内容
在我工作的那家 AI 初创公司里,我们正在构建一个金融个人助理。我们接入了 LlamaIndex,加入了 Model Context Protocol(MCP),还搭建了复杂的检索增强生成(RAG)流水线。每增加一个组件,系统复杂度都在上升,但并没有带来直接的业务价值。
当我们把一切剥离回最朴素的 Python、简单的 API 调用,以及一个自定义的 ReAct 引擎后,事情终于运转起来了。我们无意中构建出来的,其实是一个具备专用金融工具、领域特定护栏(guardrails)和面向目标的上下文工程(context engineering)的 harness(执行框架)。
当时我们还不知道这个术语,但教训已经很明确了:问题从来不在模型本身,而在于围绕模型构建的系统和基础设施。
大多数工程团队痴迷于该选哪个模型。他们争论 GPT-4o、Claude Opus 和 Gemini 谁更强,追逐各类 LLM 基准分数,不断切换模型,期待获得更好的结果。
但模型只占方程的一半。真正决定你的智能体能否在生产环境中跑起来的,是围绕它的系统与基础设施。
TerminalBench 2.0 就证明了这一点。仅仅更换 harness,就让 LangChain 的 DeepAgent 从前 30 名之外跃升到前 5 名 [1] 。
通常事情就是这样发生的:你有一个很强大的模型,给了它工具和提示词,它在演示里表现不错。
但一旦要把它真正上线到生产环境,你就得解决一堆模型单靠自己无法处理的问题。你必须跨越上下文窗口限制、从失败中恢复、服务多个交互界面,并在跨会话场景中管理状态。
解决方案就是 harness engineering(框架工程)。这是一门围绕模型构建基础设施的工程学科,目的是让模型能够稳定、可靠地完成有价值的工作。正如 Mitchell Hashimoto 所说,harness engineering 就是在每次智能体犯错时,工程化地构建一个解决方案,确保它以后再也不会犯同样的错 [2] 。
读完这篇文章后,你将了解:
- 智能体 harness 到底是什么。
- 支撑生产级 AI 系统的核心组件。
- 规划循环(planning loop)如何决定智能体的动作。
- 高效工具集背后的设计原则。
- 如何利用文件系统管理记忆。
在我们拆解它的所有组件以及它们如何协同工作之前,必须先给 harness 下一个定义。
