内容
我第一次构建语音代理并与其通话时,感觉就像在2003年通过卫星电话与人交谈一样。长时间的停顿、不自然的语调、偶尔还会出现打断——它自顾自地说下去,完全不顾我是否在说话。同一产品的文本版本还能用,但语音版本根本没法用。那一刻我意识到:文本工程和语音工程根本不是一回事。
一旦引入音频,你面对的就是一个本质上完全不同的延迟模型、不同的故障模式,以及一套与任何基于文本的系统都不同的权衡取舍。语音代理绝不只是“给大语言模型(LLM)加个扬声器”那么简单。它们是一整套处理流水线,而这条流水线的每一个环节都在与同一个约束条件对抗:时间。
本文将深入探讨语音代理流水线的工作原理、级联模型与端到端语音模型之间的架构选择、你所面临的延迟预算、全双工(full-duplex)的含义及其实现难度,以及决定你的语音代理听起来自然还是机械的关键设计决策。
三阶段流水线
最常见的语音代理架构,核心由三个顺序执行阶段组成。
语音转文本(Speech-to-Text, STT) 将麦克风采集的原始音频转换为LLM可处理的文本。目前主流方案包括:OpenAI Whisper(开源、精度极高,但延迟较高)、Deepgram(低延迟流式转录,已在生产环境中验证)、AssemblyAI(精度良好,支持流式处理),以及其他少数几家。关键指标不仅仅是词错率(WER),更重要的是转录生成时间——产生一段转录所需的时间。一段准确率达98%但耗时800毫秒的转录,通常比一段95%准确率但仅需150毫秒的转录更糟糕。
大语言模型(LLM) 是“大脑”。它接收转录文本,结合上下文和记忆,生成回复。这里可以使用与文本场景相同的模型,但提示结构必须调整:语音对话轮次更短、语气更随意,模型绝不能输出Markdown、编号列表或大段文字。每一条回复都必须能自然地朗读出来。
文本转语音(Text-to-Speech, TTS) 将LLM生成的文本回复转换为音频。选项范围从老旧、机械的系统,到听起来几乎与人类无异的现代神经TTS,如ElevenLabs、Cartesia(延迟极低)、OpenAI TTS、PlayHT等。在生产环境中,最重要的指标是首块音频生成时间——用户多久后才能听到任何声音。
将这三个阶段拼接起来并不复杂,但要让它们无缝衔接却非常困难。
级联模型 vs. 端到端语音模型
在深入探讨级联流水线之前,你需要了解:如今还存在另一类架构家族,而它在18个月前几乎还不存在——那就是端到端语音模型。
