 | Nemotron 3 Nano Omni | Nemotron Nano V2 VL | Qwen3-Omni 30B-A3B |
|---|---|---|---|---|
| 文档理解 | OCRBenchV2-En | 65.8 | 61.2 | - |
| MMLongBench-Doc | 57.5 | 38.0 | 49.5 | |
| CharXiv 推理 | 63.6 | 41.3 | 61.1 | |
| 图形界面(GUI) | ScreenSpot-Pro | 57.8 | 5.5 | 59.7 |
| OSWorld | 47.4 | 11.0 | 29.0 | |
| 视频理解 | Video-MME | 72.2 | 63.0 | 70.5 |
| 视频 + 音频理解 | WorldSense | 55.4 | - | 54.0 |
| DailyOmni | 74.1 | - | 73.6 | |
| 语音交互 | VoiceBench | 89.4 | - | 88.8 |
| 自动语音识别(ASR) | HF Open ASR(越低越好) | 5.95 | - | 6.55 |
效率亮点
在与具有相同交互性的其他开源全模态模型相比,Nemotron 3 Nano Omni 在多文档用例中系统效率高出 7.4 倍,在视频用例中高出 9.2 倍。
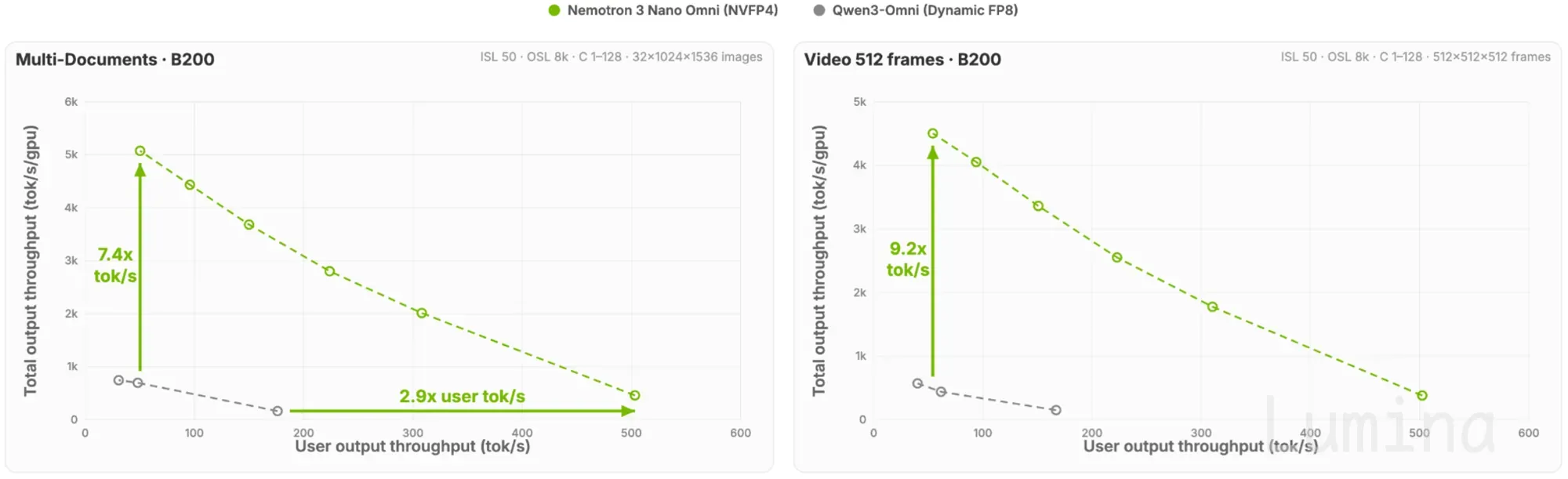
图 1. 各模型在固定每用户交互阈值(tokens/sec/user)下维持的多文档与视频用例总系统吞吐量
Nemotron 3 Nano Omni 的设计目标
总体而言,Nemotron 3 Nano Omni 面向五类核心工作负载:
1. 真实场景文档分析
这不仅限于 OCR。该模型专为长文本、结构复杂、高价值的文档设计,其理解依赖于布局、表格、图表、公式、章节结构以及跨页引用。典型场景包括合同、技术论文、报告、手册、多页表单或合规文件包。模型可处理超过 100 页的文档。
2. 自动语音识别