大多数工程师都懂智能体、上下文工程和 RAG 的理论。他们真正欠缺的,是在生产环境中架构、评估并部署这些系统的信心。与 Towards AI 合作打造的 Agentic AI Engineering 课程 ,通过 34 节课程(文章、视频以及大量代码)弥合了这道鸿沟。
学完之后,你将从 “我做了一个 Demo” 迈向 “我交付了一个具备评测(evals)、可观测性(observability)和 CI/CD 的生产级多智能体系统。” 课程还包含 3 个作品集项目、一张可在面试中证明实力的证书,以及一个可直接接触行业专家的 Discord 社区。
已有 300 多位早期学员给出 5/5 ⭐️ 评分,评价包括 “每个 AI 工程师都需要这样的课程”,以及 “这是从实验性 LLM 项目走向真实世界 AI 工程的绝佳桥梁。”
今天就开始学习。前 6 节课免费:
和 Manning 的 Jonathan Gennick 聊天时,他说自己第一次听到 “harness” 这个词,是在马具的语境里。让我解释一下:马本身很有力量,但如果没有 harness(挽具/马具),它对耕作毫无用处。缰绳和皮带能把它的力量导向真正有用的工作。LLM 也是一样。
模型拥有智能,但如果没有工具、记忆、状态、护栏和编排机制,你就无法让它稳定地投入实际工作。
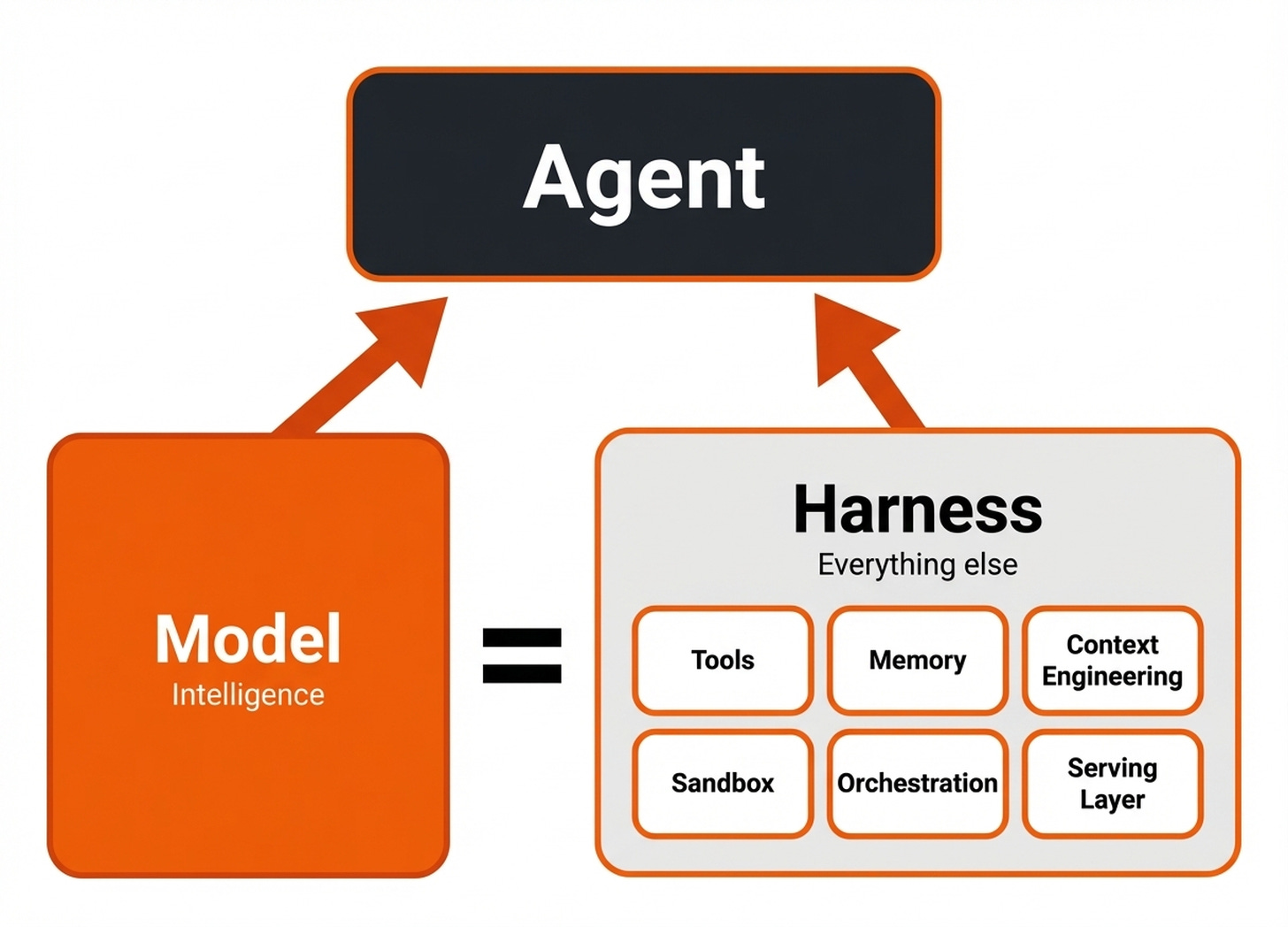
LangChain 给出了最清晰的定义:一个智能体 = 模型 + harness。 Harness 指的是除了模型本身之外,所有代码、配置与执行逻辑 [1] 。
截至目前,我们熟悉的基础智能体,不过是模型、提示词、工具和一个规划循环。Harness 则在此基础上进一步扩展,加入了记忆系统、护栏、高级编排、上下文工程,以及多智能体协作。
通常,它还包含一个服务层(serving layer),用于把智能体连接到各种用户界面,例如终端应用、Web 仪表盘、IDE 插件,以及 Telegram 之类的消息应用。
归根结底,harness 这个术语指的是:把 LLM 或其他模型当作操作系统,用来构建真正的软件应用。像 Claude Code、OpenCode、OpenClaw 和 Codex 这样的应用,本质上都是 harness。你可以替换它们内部的模型,但真正的工程价值,存在于 harness 本身。