级联模型就是我们刚才描述的流程:STT将音频转为文本,LLM生成文本回复,TTS再将文本转回音频。这种架构的优势在于对每个阶段拥有完全控制权、可观测性强,且可以独立替换组件。但代价是延迟(每个阶段都会增加时间,且无法总是完美重叠)、上下文丢失(LLM听不到语气或犹豫,只能看到转写的文字),以及情感表达更扁平(LLM不知道用户是否沮丧,TTS也无法自然地根据内容做出反应)。
端到端语音模型则完全跳过了转录步骤。模型直接接收音频输入,并直接输出音频。OpenAI的Realtime API(基于GPT-4o)、Kyutai的Moshi和Sesame的CSM是其中的典型代表。由于没有STT和独立的TTS步骤,延迟显著降低。Moshi报告的响应延迟在200–300毫秒范围内,比任何级联系统都更接近人类对话的自然节奏。此外,韵律(prosody)和情感表达也更好,因为模型直接处理音频,无需通过文本“压平”信息。
但代价是你放弃了级联系统大部分可工程化的特性。你无法轻易检查模型“听到了什么”。下个季度也无法简单地换一个更好的STT组件。工具调用和结构化输出能力更弱,因为这些功能必须编码到音频模态中,而非作为文本处理。而且目前每分钟对话的成本远高于在级联架构中运行一个小型快速LLM。
对于2026年大多数生产环境中的语音代理(如客服、电话系统、现有系统的语音前端),级联仍是更合适的架构。其控制面、可观测性以及组件生态的成熟度, 胜过端到端模型的延迟优势。但对于那些更重视自然对话而非精确工具调用的场景(如陪伴机器人、语言辅导、免提助手),端到端模型正变得真正具有竞争力。在决定采用哪种架构之前,了解两者并存的事实至关重要。
本文其余部分将聚焦于级联架构,因为它的工程挑战最为丰富。
延迟预算
要使语音对话感觉自然,从用户说完一句话到听到回复的第一个词,整个往返时间必须控制在约500–800毫秒以内。超过这个范围,用户就会察觉到延迟;超过1.5秒,体验就会显得支离破碎。因此,你通常是在与时间赛跑,才能让语音代理显得自然。
让我们分解一个 naive 的顺序实现中,时间都花在了哪里:
| 阶段 | 典型延迟 |
|---|---|
| 音频采集 + VAD 结束检测 | 100–300ms |
| STT 转录 | 150–400ms |
| LLM 首 token 时间(TTFT) | 300–800ms |
| TTS 首块音频 | 100–300ms |
| 网络开销 | 50–150ms |
| 总计 | 700ms–1.95s |
即使在最乐观的情况下,你也已经处于可接受范围的边缘;而在最悲观的情况下,感觉就像在跟一个信号极差的电话那头的人说话。这就是为什么语音代理本质上是一个延迟工程问题,而不仅仅是一个AI问题。最优秀的语音体验,是由那些将毫秒视为一等工程要素的团队打造出来的。