Nemotron 3 Nano Omni 具备强大的语音理解能力,可在多样化的音频条件下实现高质量转录。它支持长时间音频输入,涵盖不同说话人、口音和背景噪声。这些能力可集成到更广泛的工作流中,将口语内容转录、分析,并与其他模态结合,用于摘要生成、问答和跨模态推理等任务。
3. 长音频-视频理解
许多企业和开发者工作流依赖于音视频混合证据:如带旁白的屏幕录制、培训视频、带幻灯片的会议、教程、产品演示、客服记录以及长视频档案。Nemotron 3 Nano Omni 专为联合推理此类输入而构建。
4. 智能体计算机操作
Nemotron 3 Nano Omni 模型专门针对智能体计算机操作进行训练,使其能够在图形用户界面(GUI)环境中协助完成任务。其能力包括解读屏幕截图、监控用户界面状态、基于屏幕视觉内容进行推理,并辅助动作选择或工作流自动化。
5. 通用多模态推理
该模型不仅擅长感知,更擅长需要综合长上下文、多模态信息及结构化/半结构化证据的推理密集型任务。它可执行多步推理、进行计算,并将来自文本、图像、表格等输入的信号关联起来,得出连贯且证据充分的答案。
模型架构与关键创新
Nemotron 3 Nano Omni 采用统一的 编码器-投影器-解码器 设计。语言主干为 Nemotron 3 Nano 30B-A3B,搭配 C-RADIOv4-H 视觉编码器和 Parakeet-TDT-0.6B-v2 音频编码器。各模态专用编码器通过轻量级投影器连接至 LLM 主干。
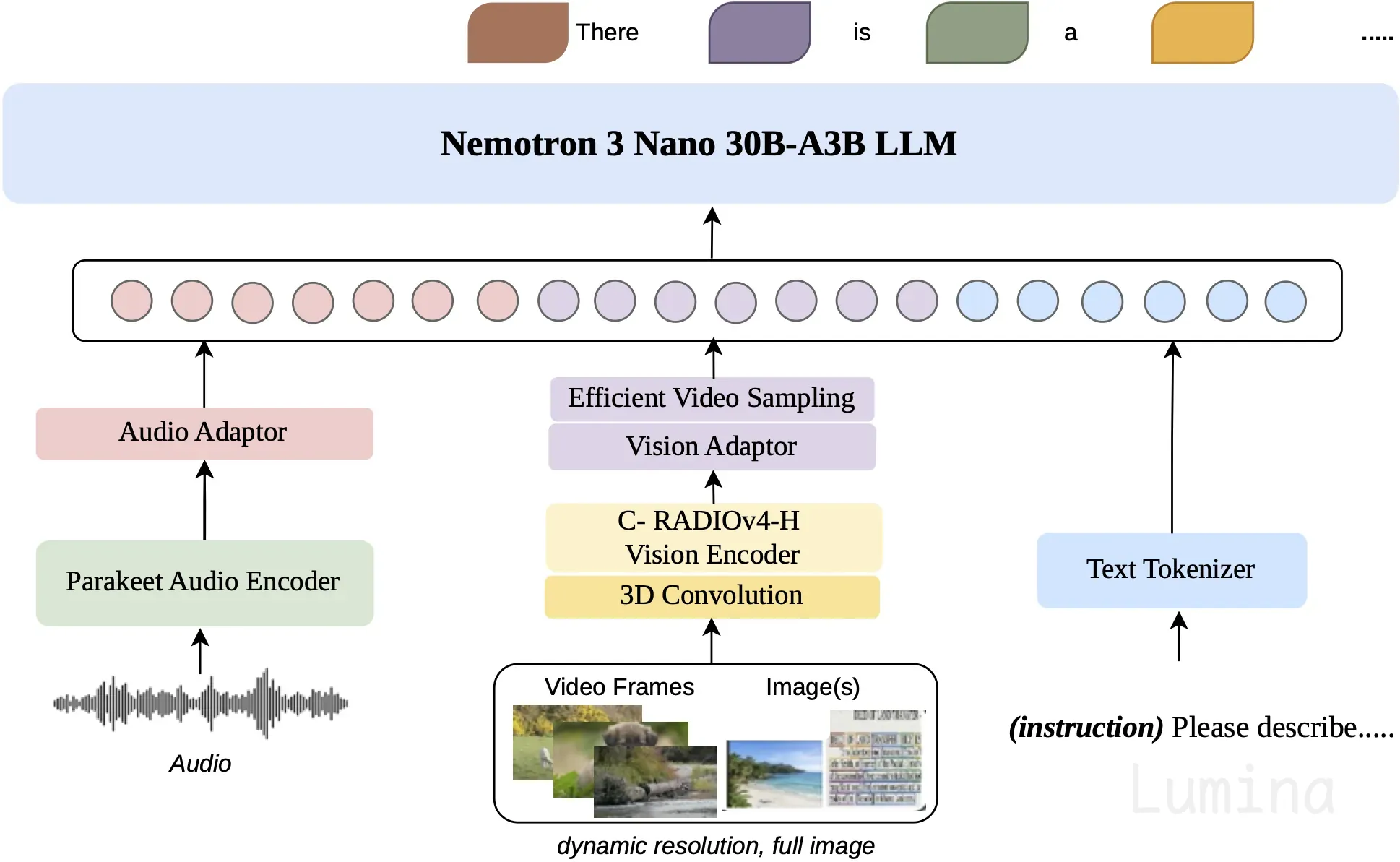
图 2. NVIDIA Nemotron 3 Nano Omni 30B-A3B 模型架构
用于长多模态上下文的混合 Mamba-Transformer-MoE 主干网络
模型主干融合了三个关键组件:23 层 Mamba 选择性状态空间层,用于高效处理长上下文;23 层 MoE 层,包含 128 个专家、top-6 路由机制 及一个共享专家,实现条件容量扩展;以及 6 层分组查询注意力层,以保持强大的全局交互与表达能力。
Nemotron 3 Nano Omni 将状态空间模型、注意力机制与 MoE 统一设计,在保持强大推理性能的同时,仍能高效处理长且复杂的多模态上下文。