 图片 2:工程的三个层次:提示词工程负责打造指令,上下文工程负责管理模型看到的内容,而 harness 工程则是完整的基础设施。
图片 2:工程的三个层次:提示词工程负责打造指令,上下文工程负责管理模型看到的内容,而 harness 工程则是完整的基础设施。
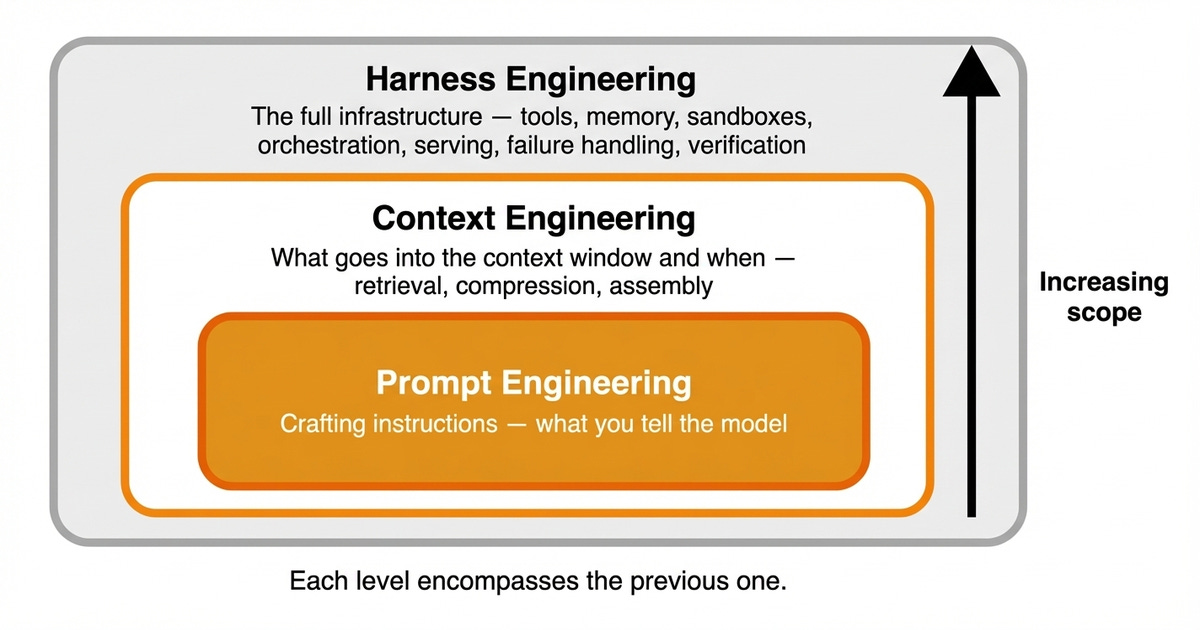
这引出了三个彼此不同的工程层次。提示词工程负责构造指令;上下文工程决定什么内容在何时进入上下文窗口。
Harness 工程则是完整的应用与基础设施。它控制上下文何时加载、哪些工具可用、允许执行哪些动作,以及失败如何处理。每一个层次都包含了前一个层次 ▶ [3] 。
现在你已经理解了 harness 是什么,下一步就是探索它的内部架构,看看这些组件是如何连接起来的。
一个完整的 harness 由 LLM、工具、规划循环、上下文工程、沙箱、记忆、编排层和服务层组成。换句话说,AI 领域里这些一直“悬浮”着的概念,终于汇聚成了一个漂亮的完整系统。
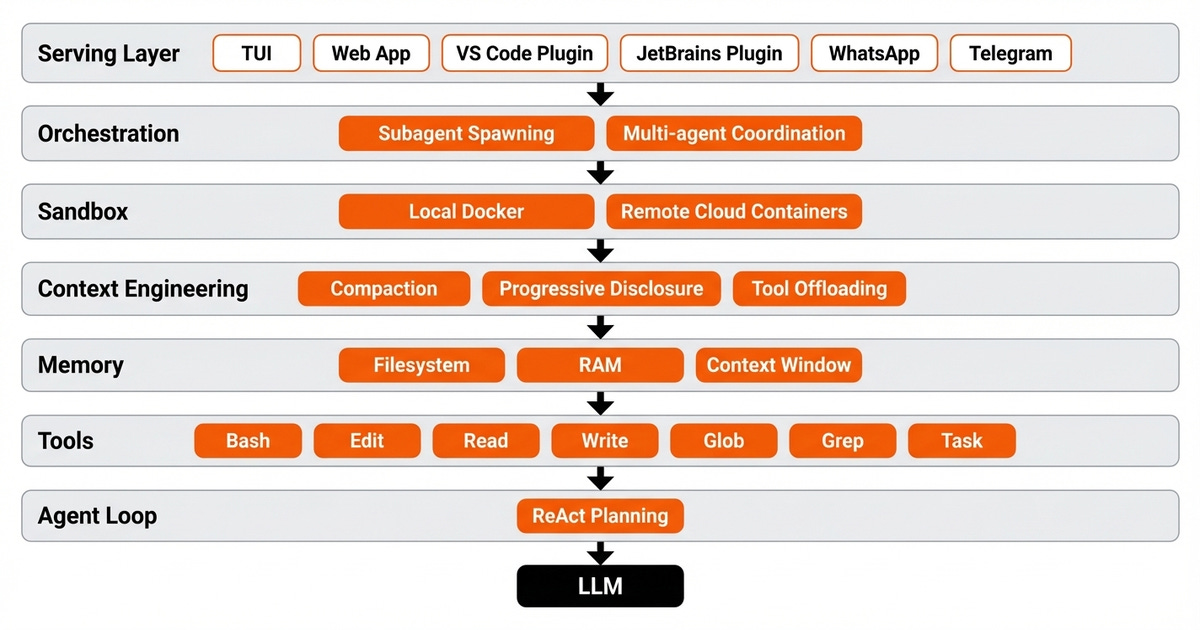 图片 3:完整的 harness 架构——从中心的模型到边缘的服务层。
图片 3:完整的 harness 架构——从中心的模型到边缘的服务层。
现代 harness 最显著的特征之一,是多表面(multi-surface)架构。OpenClaw 通过一个集中式 Gateway 和类型化的 WebSocket 协议,把同一个智能体同时服务于命令行界面(TUI)、Web UI、桌面应用、Slack 以及 Telegram/WhatsApp。
Codex 则从一个简单的终端工具,演化成了一个通过标准输入输出上的 JSON-RPC 提供服务的 App Server。OpenCode 使用的是一个 Bun JS HTTP 服务器,任何客户端都可以通过 HTTP 接入,并借助 Event Bus 实时广播结果 [4] , [5] , [6] 。
这样的架构也带来了挑战:来自不同客户端的多条消息会并行到达;用户会在模型仍在处理时继续提问。
为了解决这个问题,系统会使用优先级队列和消息总线。OpenClaw 使用了一个具备 lane-aware 能力的 FIFO 队列,确保每个会话同一时刻只有一个活跃运行任务,同时允许不同会话之间并行执行。
而在所有这些基础设施的核心,文件系统才是真正的王者。作为最基础的 harness 原语(primitive),它支撑了持久化存储、工作区管理、多智能体协作以及版本管理。