解决方案并非孤立地让每个阶段更快(尽管这有帮助)。真正的突破口在于流式处理(streaming),使得各阶段可以重叠运行,而非严格串行。
流式处理:赢得延迟竞赛的唯一方式
在一个 naive 的流水线中,你需要等待用户说完、等待完整转录、发送给LLM、等待完整回复,再全部传给TTS。这是完全串行的,延迟会不断累积。
而在流式流水线中,一旦LLM开始生成 token,你就立即启动TTS,无需等待完整回复。LLM逐 token 流式输出,TTS系统消费这些 token,并实时合成音频,通常会缓冲5–15个 token 后再生成第一块音频,以避免频繁启停。
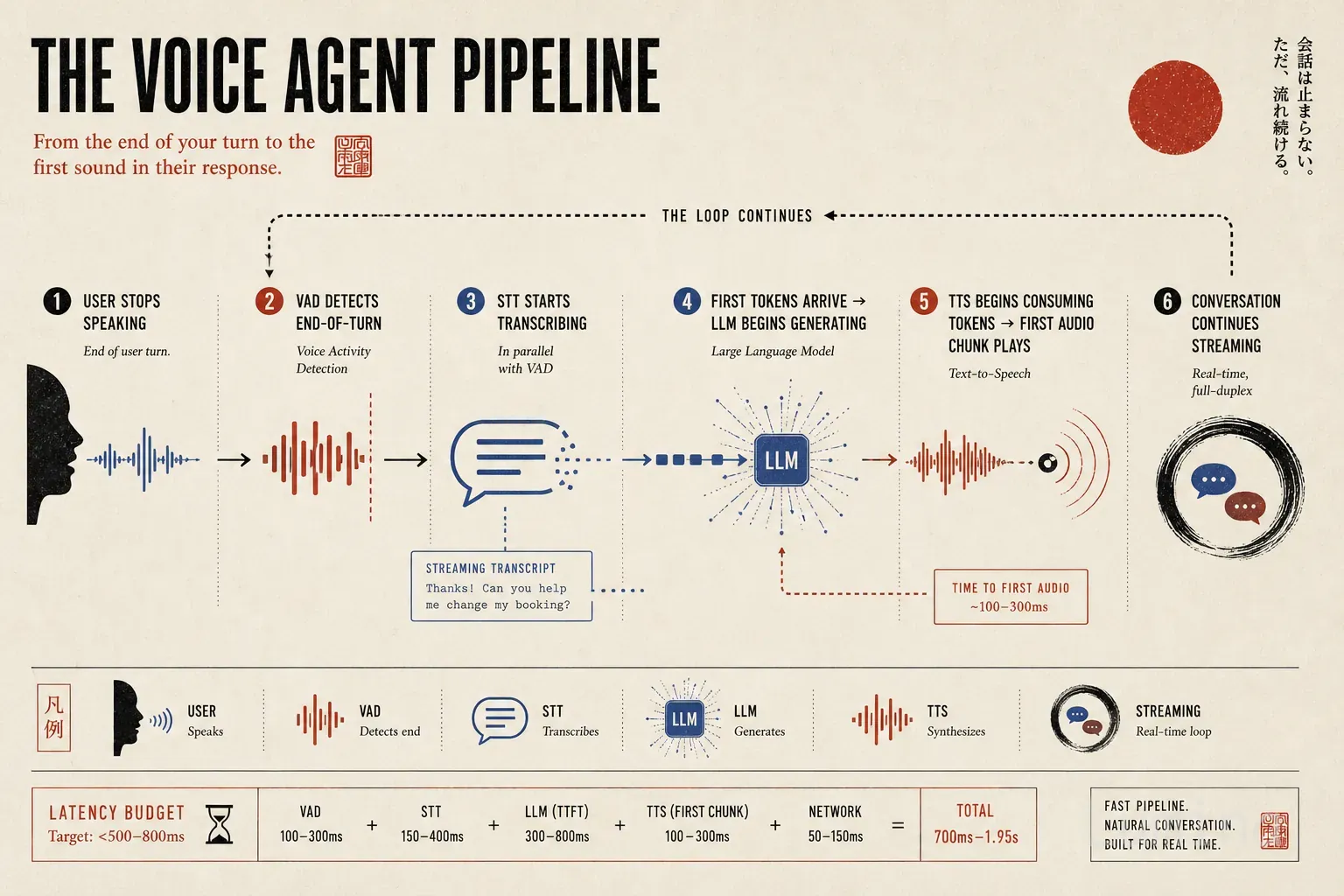
结果是:用户听到回复的第一个词时,LLM还在生成第二句话。这正是像ElevenLabs的Conversational AI、Bland.ai和Retell AI这样的公司,尽管底层使用了强大的LLM,仍能实现端到端响应延迟低于600毫秒的关键所在。
半双工 vs. 全双工
这是语音代理设计中最重要的架构决策之一,却常常被低估。
半双工(Half-duplex) 即“按键通话”模式:一方说完,另一方再说。系统在用户说话时监听,然后回复,再继续监听。实现简单,但感觉像在来回留语音邮件。对于简单的命令-响应接口(例如:“设个5分钟的定时器”),半双工尚可接受;但对于自然对话,则令人沮丧。
全双工(Full-duplex) 才是人类真实对话的方式:双方可以同时说话、互相打断、在对方说话时插话“嗯哼”,并实时反应。实现这一功能要困难得多。它要求系统同时具备监听和生成音频的能力,这就引出了“抢话(barge-in)”问题。
抢话(Barge-in) 指的是用户在代理仍在说话时开始讲话。在一个设计良好的全双工系统中,代理通过VAD检测到用户开始说话后,会立即停止自身音频输出,取消任何待处理的TTS片段,并开始处理新输入。而在设计不良的系统中,代理会继续自说自话,无视用户的打断意图,这极其令人烦躁。
抢话的技术挑战有三方面。第一,你需要一个语音活动检测(VAD)模型,能够区分用户的声音和代理通过扬声器播放的自身音频,否则代理会听到自己说话,误以为被中断。第二,你需要优雅地处理延迟:VAD触发的那一刻,必须在毫秒级内切断音频,而不是等到300毫秒后。第三,你需要决定如何处理抢话期间捕获的部分音频:它是真实输入,还是偶然噪音?