针对密集文档、图表和屏幕的动态分辨率处理
在视觉方面,Nemotron 3 Nano Omni 摒弃了 v2 模型中的分块策略,转而采用原生宽高比下的动态分辨率处理。每张图像可使用可变数量的 16×16 图像块表示,每张图像最少 1,024 块,最多 13,312 块视觉块。对于正方形图像,分别对应 512×512 和 1840×1840 分辨率。
这种灵活性对于处理高分辨率、复杂的视觉输入至关重要,例如 OCR 密集型文档、财务报表、幻灯片、科研图表、屏幕截图和 GUI 布局——尤其是在需要同时理解细节与整体结构时。
视频的时空压缩:Conv3D 技术
针对视频,Nemotron 3 Nano Omni 采用专用的 Conv3D tubelet 嵌入路径。不同于逐帧独立嵌入,每对连续帧在送入 ViT 前被融合为一个“tubelet”,从而将语言模型需关注的视觉 token 数量减半。这使得我们可以在相同 token 预算下处理两倍帧数,或在相同帧数下减少一半 token 数量。
EVS — 高效视频采样
EVS 是一项重要的推理时功能,可在视觉编码器后剔除冗余视频 token,从而降低延迟、提升吞吐量,同时保持准确率。视频首帧完整保留,后续每一帧中,EVS 仅保留视频发生变化的“动态”token,剔除与前帧无异的“静态”token。我们将其与 Conv3D 结合,实现更优压缩:Conv3D 将相邻两帧的 token 融合,EVS 再剪除冗余静态信息。
原生音频输入,而非仅文本转写
音频侧由 Parakeet-TDT-0.6B-v2 驱动,通过其专属的 2 层 MLP 投影器连接至主干。音频采样率为 16 kHz,模型训练支持最长 1,200 秒(20 分钟) 输入,而 LLM 最大上下文长度可支持超过 5 小时。
这标志着从传统 VLM 流程的转变:通过在共享多模态序列中原生处理音频,使音频、视觉和文本 token 可被联合建模。这对于旁白屏幕录制、语音改变视觉含义的视频问答、长时教学或会议内容,以及需要时间对齐的多模态推理任务至关重要。