没错,你没听错,这里并没有什么花哨的向量数据库。AI 让我们重新回归基础,而没有什么比文件系统本身更纯粹。
每个生产级 harness 都把文件系统作为其主要状态机制 [1] 。
你可能会问,这是不是只是像 Airflow 那样的传统编排?其实不同,关键有三点:智能体循环是非确定性的;上下文管理是一等公民;而循环内部的“程序员”其实就是 LLM 本身。人们通常还会借助 Prefect、Temporal 或 DBOS 这样的工具为 harness 增加持久性,因为这些工具原生支持动态流水线,而不是预先定义、僵硬固定的 DAG。
接下来,让我们聚焦第一个、也是最基础的组件:规划循环。
规划循环最常见的模式是 ReAct,也就是 Reasoning and Acting(推理与行动)。模型接收当前状态,推理下一步该做什么,通过工具调用执行动作,再观察结果。这个循环会持续重复,直到满足一个严格的停止条件 [5] 。
来看一个具体例子。用户让智能体修复一个失败的测试。第一步,模型读取测试输出,推理出 import 路径错误,于是通过工具修改文件。
第二步,它重新运行测试,看到一个新的类型不匹配错误,然后修复它。第三步,它再次运行测试。
测试通过了,模型判断任务已完成,于是停止。Harness 负责编排整个循环,而模型负责推理并选择动作。
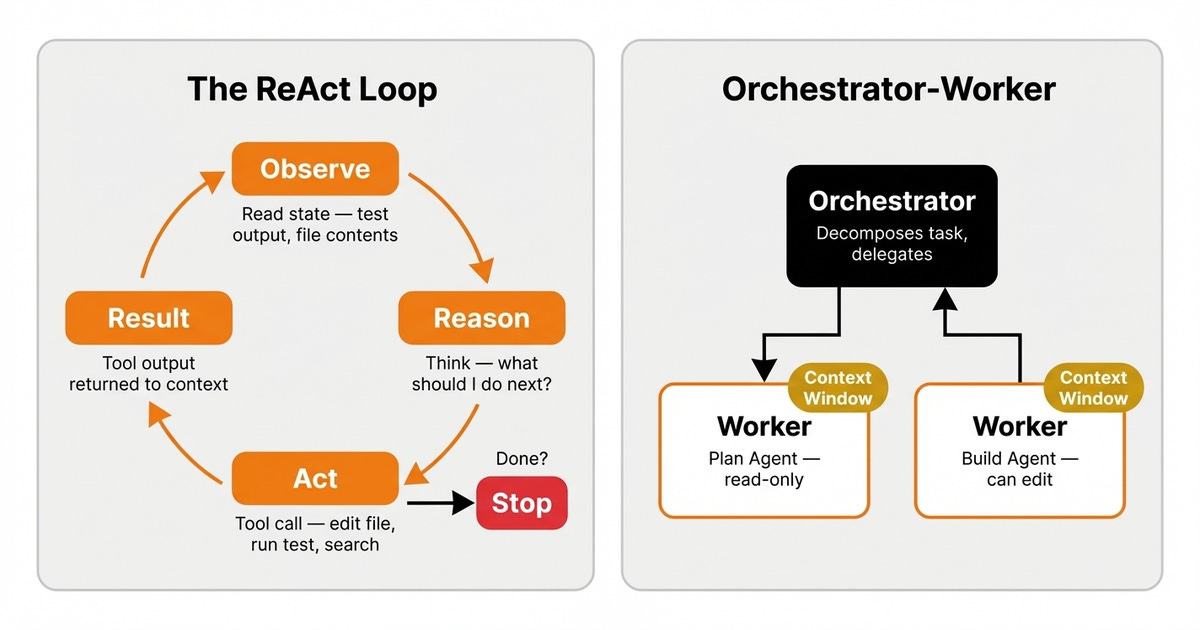 图片 4:ReAct 循环驱动着智能体的每一次动作。对于复杂任务,编排器会把工作委派给专门的工作智能体,每个都拥有自己的上下文窗口。
图片 4:ReAct 循环驱动着智能体的每一次动作。对于复杂任务,编排器会把工作委派给专门的工作智能体,每个都拥有自己的上下文窗口。
当任务复杂到单个智能体无法胜任时,harness 会采用 orchestrator-worker(编排器-工作者)模式。编排器负责拆解任务,把子任务分发给专门的工作者,再汇总结果。
在 OpenCode 中,专门的 task 工具会生成子智能体。每个子智能体都有自己的会话、上下文窗口以及受限的工具集 [7] 。
对于跨越多个上下文窗口的任务,Claude Code 实现了 Ralph Loops。这种 harness 机制会通过 hook 拦截模型试图退出的动作,然后在一个干净的上下文窗口中重新注入原始提示词,借助持久化在文件系统上的状态,强制智能体继续朝着完成目标推进 [1] 。