当前最先进的技术使用 Silero VAD,这是一个轻量级神经网络VAD模型,可在本地以极低延迟运行(每32毫秒音频块约10毫秒)。结合回声消除(从麦克风中滤除代理自身播放的音频),可构建一个合理的抢话检测系统。
话轮管理
人类对话并非严格交替说话和倾听。我们会使用反馈信号(如“嗯”、“对”),在对方尚未完全结束时就开始说话,并通过韵律线索(音高、节奏、尾音减弱)来示意让出话轮。当前的语音代理系统对此处理得很笨拙。
naive 的方法是基于能量的语音结束检测:等待N毫秒静音后,才判定用户已说完。问题是,500毫秒的沉默在深思熟虑的讲话中是正常的,并不代表用户已结束。等待太久会让代理显得反应迟钝;等待太短又会打断用户。
更好的方法是将静音检测与韵律分析(音高是否呈现句子结束的下降模式?)和语义分析(当前转录是否构成完整意思?)结合起来。一些系统使用一个小型快速LLM,根据当前转录预测用户的 utterance 是否可能已完成,效果出奇地好。
这是一个活跃的研究领域,LiveKit Agents 框架支持可插拔的话轮检测策略,包括基于模型的方法。
完整架构
一个生产级语音代理流水线通常如下所示:
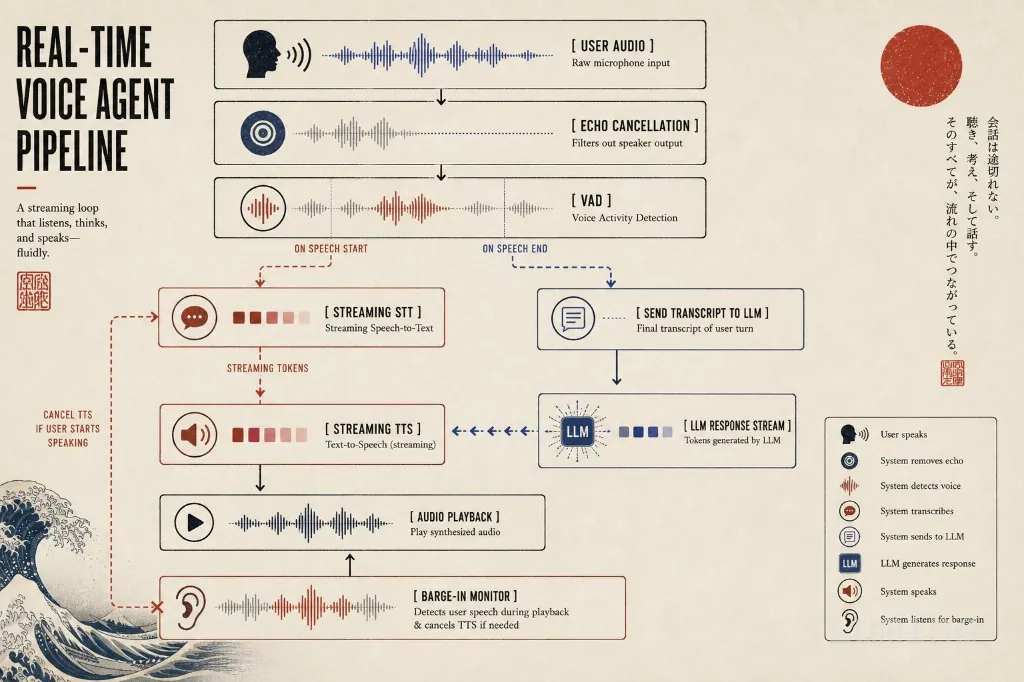
对话状态(历史、记忆、上下文)保存在LLM的提示中,每轮都会重建。音频传输层(音频字节在用户设备和服务器之间如何传输)通常由WebRTC(用于浏览器端代理)或SIP/RTP(用于电话系统)处理。
一个最小可行语音代理
为了具体说明,下面是一个实际搭建语音代理的大致连接方式。这是一个简化的 Pipecat 风格流水线,展示了各组件如何组合——生产代码会增加错误处理、可观测性和更多配置,但架构是相同的。
from pipecat.frames.frames import LLMMessagesFrame
from pipecat.pipeline.pipeline import Pipeline
from pipecat.pipeline.runner import PipelineRunner
from pipecat.pipeline.task import PipelineTask
from pipecat.services.deepgram import DeepgramSTTService
from pipecat.services.openai import OpenAILLMService
from pipecat.services.cartesia import CartesiaTTSService
from pipecat.transports.services.daily import DailyTransport
from pipecat.vad.silero import SileroVADAnalyzer
async def main():
transport = DailyTransport(
room_url, token, "Voice Bot",
DailyParams(
audio_in_enabled=True,
audio_out_enabled=True,
vad_enabled=True,
vad_analyzer=SileroVADAnalyzer(),
transcription_enabled=False,