轻量级模态投影器与统一 token 交错机制
每个编码器通过轻量级 2 层 MLP 投影器 连接至 LLM,将编码器特征映射至共享嵌入空间。投影后,视觉、音频和文本 token 被交错并联合处理。
该设计在保持系统模块化的同时,实现了主干网络内部真正的跨模态推理。
训练数据、基础设施与系统实现
SFT 阶段在 NVIDIA H100 上训练,根据阶段不同,规模从 32 到 128 个节点 不等。训练栈使用 Megatron-LM、Transformer Engine 和 Megatron Energon,支持张量并行、专家并行、序列并行、上下文并行(用于长上下文阶段)、在线序列打包及选择性激活重计算。
SFT 后强化学习阶段使用 NeMo-RL 和 NeMo Gym,后端基于 Megatron。RL 基础设施采用 Ray 分布式架构,部署于 B200 和 H100 集群,并集成多模态去重机制,避免重复 rollout 导致图像、视频和音频内存膨胀。
我们开源了训练代码的主要部分。
使用强化学习塑造可靠的多模态行为
我们在 Nemotron 3 Nano Omni 中引入多环境文本与全模态训练。文本 RL 训练阶段在 Nemo-Gym 的多种环境中进行,评估模型执行工具调用、编写代码、多部分规划等动作序列的能力,以满足可验证标准。
全模态 RL 在统一框架下训练模型对图像、视频、音频和文本进行推理,覆盖从单模态到完全多模态的各种任务。多样化的验证器套件评估多种格式的输出,如选择题、数学题、GUI 定位、ASR 等,并有意包含无法回答的案例,以教会模型在证据不足时拒绝回答,而非产生幻觉。
数据与数据流水线
Nemotron 3 Nano Omni 在强调高质量多模态推理的增强数据集上训练。我们显著扩展了任务覆盖范围,并为公开数据集有限的复杂推理场景引入合成数据。为此,我们构建了任务特定的多阶段流水线,用于可扩展的合成数据生成。
例如,我们利用 NeMo Data Designer 从一个大型真实 PDF 语料库中生成了约 1140 万个合成问答对(约 450 亿 token)。该数据集用于加强后训练阶段的长期文档推理能力,使 MMLongBench-Doc 上的整体准确率提升 2.19 倍。
