内容
动机
上下文压缩 是一种减少代理工作内存中信息的操作。较旧的消息被摘要或压缩表示所取代,以保留任务相关的信息。此操作通常是必要的,以适应有限的上下文窗口并减少 上下文腐烂。
代理框架通常通过在固定令牌阈值时压缩来控制这一点(deepagents 使用 模型配置文件 在给定模型上下文限制的 85% 时压缩)。这种设计并不理想,因为压缩时机有好有坏:
- 在复杂的重构过程中,不宜压缩;
- 在开始新任务或认为先前上下文将失去相关性时,更适合压缩。
许多交互式编码工具都具有 /compact 命令或类似功能,允许用户在适当的时候手动触发上下文压缩步骤。我们在此基础上更进一步,在 deepagents 的最新版本中,为代理提供了一个工具,让它可以自行触发上下文压缩。这使得在不需要应用程序用户意识到有限的上下文窗口或发出特定命令的情况下,可以更灵活地进行压缩。
该工具目前在 Deep Agents CLI 中启用,并在 deepagents SDK 中可选择启用。
我们通常认为,框架应该尽可能地“放手”,并利用底层推理模型的改进。这是一个 苦涩的教训 的实例:我们可以让代理对其自身的上下文有更多的控制权,以避免手动调整框架?
何时压缩
有多种情况可能需要进行上下文压缩操作:
在任务边界清晰时:
- 用户表示他们正在进行一个新任务,先前的上下文可能不再相关
- 代理已完成交付成果,用户确认任务完成
在从大量上下文中提取结果后:
- 代理通过消耗大量上下文获得了事实、结论、摘要或其他结果,如在研究任务中
在消耗大量新上下文之前:
- 代理即将生成长篇草稿
- 代理即将读取大量新上下文
在进入复杂的多个步骤过程之前:
- 代理即将开始漫长的重构、迁移、多文件编辑或事件响应
- 代理已生成计划,即将开始执行步骤
已做出优先于先前上下文的决定:
- 出现了新的需求, 使先前的上下文失效
- 有许多旁支或死胡同,可以简化为摘要
列出所有可能的场景并不实用,但我们的观察是,人类和大型语言模型(LLM)可以识别这些场景,并在适当的时候压缩,节省后续因上下文窗口接近限制而进行的压缩步骤。您可以阅读我们在 系统提示 中为模型提供的关于此工具的指南。
该工具的参数化与现有的 Deep Agents 摘要中间件 相同:我们保留最近的消息(可用上下文的 10%)并总结之前的内容。最近的消息,包括压缩工具的调用和相关响应,被保留在最近的上下文中。
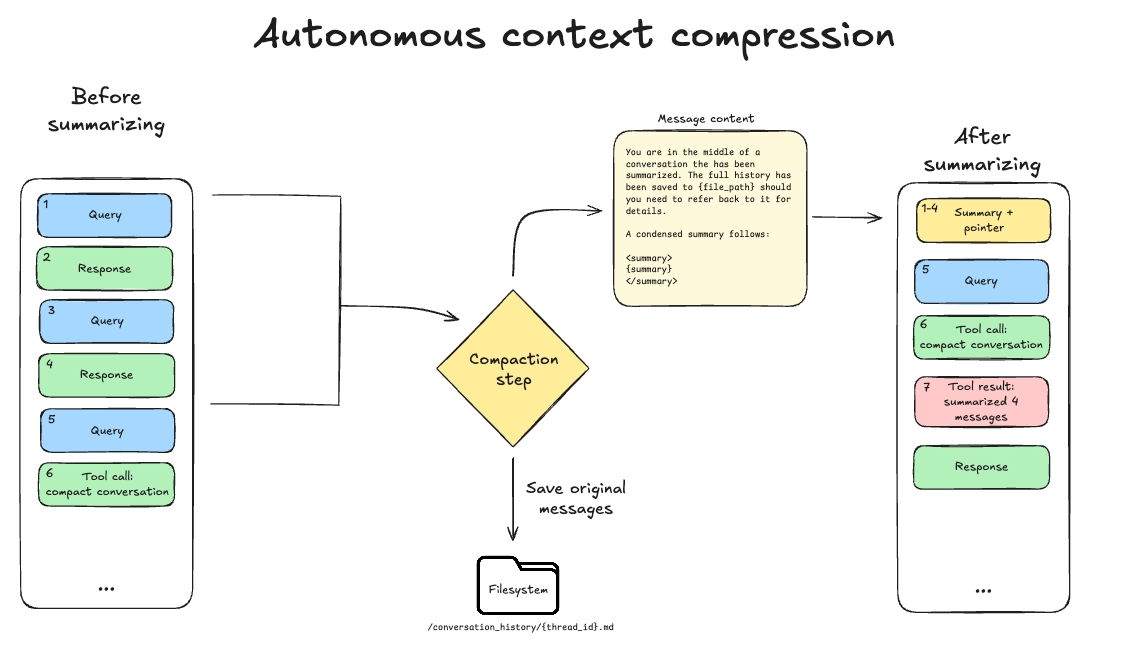 参见 示例轨迹。
参见 示例轨迹。
如何使用
该工具作为一个独立的中间件实现,因此您可以通过在 create_deep_agent 中将其添加到中间件列表中来启用它:
from deepagents import create_deep_agent
from deepagents.backends import StateBackend
from deepagents.middleware.summarization import (
create_summarization_tool_middleware,
)
backend = StateBackend # 如果使用默认后端
model = "openai:gpt-5.4"
agent = create_deep_agent(
model=model,
middleware=[
create_summarization_tool_middleware(model, backend),
],
)
更多详细信息请参见 SDK 文档。
在 CLI 中,只需在准备好修剪上下文或转到新任务时调用 /compact。
我们使用此功能的经验
我们调整此功能以变得保守。Deep Agents 在其虚拟文件系统中 保留所有对话历史记录,允许在总结后恢复上下文,但错误的上下文压缩步骤可能会造成干扰。我们测试了:
- 一个自定义评估套件,其中我们使用(自己的)LangSmith traces 向需要和不需要压缩的线程注入后续提示;
- Terminal-bench-2,其中我们没有观察到任何自主压缩实例;
- 我们在 Deep Agents CLI 中的编码任务。
实际上,代理在触发压缩时非常谨慎,但当它们这样做时,往往会选择明显改善工作流的时刻。
自主上下文压缩是一个小功能,但它指出了代理设计的更广泛方向:给予模型对其自身工作内存的更多控制权,并减少框架中的刚性、手动调整的规则。如果您正在构建长期运行或交互式代理,请在 Deep Agents SDK 或 CLI 中试用它,并让我们知道您的反馈以及您希望看到它处理的模式。