),
)
stt = DeepgramSTTService(api_key=DEEPGRAM_KEY)
llm = OpenAILLMService(api_key=OPENAI_KEY, model="gpt-4o-mini")
tts = CartesiaTTSService(api_key=CARTESIA_KEY, voice_id=VOICE_ID)
messages = [{
"role": "system",
"content": "You are a voice assistant. Keep replies short and natural."
}]
pipeline = Pipeline([
transport.input(),
stt,
LLMMessagesFrame(messages),
llm,
tts,
transport.output(),
])
task = PipelineTask(pipeline)
await PipelineRunner().run(task)
就是这样。四十行代码,你就拥有了一个支持VAD、回声消除、抢话和全双工音频(通过WebRTC)的流式语音代理。DailyTransport、SileroVADAnalyzer 和流式服务内部隐藏的复杂性巨大,但应用层代码保持简洁。像 Pipecat 和 LiveKit Agents 这样的框架已经完成了编排调度的重活,让你可以专注于真正属于你产品独特性的部分。
选择你的组件
正确的组件选择高度依赖于你的使用场景:
追求最低延迟:Deepgram Nova-2(STT)、蒸馏后的7–8B模型(LLM)、Cartesia Sonic 或 ElevenLabs Flash(TTS)。这套组合可始终如一地实现低于500毫秒的延迟。
追求最高准确率:Whisper large-v3 或 AssemblyAI(STT)、GPT-4o 或 Claude Sonnet(LLM)、ElevenLabs Turbo(TTS)。准确率更高,但延迟通常超过800毫秒。
用于电话系统部署:Twilio 处理音频传输,Deepgram 用于STT,小型LLM,ElevenLabs 或 AWS Polly 用于TTS。PSTN(电话网络)本身会引入延迟——仅抖动缓冲通常就有150–200毫秒——因此你的目标响应时间必须将其纳入考量。
完全自托管、隐私优先:Whisper.cpp(本地STT)、通过Ollama运行的Llama-3(本地LLM)、Coqui/VITS 或 Piper(本地TTS)。非常适合私有部署;延迟取决于你的硬件。
LLM 提示长什么样
针对语音的提示工程值得一提。回复必须为“语音”设计,而非“文本”。这意味着:
- 不要使用Markdown格式、项目符号或标题。这些会原样出现在TTS中,听起来很奇怪
- 使用短句和自然语调。长而复杂的句子,包含多个从句,在口语中很难跟上
- 避免列表,改用“首先……然后……最后……”的结构
- 缩略语和 casual 语体在口语中更自然
- 当计算需要一点时间时,可适度加入填充词(如“让我为您查一下”)
SYSTEM_PROMPT = """You are a voice assistant. Your responses will be spoken aloud.