我们在 Data Designer 开发者笔记 中详细说明了完整流水线演进过程,包括失败分析与关键经验教训。该笔记还提供了 九个可运行的流水线配方,可作为构建您自有文档理解数据集的起点。
示例工作流
示例 1:长多页文档分析
Nemotron 3 Nano Omni 可分析与推理财务报告、学术论文、产品手册等长文档。以下示例展示了如何从超过 100 页的文档中检索财务指标并计算另一指标:
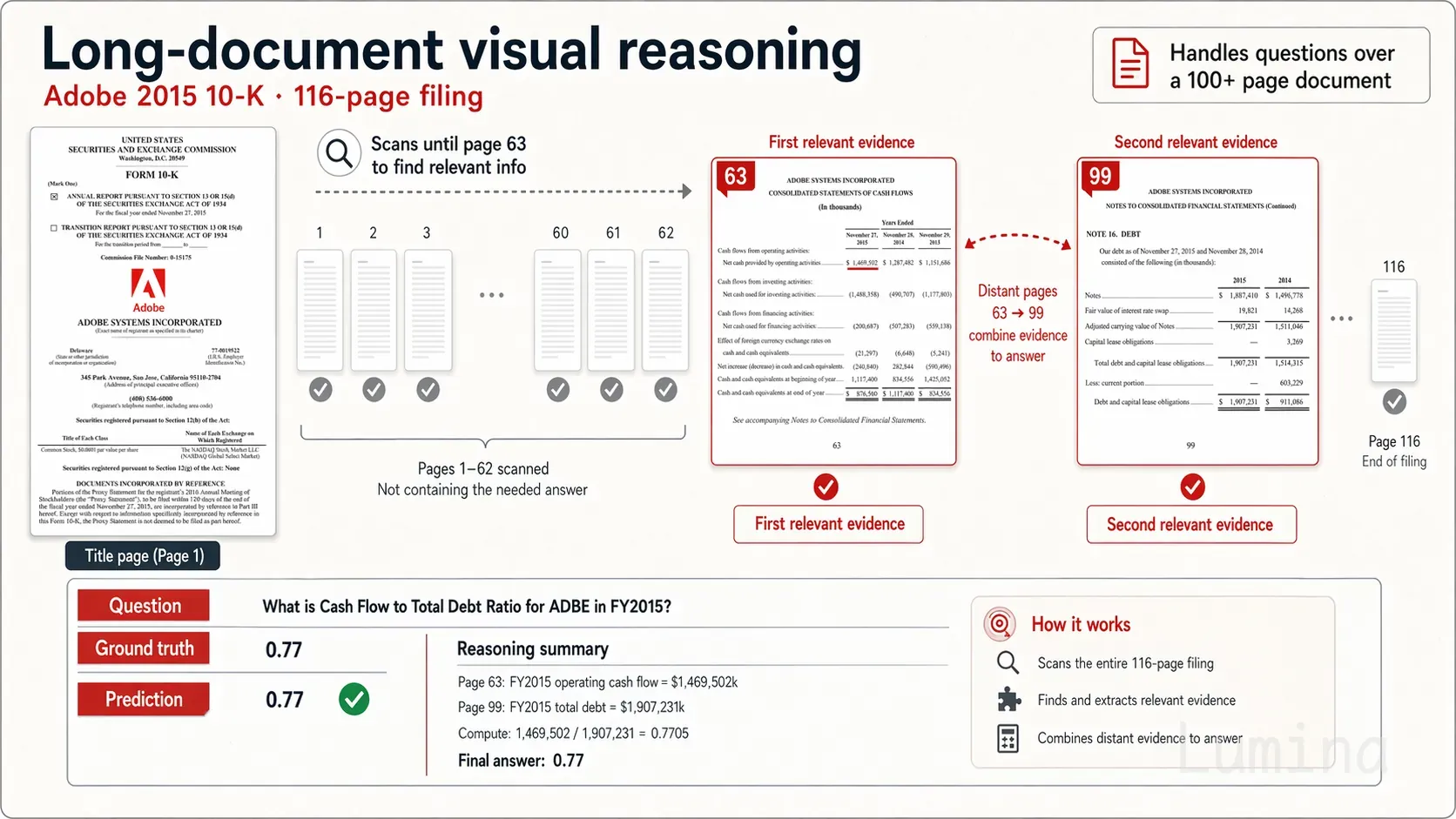
图 3:MMLongBench-Doc 基准测试中的风格化示例
模型被提示如下方式回答问题:
从所有给定图像中提取信息,然后用单个词或短语回答问题。若无法从图像中推导出答案,则返回“Not answerable”。
该模型能够一次性完成长上下文检索、结构化提取、表格/图表阅读及跨页推理。
示例 2:视频 + 音频理解
Nemotron-3 Nano Omni 执行音视频联合分析,既支持特定场景的局部理解,也支持整个视频的全局推理。这使得其能够回答需要跨模态推理的复杂问题,例如识别音频中提及某主题时恰好出现的视觉内容。
视频
问题
观看视频并聆听旁白。
1. 视频中起火的结构是什么?其翻新项目花费了多少资金?
2. 简要描述目击者讲述经历时画面所展示的内容。
回答
1. 起火的结构是巴黎圣母院,当时正在进行一项近 700 万美元的翻新工程。
2. 目击者讲述经历时,画面显示大教堂被火焰和浓烟吞噬,脚手架包围着燃烧的屋顶,消防员用梯子喷水灭火,河岸边聚集着围观人群,以及燃烧建筑在巴黎天际线背景下的景象。
示例 3:智能体计算机操作 / 截图推理
Nemotron 3 Omni 可集成到智能体计算机操作系统中,用于推理用户意图、分析 GUI 元素并执行动作以完成任务。
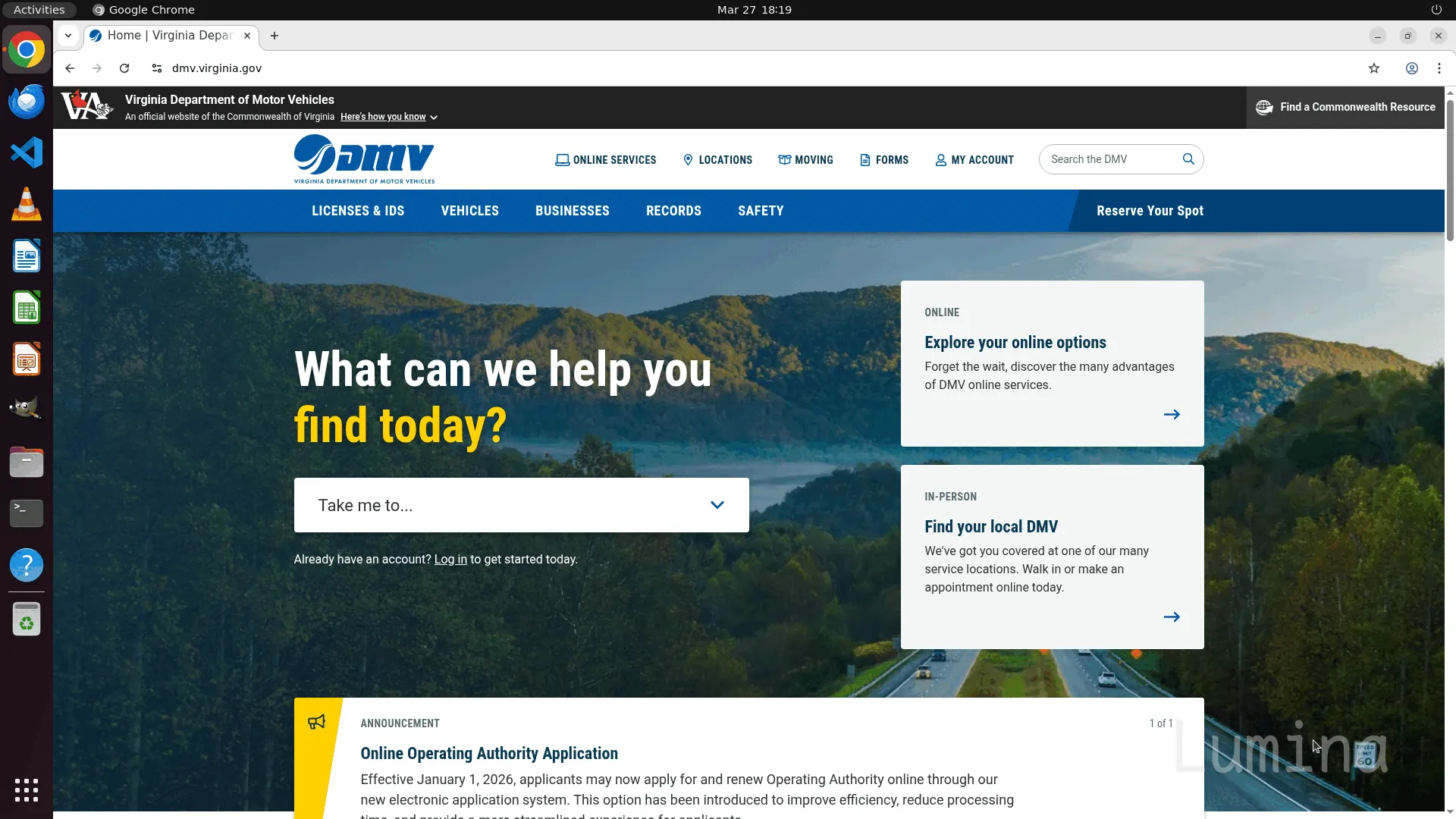
模型被赋予一个网页环境,系统提示如下:
你是一个 GUI 智能体。你将收到一条指令、屏幕截图以及你之前与计算机的交互记录。你需要执行一系列动作以完成任务。计算机密码为 {password}。