在我用智能体自动化业务的过程中,我在编排问题上学到了一课,而且代价不小。起初我构建了 5 个专门化智能体,每个负责一个步骤。
但最后我发现,一个拥有记忆能力和聪明上下文工程的单智能体,反而比整套“蜂群”表现得更好。面对问题时,永远先从一个 harness 做得足够好的单智能体开始,而不是急着引入多智能体复杂性。
下面是关于规划的深入解析:
虽然规划循环决定下一步做什么,但智能体仍然需要一种方式与其环境交互。
这种交互通过一套专门为自主执行设计的工具集来实现。
首先,Bash 是一个通用工具。智能体可以运行任意 shell 命令来执行测试、linter 或构建任务。这赋予了模型代码执行能力,使它可以动态设计自己的工具,而不是受限于固定选项。
例如,智能体可以生成 Python 代码,并通过 python -c "..." 执行;也可以生成一个脚本,通过 python main.py 运行;或者将你的代码作为 python -m my_module.main 来执行。
其次,专门的文件系统工具负责处理常见操作,比如读取、写入、编辑和搜索。通过 Bash 来做文件操作既慢又容易出错。
专门工具通常还包含安全检查。例如,读取工具会强制使用绝对路径并限制行数,而编辑工具会校验待替换字符串的唯一性。
第三,状态管理工具用于跟踪会话范围内的任务。这些工具为智能体提供了单次会话内的工作记忆。例如,OpenCode 提供了 ToDoAdd 和 ToDoRead 工具,用于向队列中添加/读取任务,从而追踪它需要执行的计划。
最后,编排工具可以启动拥有各自隔离提示词和上下文窗口的子智能体,比如 OpenCode 的 task 工具或 Claude Code 的 agent 工具。
 图片 5:按设计原则组织的标准 harness 工具集——从通用的 bash,到专门的文件系统工具,再到编排工具。
图片 5:按设计原则组织的标准 harness 工具集——从通用的 bash,到专门的文件系统工具,再到编排工具。
反馈回路(feedback loop)是工具设计中最重要的原则。Claude Code 的创造者 Boris Cherny 指出,给模型一个验证自己工作的途径,能将质量提升两到三倍。比如,OpenCode 集成了 Language Server Protocol(LSP),以获取实时代码定义和诊断信息。
