内容
我想到现在是继续探讨我之前两篇文章《即将到来的AI算力瓶颈》和《AI算力瓶颈是否已经到来?》同一主题的好时机,因为OpenAI和Anthropic现在都公开承认自己(非常?)面临着算力短缺的问题。
使用量正在爆炸式增长
我偶然看到GitHub首席运营官发布的一条非常有趣的推文,它真实地反映了世界正在经历的变革规模:
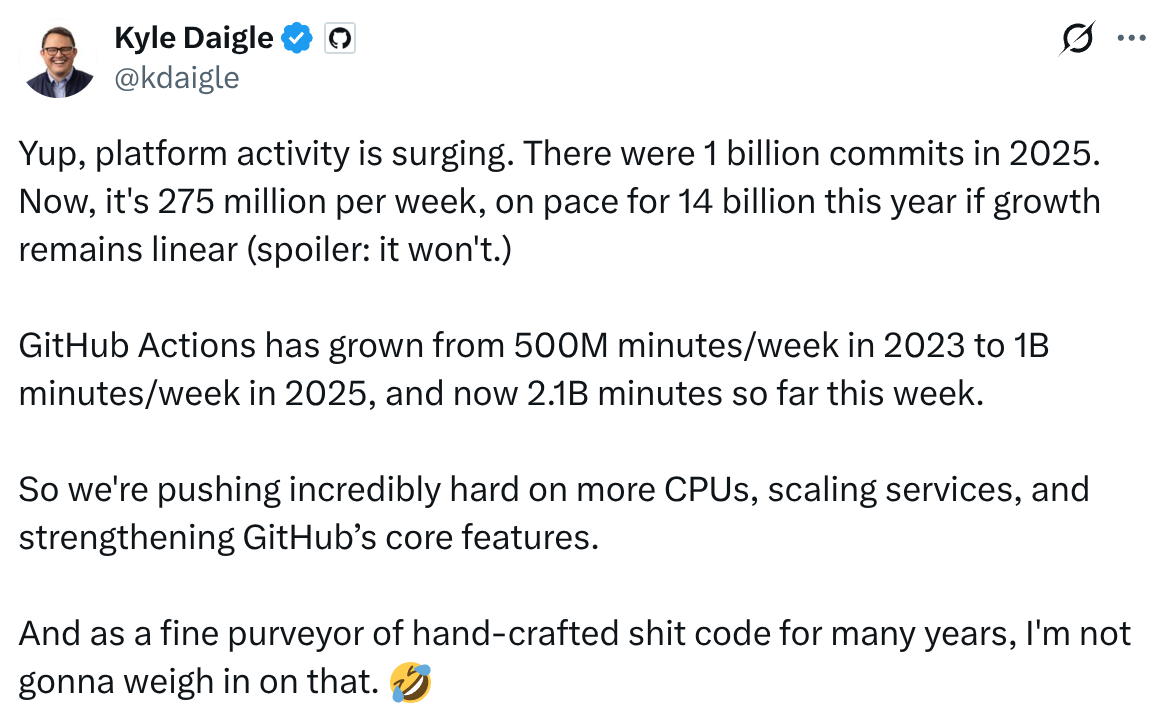
数据显示,GitHub在过去3个月!内提交的代码数量年化增长率达到约14倍。虽然提交量只是对推理需求的一个粗略指标,但即使从方向性来看,如果我们假设大部分增长来自编码代理的普及,这也预示着推理所需的算力需求出现了惊人的增长。
事实上,这可能还是严重低估了——许多刚开始接触" vibe coding "的新手可能不会很快掌握GitHub的使用,分布式版本控制对非工程师来说相当令人困惑(而且,至少对我来说,作为一个工程师,要完全精通它花了比我想象更长的时间)。
此外,这个数字还不包括那些几乎不可能使用GitHub的协同办公场景。
OpenAI的Thibault Sottiaux(Codex团队负责人)最近也在推特上表示,AI公司正经历需求超过供给的阶段:
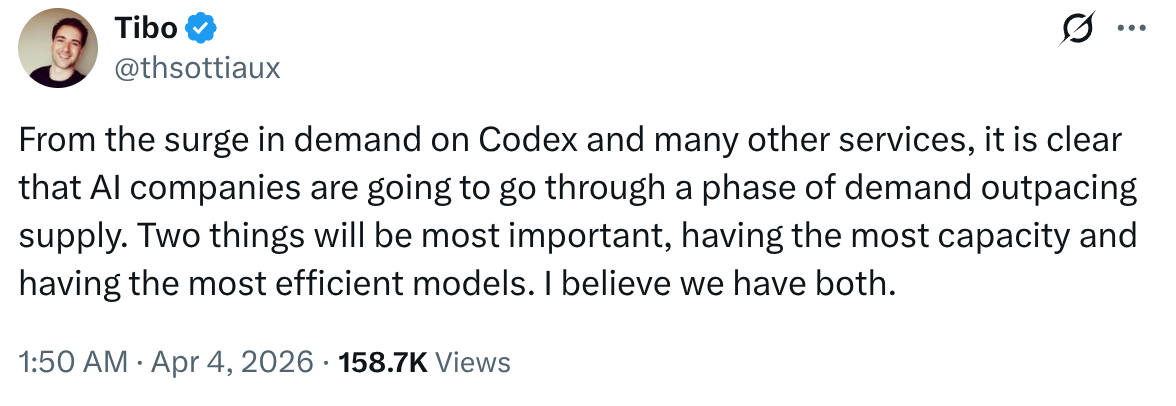
据传闻,考虑到视频生成对算力的巨大消耗,Sora被关闭以释放算力用于其他任务,这在我看来极有可能。
所有AI公司都在深切感受到这种压力。更糟糕的是,这种情况会产生连锁反应——当Claude Code开始收紧使用限制或出现与算力相关的故障时,用户就会转向例如Codex或OpenCode等替代方案,从而给这些平台带来更大的压力。
到底发生了什么?