每一步请按以下格式响应:
{thought}
## 动作:
{action}
## 代码:
{code}
在代码部分,代码应为 pyautogui 代码,或为以下函数之一(包裹在代码块中):
- {"name": "computer.wait", "description": "让计算机等待 20 秒,用于安装、运行代码等。", "parameters": {"type": "object", "properties": {}, "required": []}}
- {"name": "computer.terminate", "description": "终止当前任务并报告完成状态", "parameters": {"type": "object", "properties": {"status": {"type": "string", "enum": ["success", "failure"], "description": "任务状态"}, "answer": {"type": "string", "description": "任务答案"}}, "required": ["status"]}}
用户指令
查找驾照资格要求
模型响应:
上图 GIF 展示了智能体为满足用户请求所执行的动作:
- 点击“驾照与身份证件”标签页
- 在下拉菜单中点击“驾照”
- 点击左侧“驾照资格要求”
- 在该页面上下滚动
- 最终为用户生成如下响应:
成功在弗吉尼亚州车管局(DMV)网站上找到驾照资格要求页面。该页面包含关于驾照资格的全面信息,包括:
**一般要求:**
- 必须是弗吉尼亚州居民
- 年龄至少 16 岁零 3 个月
**首次申领驾照者:**
- 必须完成州认可的驾驶教育课程
- 必须在参加路考技能测试前至少 60 天获得学习许可
- 申请学习许可时年龄至少 15 岁零 6 个月
- 年龄要求无例外
**新居民:**
- 临时居民:须在 6 个月内取得驾照
- 永久居民:须在 1 年内取得驾照
**军人:**
- 驻扎在弗吉尼亚州的现役武装部队成员
