内容
最近,在 LangChain,我们一直在构建相关技能,以帮助像 Codex、Claude Code 和 Deep Agents CLI 这样的编程代理使用我们的生态系统,即 LangChain 和 LangSmith。这并非我们独有的努力 —— 大多数(如果不是全部)公司都在探索如何创建技能来赋予编程代理。构建这些技能的一个关键部分是确保它们真正能发挥作用。在这篇博客中,我们将介绍一些在创建技能时如何评估技能的经验和最佳实践。
什么是技能?
技能是经过精心策划的指令、脚本和资源,旨在提高代理人在特定领域的性能。重要的是,技能通过渐进式披露动态加载——代理人只在任务需要时才会检索技能。这有助于代理人提高其性能;历史上,给予代理人太多工具会导致其性能下降。
在实践中,技能可以被视为动态加载的提示。像任何提示一样,它们会影响代理人的行为方式。因此,技能需要进行测试,类似于您将测试您的LLM提示。哪些技能会改善编码代理人的性能?哪些内容变更会导致最大的改进?
基本评估管道
我们的基本方法是测试技能:
- 定义您希望Claude Code成功完成的任务
- 定义有助于解决任务的技能
- 运行Claude Code在任务上没有技能
- 运行Claude Code在任务上有技能
- 比较性能并迭代技能
以下,我们分享了我们经验中的一些最佳实践,以便您创建自己的评估管道。
步骤 1:设置清洁测试环境
技能通常与编码代理人,如Claude Code,或者像Deep Agents这样的集装箱一起使用。当您测试技能时,您实际上是在测试这些强大的代理人是否可以有效地使用技能信息。您正在测试代理人的性能是否会提高——因此,在实践中,您正在测试编码代理人本身。
编码代理人和集装箱有一个巨大的操作空间,可以操作。它们也对初始条件敏感:Claude Code通常会在开始工作之前探索您的目录,并且它发现的内容会影响其方法。这意味着在测试技能时,必须为代理人使用技能准备一个一致且清洁的环境,以确保最大限度地提高测试的可复现性。
在我们的测试中,我们使用了一个轻量级的Docker scaffold来运行Claude Code。其他替代方案包括Harbor或您的沙盒选择。
def run_claude_in_docker(
test_dir: Path,
prompt: str,
timeout: int = 300,
model: str = None
) -> subprocess.CompletedProcess:
"""Run Claude CLI in Docker. Returns CompletedProcess."""
if not check_docker_available():
raise RuntimeError("Docker not available")
cmd = ["run-claude", str(test_dir), prompt, "--timeout", str(timeout)]
if model:
cmd.extend(["--model", model])
try:
return run_shell("docker.sh", *cmd, timeout=timeout + 30, check=False)
except subprocess.TimeoutExpired:
return subprocess.CompletedProcess(cmd, 124, "", f"Timeout after {timeout}s")
步骤 2:定义任务
虽然有时会倾向于依靠直觉来感觉您的编码代理人是否会因为技能而改善,但性能会因不同任务而异。明确定义的任务提供了一个系统的基准来捕捉回归。我们从构建任务中学习了以下几点:
创建约束任务
- 开放式输出难以评估,尤其是在编码代理人中。如果我们要求Claude Code创建一个LangChain代理来进行研究,它可能会采用各种方法。评估Claude Code生成的代理质量很难,而且过于具体地限制代理设计会惩罚产生有效研究的工作解决方案。
- 我们发现的一个有帮助的策略是要求Claude Code修复错误的代码。这约束了其设计空间,使其更容易验证正确性:如果生成的代理仍然在预定义测试中产生错误行为,我们可以安全地失败Claude的解决方案。此外,设计检查更不容易破裂,因为Claude被设计成使用我们的现有方法。
与清晰的指标配对
-
清晰的指标至关重要,以量化您的技能是否改善了编码代理人。我们跟踪的指标包括:技能是否被调用?与此相反,技能是否在不相关时未被调用?