未定义变量和类型错误会被立即反馈给 LLM,以便它马上修正。这类工具并不直接作用于外部世界,而是把关键反馈重新送回规划循环。
Harness 还会强制执行工具访问控制。在 OpenCode 中,规划智能体不能调用编辑工具。这能防止探索型智能体意外修改你的代码 [5] 。
下面是关于工具调用的深入解析:
当智能体拥有了工具后,它还需要一个安全的地方来使用这些工具。在生产环境中,这意味着必须有严格的隔离机制。
智能体会执行代码,而代码可能失败、崩溃,甚至删除你所有的文件。我知道,我自己也希望那些珍贵笔记能被保护好。沙箱会隔离智能体的执行,因此失败不会影响宿主系统或其他智能体。锦上添花的是,它还支持跨并行环境的水平扩展。
安全性与能力之间存在严格的权衡。并不是每个 harness 都采用同样的方法。Codex 使用的是硬沙箱(hard sandbox)。
每个任务都运行在一个预先加载了代码仓库的隔离云容器中。这种方式安全性最高,但智能体无法访问宿主文件系统 [6] 。
相对地,OpenClaw 使用的是软沙箱(soft sandbox)。工作区就是默认工作目录。
这提供了最大的能力,但也带来了更高风险。
OpenClaw 有意避免使用硬沙箱,以保留对完整文件系统的访问。大多数生产级 harness 都落在这两个极端之间,具体取决于其信任模型。
当你向 Codex 提交一个任务时,harness 会启动一个全新的云容器。智能体在这个容器中读取文件、运行测试、安装依赖包。
它无法触碰你的本地机器。任务完成后,结果会被提取出来,而容器则会被销毁。
除了安全性,云沙箱环境的另一个重要优势在于,它能为智能体提供强大的计算资源。例如,如果你想用 GPU 训练一个模型,你可以让智能体在一个由 GPU 驱动的沙箱中实现并运行训练流水线。
这有点像你手动 SSH 到不同的虚拟机上,再在那里手动执行代码。基于同样的原则,你也可以轻松拉起多个云沙箱,并让你的智能体并行运行。
而在光谱的另一端,你也可以像 Cursor 那样,通过 Docker 容器或隔离进程在本地运行沙箱环境。当你只是想尝试一些东西,并希望给智能体完整权限以避免持续人工监督时,这会非常实用。
不过,虽然沙箱为执行提供了安全空间,但它们从设计上就是短暂易失的。
为了跨会话和跨上下文窗口生存下来,每个 harness 都会在三层不同的记忆层中管理状态。第一层是文件系统,这是长期记忆。