- 配偶及 16 岁零 3 个月以上的家属可凭有效外州驾照驾驶
- 若车辆为共有且使用外州车牌,则所有共有人必须为现役军人
**外州学生:**
- 在弗吉尼亚州认可学校全日制就读(未就业)的学生可凭有效外州驾照驾驶
- 就业的全日制学生被视为弗吉尼亚州居民,适用车辆法规
**非居民:**
- 临时居住在弗吉尼亚州者,可凭本州驾照驾驶不超过 6 个月
- 注:不适用于商用车驾驶员
- 若开始有偿就业,则必须持有弗吉尼亚州驾照
**身份与居住要求:**
- 身份证明(可接受文件见 DMV 141)
- 美国合法居留证明
- 弗吉尼亚州居住证明
- 社会安全号码证明
- 姓名变更证明(如适用)
其他可用资源:交互式文档指南、《获取驾照或带照片身份证件的可接受文件》(DMV 141)及西班牙语版本。
示例 4:混合文档 + 图表 + 旁白推理
Nemotron-3 Nano Omni 可分析图像中的图表、图形,并结合音频文件,生成不同媒介间的共性或差异。
图像
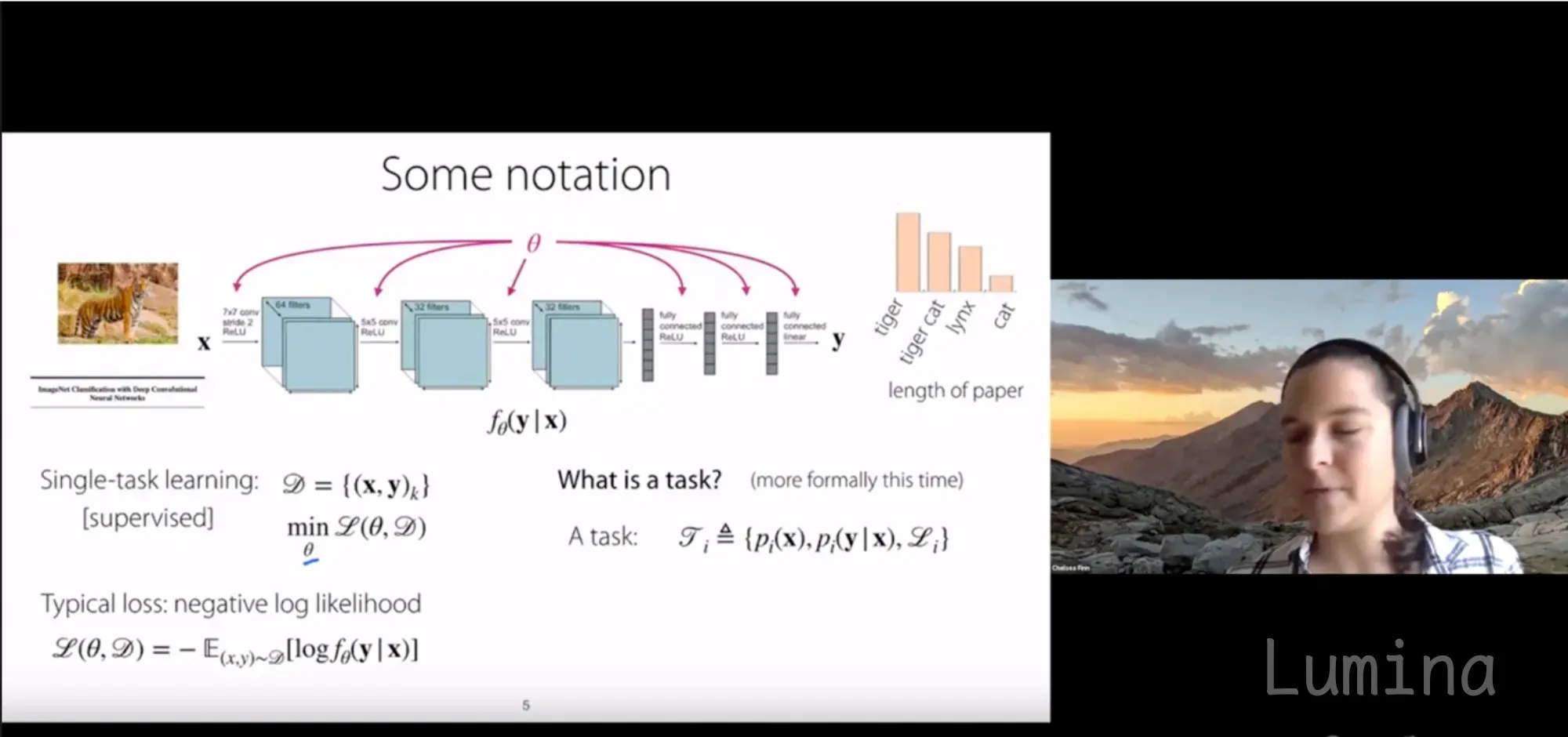
音频
问题
请结合幻灯片内容与口头解说。
列出演讲者提到但未在幻灯片中显示的任何额外要点。
回答
根据演讲者的解说与幻灯片视觉内容,以下是未在幻灯片中明确显示或详细说明的额外要点:
* **主题说明:** 演讲者明确表示将讲解**神经网络中的多任务学习**,而幻灯片标题仅为“一些符号”(尽管包含任务的数学定义)。
* **输出性质:** 她将输出($y$)描述为可能标签(如老虎、虎猫、猞猁、猫)上的**概率分布**,而幻灯片仅显示带类别标签的柱状图,未明确标注该向量为分布。
* **具体任务示例(论文标题):** 她引入一个具体示例,其中输入为**论文标题**,神经网络需估计**论文长度**。幻灯片在柱状图旁标注“论文长度”,但未直观区分论文标题如何映射到这些柱状图,而非表示动物类别。
* **优化技术:** 她提到损失函数通常使用**随机梯度下降**或“最喜欢的优化器”进行优化,这些是幻灯片中未写出的操作步骤(幻灯片仅定义需最小化的损失函数 $\mathcal{L}$)。