-
代理是否完成任务?一个任务可能涉及多个步骤,跟踪完成的步骤数有助于区分“完全失败”和“几乎成功”。
-
Claude Code完成任务所需的轮数。即使Claude Code可以在没有技能的情况下完成任务,包括技能可能会提高效率。
-
Claude Code在实际时间内完成任务所需的时间。并非每个轮次都相等,当它来到测量效率时。
-
我们跟踪了这些指标,以及它们在每次运行中如何变化,使用LangSmith评估。这给我们提供了一个单一的视图来了解实验结果。
不要过度关注难度
- 当您评估技能时,您正在通过编码代理人或集装箱来做这件事。编码代理人已经非常擅长解决问题。如果您使您的任务过于复杂或混乱,您有风险测试编码代理人的问题解决能力,而不是您的技能。
- 有用的做法是基于您在编码代理人中观察到的真实故障来创建任务。作为一个启发式,您应该尝试创建最简单的测试案例来导致故障。例如,我们注意到Claude Code难以有效地上传评估器到LangSmith。我们的测试案例要求Claude,“给定此数据集,请创建一个轨迹评估器并将其上传到LangSmith”。
示例任务
在我们的内部测试中,我们评估了Claude Code在基本LangChain和LangSmith任务上。以下是示例任务的样子:
// TASK
创建一个轨迹数据集,包含5个示例,从LangSmith项目中最近的5个跟踪中获取,plus一个评估器,测量工具调用匹配百分比。
输出:trajectory_dataset.json和trajectory_evaluator.py
(上传两个作为“bench-{run_id}”到LangSmith)
直接运行任何代码。
作为此过程的一部分,我们期望它会创建一个trajectory_dataset.json。我们可以使用以下指标评估输出:
# 样本指标,检查Claude生成的数据集
def check_accuracy(runner: TestRunner):
"""Trajectories match ground truth.""" # Did Claude的输出匹配真实值
dataset_file = runner.artifacts[0] # Claude的输出:trajectory_dataset.json
test_dir = Path(".")
p, f = check_trajectory_accuracy(
test_dir=test_dir,
outputs=runner.context,