Follow these rules strictly:
- Respond in natural conversational language, as you would speak it
- Never use bullet points, numbered lists, headers, or markdown
- Keep responses concise — 2-4 sentences for most answers
- Use natural speech patterns with contractions (you are, it is, I will)
- If you need more time to think, say 'let me think about that for a moment'
"""
仍待解决的难题
我描述的基础流水线目前已被充分理解。真正的难题在于那些将平庸语音代理与优秀语音代理区分开来的细节。
嘈杂环境 是语音代理被低估的“杀手”。用户在咖啡店打电话、背景有电视噪音、或与孩子同处一室时,STT准确率会显著下降。模型仍会生成转录,但它是错的,LLM会自信地回复一个用户从未提出的问题。Krisp 和 RNNoise 等工具能显著改善稳态噪音(如空调、风扇、交通声),但非稳态噪音(其他人的声音、带人声的音乐、突然的巨响)则难得多。你可以通过特定于语音的提示,在置信度低时要求用户重复,但这只是权宜之计,而非根本解决方案。
多说话人场景 是几乎所有生产级语音代理都处理不好的情况。想象一个家庭客服电话:配偶和孩子在同一房间,偶尔插话。代理的STT会生成一个混合三人声音的“弗兰肯斯坦”式转录,LLM会回复一个根本没人提出的问题。说话人日志(说话人分档,即判断“谁说了什么”)是解决方案。Pyannote-audio 是主流的开源选项,但每轮增加200–400毫秒延迟,且对短 utterance 的准确率仍然很差。大多数团队干脆不解决这个问题。
长对话 比文本代理更快触及上下文窗口限制,因为每个言语都需要被转录、存储,并作为后续每轮的上下文重新输入。一次30分钟的支持通话,仅对话历史就很容易达到6,000–10,000 token,还不包括任何系统提示或RAG上下文。你需要一个记忆架构,能够总结旧轮次、提取持久事实,并按需重新加载相关上下文——关键在于,所有这些都必须适配进同一个500毫秒的延迟预算。这是该领域最棘手的工程问题之一。
口音和说话风格 会极大影响STT准确率。一个在美式英语基准上词错率(WER)为5%的模型,在印度英语上可能达到15%,在尼日利亚英语上20%,在口音很重的外语者身上甚至高达30%。Deepgram 和 AssemblyAI 在这方面已有显著改进,但如果你的产品面向全球,你必须针对用户实际使用的口音进行测试,而不是依赖厂商引用的基准数据。
未来之路
本入门指南涵盖了架构。有趣的工程挑战在于细节。在后续文章中,我将深入探讨:延迟堆栈以及每一毫秒究竟花在哪里、抢话问题以及生产系统如何正确实现全双工、构建能在延迟预算内存活的记忆层、评估语音代理(标准LLM评估完全无法覆盖)、电话基础设施(包括WebRTC vs. SIP以及真正重要的编解码器选择),以及现代TTS如何表达情感和韵律。
语音代理领域发展迅速,LiveKit、Daily 和 Pipecat 等框架使得基础设施的可访问性比18个月前大幅提升。架构模式正在趋同。现在的挑战在于细节:让延迟真正感觉像“在场”,让记忆真正感觉像“连续”,让话轮转换真正感觉像“对话”。
如果你正在这个领域构建任何东西,我很乐意听到你的经验。
参考文献
- Silero VAD — 轻量级神经语音活动检测
- LiveKit Agents — 开源语音代理框架
- Pipecat — 语音与多模态AI应用的开源框架
- Deepgram Nova-2 — 低延迟流式STT
- Cartesia Sonic — 超低延迟神经TTS
- 📚 Kyutai Moshi — 开源端到端语音模型,延迟低于300毫秒
- OpenAI Realtime API — 基于GPT-4o的端到端语音
- 延迟基准数据来自 ElevenLabs、Bland.ai 和 Retell.ai 的公开文档