它是持久且可持续存在的,能够跨越多个会话。进度文件、git 历史和会话记录都保存在这里。
第二层是 RAM,也就是短期记忆,也称工作记忆。它在活跃会话期间保存对话历史和工具结果。它速度很快,但不持久。
第三层是上下文窗口。这才是模型真正“看到”的内容。它是最严格的约束,因为模型当前任务所知道的一切,都必须塞进这里。
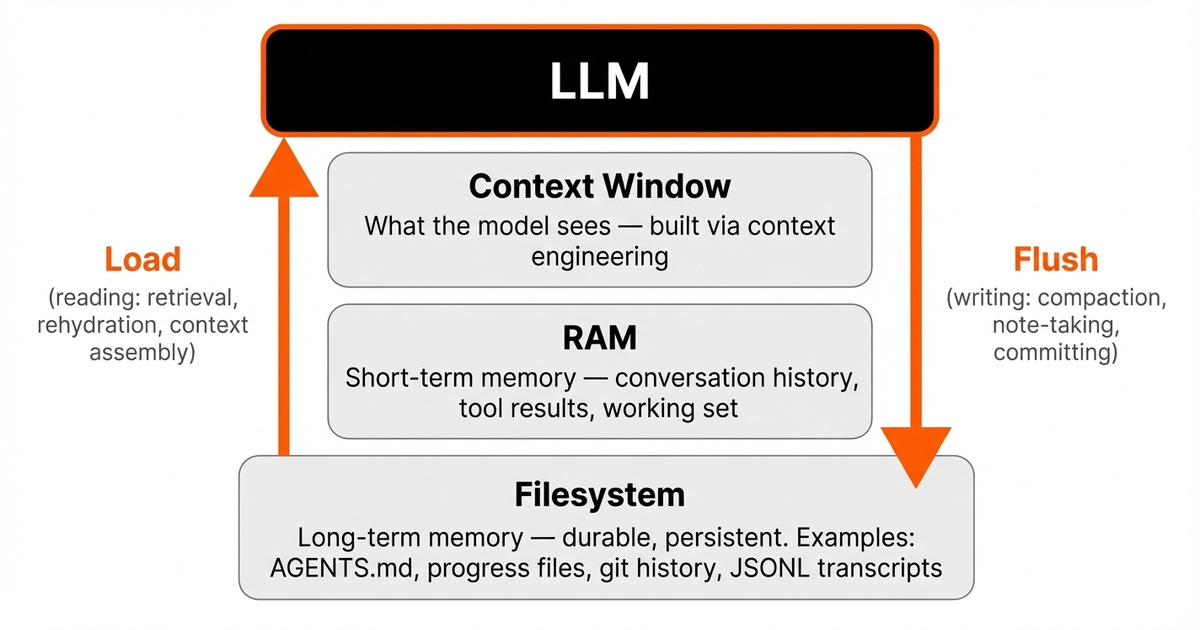 图片 6:三层记忆的动态关系——文件系统作为长期状态,RAM 作为工作记忆,上下文窗口则是模型看到的内容。整个循环不断重复:加载 → 处理 → 刷新。
图片 6:三层记忆的动态关系——文件系统作为长期状态,RAM 作为工作记忆,上下文窗口则是模型看到的内容。整个循环不断重复:加载 → 处理 → 刷新。
Harness 负责编排这些层之间的动态流转。在读取路径上,harness 会有选择地把磁盘上的相关状态加载到 RAM 中。
随后,它会使用上下文工程技术——例如压缩(compaction)、渐进式披露(progressive disclosure)和即时检索(just-in-time retrieval)——来组装上下文窗口。而在写入路径上,harness 会在处理完成后,把重要状态持久化回磁盘。
OpenClaw 强制执行一个严格不变式:记忆在从上下文中丢弃之前,必须先刷新到磁盘。重新水化(rehydration)被视为一种“工具形态”的动作,即由智能体先搜索,再检索特定数据,而不是把所有内容一股脑塞进上下文窗口 [8] 。
上下文工程正是实现这一切的关键。当 token 数量超过限制的 90% 时,OpenCode 会自动总结对话。Codex 会从多个来源组装提示词,并利用提示词缓存(prompt caching)。
Anthropic 建议使用结构化的笔记文件,以及子智能体架构来隔离上下文 [5] , [6] , [9] 。
在 Anthropic 的长时运行智能体模式中,一个初始化智能体会创建脚本、进度文件和特性列表。编码智能体会在每次会话开始时读取 git 日志和进度文件,并在推进过程中更新进度文件。
妙处就在于:这里没有数据库,也没有向量存储。只有文件系统 [10] 。
下面是关于记忆的深入解析:
现在你已经看到了所有这些部件——从规划、工具到沙箱和记忆——接下来的问题是:这对于我们构建软件的方式意味着什么?
