内容
就在几周前,我们推出了 Gemma 4,这是我们迄今为止能力最强的开源模型。仅在最初几周内,Gemma 4 的下载量就超过 6000 万次,为开发者工作站、移动设备和云端带来了前所未有的“每参数智能水平”。今天,我们进一步提升了效率。
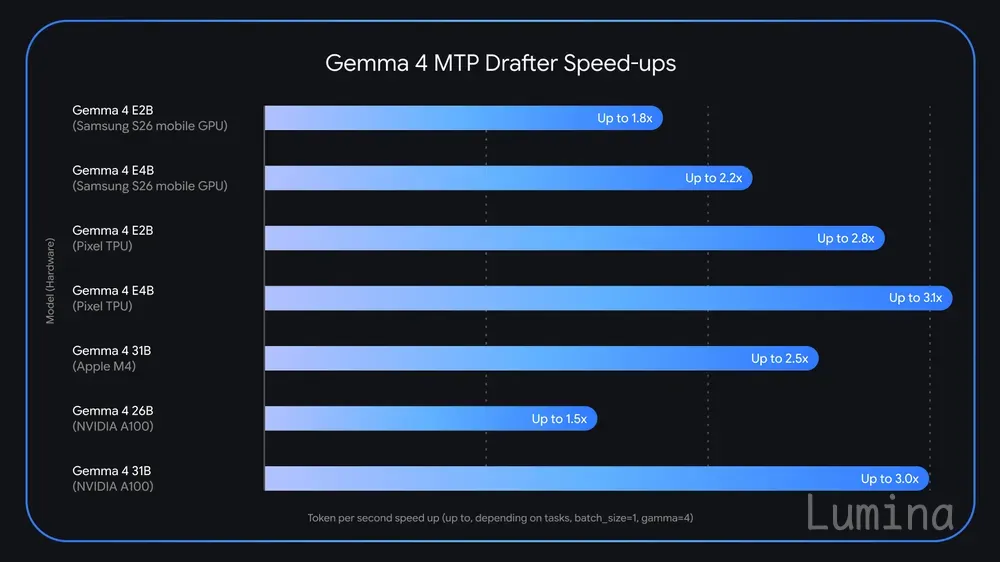
我们为 Gemma 4 系列发布了多令牌预测(MTP)草稿模型。通过采用专门的推测性解码(speculative decoding)架构,这些草稿模型可在不降低输出质量或推理逻辑的前提下,实现高达 3 倍的速度提升。
为何采用推测性解码?
技术现实是:标准大语言模型(LLM)推理受限于内存带宽,形成显著的延迟瓶颈。处理器大部分时间都花在将数十亿参数从显存(VRAM)搬运到计算单元上,只为生成一个令牌。这导致计算资源利用率低下、延迟高,尤其是在消费级硬件上更为明显。
推测性解码将令牌生成与验证过程解耦。通过将 heavyweight 目标模型(如 Gemma 4 31B)与 lightweight 草稿模型(即 MTP 模型)配对,我们可利用空闲的计算资源,让草稿模型在比目标模型处理单个令牌更短的时间内“预测”多个未来令牌。随后,目标模型并行验证所有这些建议的令牌。
推测性解码的工作原理
标准大语言模型采用自回归方式生成文本,一次仅生成一个令牌。虽然有效,但这种方式对预测明显延续(例如在“Actions speak louder than…”后预测“words”)和解决复杂逻辑谜题所投入的计算量是相同的。
MTP 通过推测性解码缓解了这一低效问题——该技术由 Google 研究人员在论文《通过推测性解码实现 Transformer 快速推理》中提出。若目标模型认可草稿内容,则会在一次前向传播中接受整个序列,并在此过程中额外生成一个自己的令牌。这意味着,您的应用在通常生成一个令牌的时间内,可输出完整的草稿序列外加一个令牌。
从边缘到工作站,释放更快的 AI 能力
对开发者而言,推理速度往往是生产环境部署的主要瓶颈。无论您是在构建代码助手、需要快速多步规划的自主代理,还是完全在设备上运行的响应式移动应用,每一毫秒都至关重要。
通过将 Gemma 4 模型与其对应的草稿模型配对,开发者可实现:
- 更优的响应性:大幅降低近乎实时的聊天、沉浸式语音应用和代理工作流的延迟。
- 本地开发性能飞跃:在个人电脑和消费级 GPU 上以空前速度运行我们的 26B 混合专家(MoE)和 31B 密集(Dense)模型,实现流畅、复杂的离线编码和代理工作流。
- 增强的设备端性能:通过在边缘设备上更快生成输出,最大化 E2B 和 E4B 模型的效用,从而延长宝贵的电池续航。
- 零质量损失:由于主 Gemma 4 模型保留最终验证权,您获得的仍是同等级前沿推理能力和准确性,只是速度显著提升。
深入了解 MTP 草稿模型
为使这些 MTP 草稿模型具备极致的速度与准确性,我们在底层引入了多项架构优化。草稿模型无缝利用目标模型的激活值并共享其 KV 缓存,这意味着它们无需浪费时间重新计算大型模型已推导出的上下文。针对 E2B 和 E4B 边缘模型(其最终 logit 计算成为重大瓶颈),我们甚至在嵌入层实现了高效聚类技术,进一步加速生成过程。
我们还深入分析了针对特定硬件的优化。例如,在 Apple Silicon 上,26B 混合专家模型在批处理大小为 1 时面临独特的路由挑战,而同时处理多个请求(如批处理大小为 4 至 8)可在本地实现高达约 2.2 倍的速度提升。在 NVIDIA A100 上增大批处理大小时,我们也观察到类似增益。
想深入了解其具体机制?我们发布了一篇深度技术解析,详细拆解了驱动这些草稿模型的视觉架构、KV 缓存共享机制以及高效嵌入器设计。
如何开始使用
Gemma 4 系列的 MTP 草稿模型现已发布,采用与 Gemma 4 相同的开源 Apache 2.0 许可证。请查阅文档了解如何将 MTP 与 Gemma 4 结合使用。您现可于 Hugging Face、Kaggle 下载模型权重,并立即使用 Transformers、MLX、VLLM、SGLang 和 Ollama 进行更快推理实验,或直接在 Google AI Edge Gallery 上试用 Android 或 iOS 版本。
我们迫不及待想看到,这一全新速度将如何加速您在 Gemmaverse 中的下一次创新。