技术博客 全部文章
浏览 技术博客 分类下的公开文章、摘要与延伸阅读。肖恩子的知识花园
 英文
英文现代浏览器的工作原理
文章系统拆解现代浏览器工作机制,以 Chromium 为主线说明网络加载、HTML/CSS/JS 解析、样式计算、布局、绘制、合成、GPU 渲染、V8 执行、模块加载、多进程架构与站点隔离,并对比 Gecko 与 WebKit 差异,结论是理解这些内部流程有助于优化页面性能、稳定性与安全性。
Cursor 如何索引你的代码库?
Cursor用语义向量索引与本地稀疏n-gram正则索引协同检索代码:AST切块、自训练嵌入模型、Turbopuffer按代码库命名空间存储,Merkle树只同步变更并提供访问证明,simhash复用团队索引,动态上下文按需读取文件,最终在超大仓库中显著降低首次查询、搜索延迟、成本与Agent token消耗。
 英文
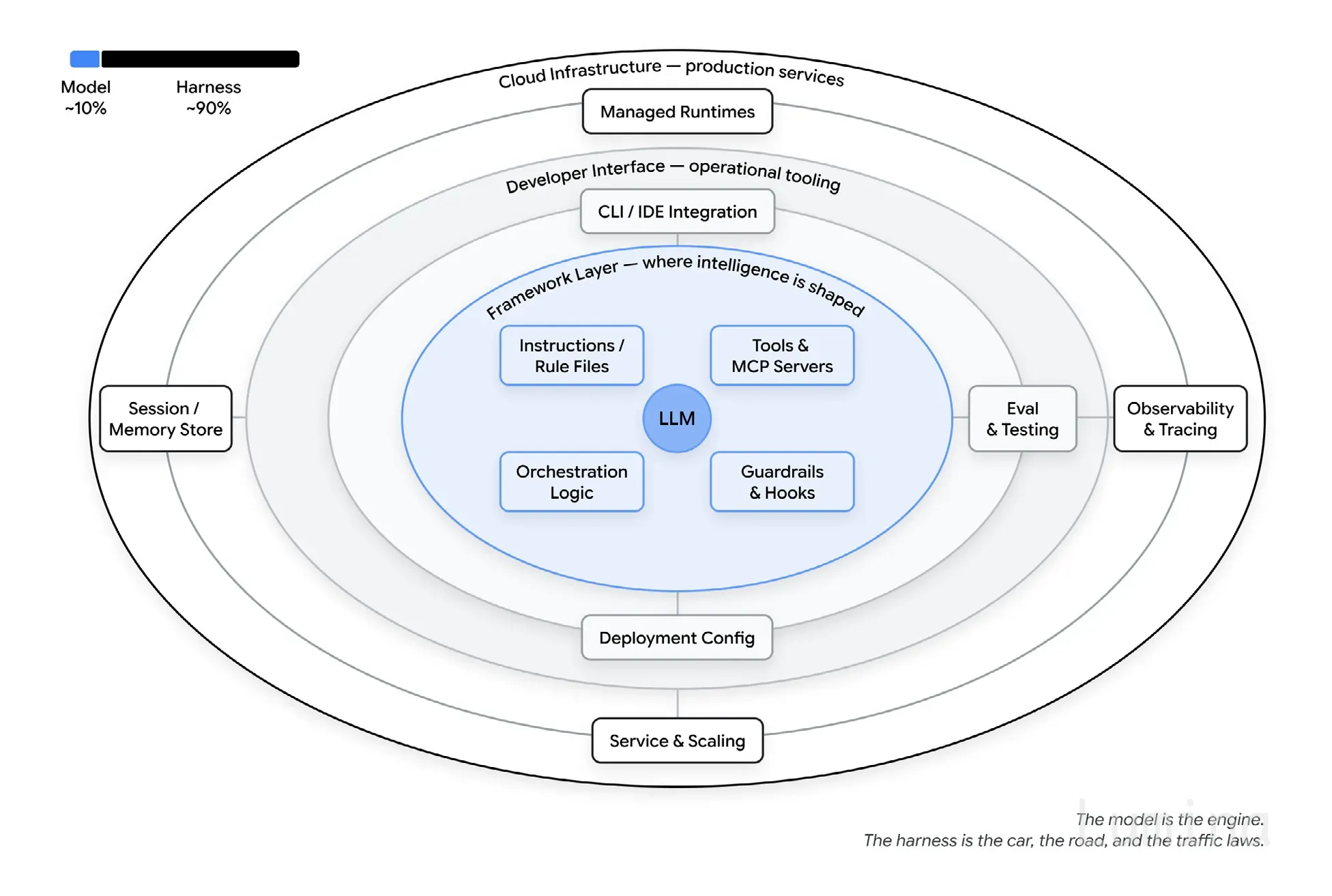
英文构建可靠的智能体式人工智能系统
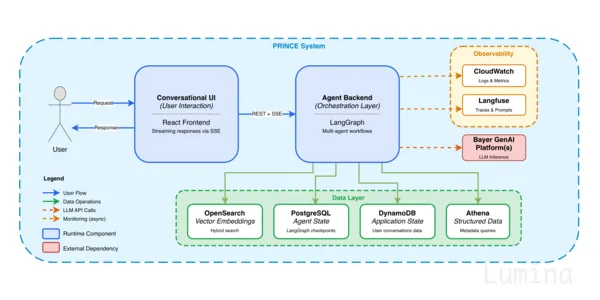
拜耳开发PRINCE,将临床前研究数据从结构化检索升级为自然语言问答和任务执行系统,结合Agentic RAG、Text-to-SQL、多代理编排、引用验证、监控评估、状态恢复和模型兜底,打通PDF报告与元数据,提升数据可访问性、可信度和研究效率;核心经验是生产级智能体不只靠模型,而依赖严格的上下文工程与可控工作流。



 英文
英文借助动态工作流大规模编排子代理
Dynamic workflows 是 Claude Code 的脚本化多代理编排能力,由 Claude 为任务生成 JavaScript 工作流并在后台执行,适合代码库审计、大规模迁移、交叉验证研究等需要数十到上百代理的任务;用户可通过 `/deep-research`、提示中加入 ultracode、或 `/effort ultracode` 启动,可审批、查看、暂停、恢复、停止、保存为命令并复用;其优势是把计划、分支和中间结果放进脚本而非上下文,提高可重复性、规模和可靠性,但会消耗更多 tokens,并受并发16个代理、单次最多1000代理等限制。