正如我在上一篇文章中提到的,我认为每个人都以错误的方式看待了2025年左右OpenAI、Anthropic、微软等公司签署的那些"疯狂"算力交易。
签署价值1000亿美元的"承诺"并不会突然创造出相应的算力容量。需要浇筑混凝土,需要连接电力,需要订购燃气轮机[1],还需要制造、上架和网络化GPU。所有这些产品都供不应求,所需的劳动力也同样紧缺。
我认为值得强调但常被忽视的一点是,NVidia最新芯片GB200的部署有多困难。与NVidia以往的产品不同,GB200系列完全采用液冷而非风冷。
在数据中心实现千兆瓦级别的液冷技术之前从未真正实施过。据我所知,这个过程极其痛苦。液冷显著提高了每平方米的功率密度,这使得电气工程变得更加复杂,再加上熟练劳动力的严重短缺[2]来组装所有这些组件,甚至各种高端管道部件的短缺导致GB200的部署进度远远落后于计划。
虽然毫无疑问这些问题最终会得到解决,供应链也会积累经验并提高交付液冷部件的速度,但这无疑在短期内给可用算力带来了更大压力。
更糟的是,阿联酋正在建设的1GW Stargate数据中心现在已成为近期美伊冲突地缘政治紧张局势中的一枚棋子,伊朗政府发布了一段视频展示了施工现场。
我在之前关于此主题的文章中讨论的长期问题是DRAM制造的硬性约束。尽管SK海力士最近与ASML签订了价值80亿美元购买更多EUV生产设备的协议,但这些设备不太可能在未来一两年内投入使用。事实上,我在Sundar Pichai最近的亮相中注意到他特别强调了内存是制约其发展的重大因素。
虽然像TurboQuant这样的最新创新通过KV缓存压缩大幅降低了内存需求,鉴于AI使用量的增长速度,这种方法充其量只能为我们争取到一小段喘息时间。
我相信未来18-24个月将是由算力短缺定义的时期。当需求呈指数级增长而供应端只能线性增加时,市场将变得异常动荡,至少可以说。
裂痕已经开始显现。Anthropic的正常运行时间现在 famously 达到了"1"个九的可靠性水平,而且似乎没有改善的迹象。我不羡慕那些试图在部署新模型和效率策略的同时大规模扩展这些系统的SRE团队所承受的压力。
我们已经看到Anthropic在Claude订阅服务方面采取了越来越严厉的措施——从大幅削减"高峰期"使用限制,到现在禁止第三方代理工具使用claude -p,这无疑是为了减少需求。
问题在于,如果我在文章开头猜测正确,Anthropic的季度推理需求增长了约10倍,那么仅仅通过禁止第三方使用产品所能采取的措施是有限的——第一方使用会迅速消耗掉这些资源。
基于时间的配给制虽然能有效平滑峰谷波动,但也只能起到一定作用。最终你会激励用户全天候满负荷运行算力。这并不是说他们在这里还能做更多事情,但当面临如此巨大的需求增长时,这种做法无法帮助你达到稳定状态。
真正剩下的唯一杠杆就是价格。我在之前的文章中犹豫是否建议大幅提高价格,因为在这次万亿美元竞赛中,市场份额对每个参与者都至关重要,但如果所有AI提供商都面临算力短缺,那么博弈论就会发生变化。
然而这个悖论在于,随着模型变得越来越好——OpenAI和Anthropic关于新"Spud"和"Mythos"模型的传言也指向这一点——用户对价格的敏感度反而降低了。虽然当ChatGPT首次推出Pro订阅每月花费200美元时,感觉几乎是荒谬的昂贵,但我认为每月200美元的Anthropic订阅是我能找到的最佳性价比选择,即使使用当前模型,我也可能会支付更多。
据我所知,我们正处于完全未知的领域。我最近读了很多关于19世纪末至20世纪初欧洲和北美的初始电气化过程,但这个类比很快就站不住脚了——需求增长陡峭得多,供应问题也远没有那么集中。
所以,我们将很快了解人们实际上愿意为随时可用的智能支付多少费用。我的猜测是大多数人预期得少得多——这对行业来说既是极度乐观的信号,也将对短期内的用户造成极大痛苦[3]。
从根本上说,我相信接近或超越人类认知的机器有着近乎无限的潜在需求,即使这种能力在不同领域分布不均。供应最终会跟上。但正是这个"最终"才会造成伤害。