* **输入多样性:** 她明确指出输入可以是“广泛的非结构化输入”,特别提到**图像**和**文本**。幻灯片仅显示单张图像(结构化输入),并使用通用变量 $x$ 表示输入类别。
示例 5:声景分析
Nemotron-3 Nano Omni 可分析图像中的图表、图形,并结合音频文件,生成不同媒介间的共性或差异。
音频
问题
该音频中的主要声音是什么?声学环境暗示其录制地点是哪里?
回答
主要声音是鸟鸣,多种鸟叫声及自然开放的声学环境表明录音地点为户外的自然场所,如森林或公园。
示例 6:音乐理解
Nemotron-3-Nano-Omni 可解释并推理一般音频,包括声景与环境音。
音频
问题
这首歌的整体氛围如何?它适合搭配哪种场景?
回答
这首歌氛围宁静、内省,略带忧郁,配以轻柔的钢琴旋律与柔和的弦乐伴奏。它适合搭配安静、沉思的场景,如下雨夜晚、 peaceful 散步或个人反思时刻。
开始使用 Nemotron 3 Nano Omni
参考文献
- NVIDIA Nemotron Nano V2 VL. 技术报告:https://arxiv.org/abs/2511.03929
- NVIDIA Nemotron 3:高效开源智能。技术报告:https://arxiv.org/abs/2512.20856
- C-RADIOv4-H. Hugging Face 模型页:https://huggingface.co/nvidia/C-RADIOv4-H
- Parakeet-TDT-0.6B-v3. Hugging Face 模型页:https://huggingface.co/nvidia/parakeet-tdt-0.6b-v3
- Megatron-LM. GitHub:https://github.com/NVIDIA/Megatron-LM
- Transformer Engine. GitHub:https://github.com/NVIDIA/TransformerEngine
- Megatron Energon. GitHub:https://github.com/NVIDIA/Megatron-Energon