我们正在见证一种全新的软件构建方式。过去是软件工程师构建传统的前端和后端应用,而下一代生产级软件将会是 harness。Harness 工程正在把软件工程与 AI 融合,并将其提升到一个更高层次 ▶ [3] 。
像 Claude Code 这样的流行工具,只是一个开端。从长远看,没有哪家公司会愿意完全依赖专有 harness。即便是 OpenCode 这样的开源方案,也不可能覆盖每一个特定用例。
公司最终必然会自己构建。正如我们在 ZTRON 的经历所表明的那样,真正让智能体在生产环境中跑起来的,最终还是定制化的系统与基础设施。
不过,我们也必须坦诚面对当前的限制。记忆在长会话中依然会失效;验证循环仍然会漏掉边界情况;此外,如何在共享代码库上编排数百个并行智能体,仍然是一个开放的研究问题。
Harness 工程是真正的工程。你的 harness 会变成一个独立产品,它有自己的 bug、自己的漂移问题,以及自己的维护负担。
你怎么看?你同意、不同意,还是觉得我遗漏了什么?
如果你喜欢这篇文章,最真诚的赞赏方式就是分享我们的内容。
从零构建到生产级 AI 智能体,欢迎加入 Agentic AI Engineering 自学课程 。课程由 Towards AI 合作打造。
通过 34 节课程(文章、视频和大量代码),你将端到端地设计、构建、评估并部署生产级 AI 智能体。到最后一课时,你将构建出一个多智能体系统,并完成一个毕业项目(capstone project),把所学内容真正独立应用起来。
3 个可用于作品集展示的项目,以及一张可在面试中展示的证书。此外,你还可以加入 Discord 社区,直接接触其他行业专家以及我本人。
已有 300 多位学员给出 4.9/5 ⭐️ 评分,并表示 “每个 AI 工程师都需要这样的课程。”
还没准备好立即投入? 我们还准备了一门免费的 6 天邮件课程,揭示 6 个会悄无声息摧毁智能体系统的关键错误。领取免费邮件课程。
- LangChain.(2026 年 3 月 21 日). The Anatomy of an Agent Harness. LangChain Blog. ▶ https://blog.langchain.com/the-anatomy-of-an-agent-harness/
- Hashimoto, M.(2026 年 3 月 25 日). My AI Adoption Journey. Mitchell Hashimoto. ▶ https://mitchellh.com/writing/my-ai-adoption-journey
- Bouchard, L.(2026 年 3 月 25 日). What Harness Engineering Actually Means. What's AI by Louis-François Bouchard. ▶ https://youtube.com/watch?v=zYerCzIexCg
- Govindarajan, V.(2026 年 3 月 21 日). OpenClaw Architecture Part 1 - The Agent Stack. The Agent Stack. https://theagentstack.substack.com/p/openclaw-architecture-part-1-control
- Abboud, M.(2026 年 3 月 17 日). How Coding Agents Actually Work: Inside OpenCode. Moncef Abboud. ▶ https://cefboud.com/posts/coding-agents-internals-opencode-deepdive/
- ByteByteGo.(2026 年 3 月 26 日). How OpenAI Codex Works. ByteByteGo. https://blog.bytebytego.com/p/how-openai-codex-works
- Anthropic.(2025 年 12 月 24 日). Building Effective AI Agents. Anthropic. ▶ https://www.anthropic.com/research/building-effective-agents
- Govindarajan, V.(2026 年 3 月 24 日). OpenClaw Architecture Part 3: Memory and State Ownership. The Agent Stack. https://theagentstack.substack.com/p/openclaw-architecture-part-3-memory
- Anthropic.(2025 年 10 月 22 日). Effective Context Engineering for AI Agents. Anthropic. ▶ https://www.anthropic.com/engineering/effective-context-engineering
- Anthropic.(2026 年 3 月 25 日). Effective Harnesses for Long-Running Agents. Anthropic. ▶ https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
如无特别说明,所有图片均由作者创作。