filename=dataset_file,
expected_filename="expected_dataset.json", # 真实值,expected_dataset.json
data_dir=test_dir / "data", # 任务中存储真实值的文件夹
)
for msg in p:
runner.passed(msg)
for msg in f:
runner.failed(msg)
要查看我们最终编写的所有测试,请参见我们的基准测试存储库。
Step 4: 运行和比较性能
为了测试我们的技能,我们在任务上运行 Claude Code,使用不同的技能组合。一些测试案例包括:
- 控制案例,我们在任务上运行 Claude Code 没有任何技能
- 在任务上运行 Claude Code,使用所有技能
- 在任务上运行 Claude Code,技能合并为几个大技能
- 在任务上运行 Claude Code,技能分散在多个小技能中
我们使用 LangSmith 的 pytest 集成 比较任务完成率。包括技能几乎总是有益的,内容的不同分割在不同任务上表现更好。总体而言,Claude Code 使用技能完成任务的比例为 82%,但没有技能时性能下降到 9%。然而,我们需要了解 为什么 Claude Code 失败,以便可以迭代技能。
了解 Claude Code 在 Docker 中的行为及其原因并非易事,我们需要对 Claude Code 的轨迹进行可观察性。在我们的测试中,我们与 LangSmith 集成 捕获 Claude Code 所有动作。我们可以了解它读取的文件、创建的脚本以及它调用的技能(或未调用的技能)。
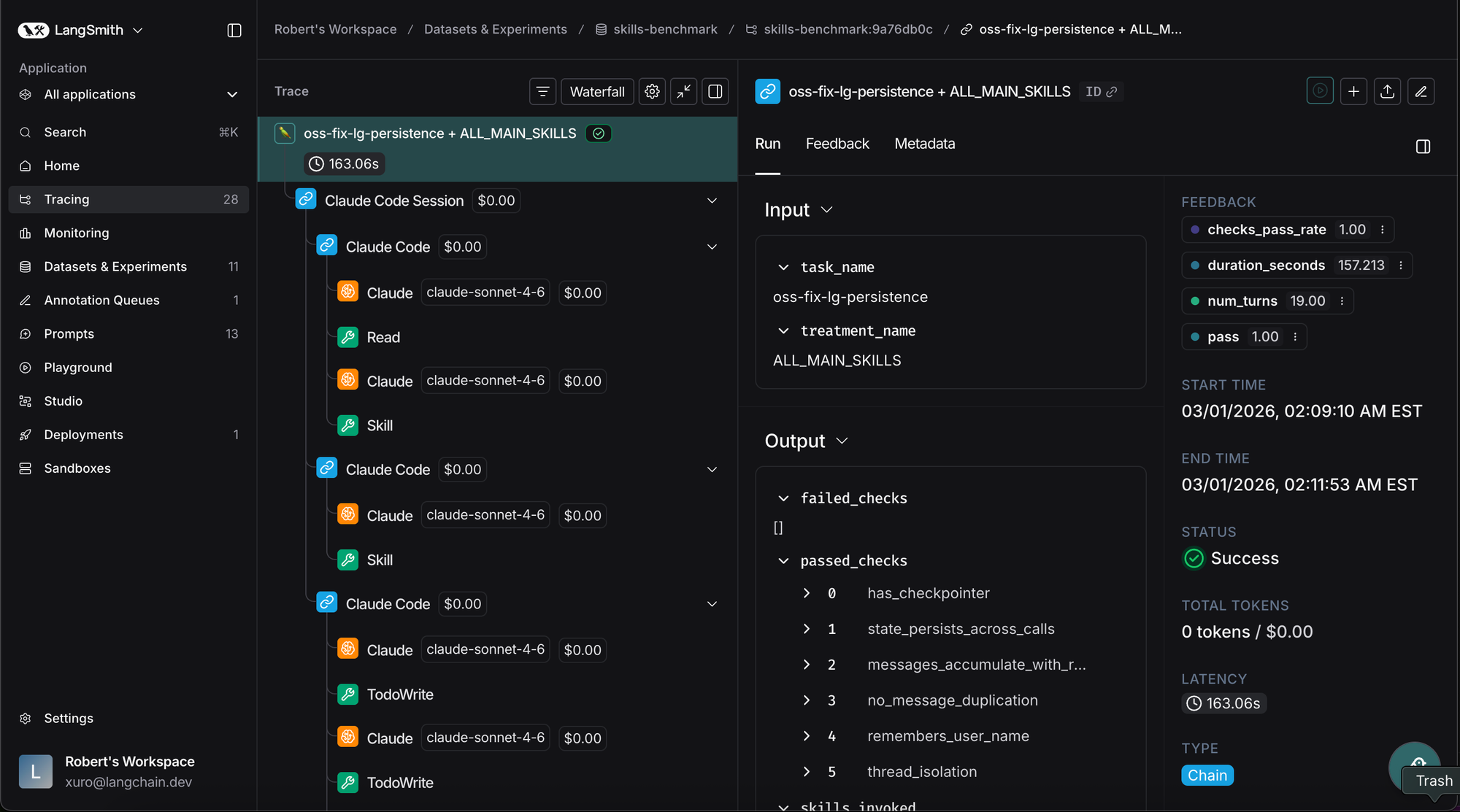 关键的是,我们让 Claude Code 使用自己的跟踪技能来检查跟踪并总结发生的事情。这使得迭代技能内容速度更快。Claude Code 将跟踪发送到 LangSmith,下载这些跟踪,并为人类总结问题。人类可以然后提出修复方案,重新运行测试,并在 LangSmith 的实验门户 中查看性能变化。
关键的是,我们让 Claude Code 使用自己的跟踪技能来检查跟踪并总结发生的事情。这使得迭代技能内容速度更快。Claude Code 将跟踪发送到 LangSmith,下载这些跟踪,并为人类总结问题。人类可以然后提出修复方案,重新运行测试,并在 LangSmith 的实验门户 中查看性能变化。
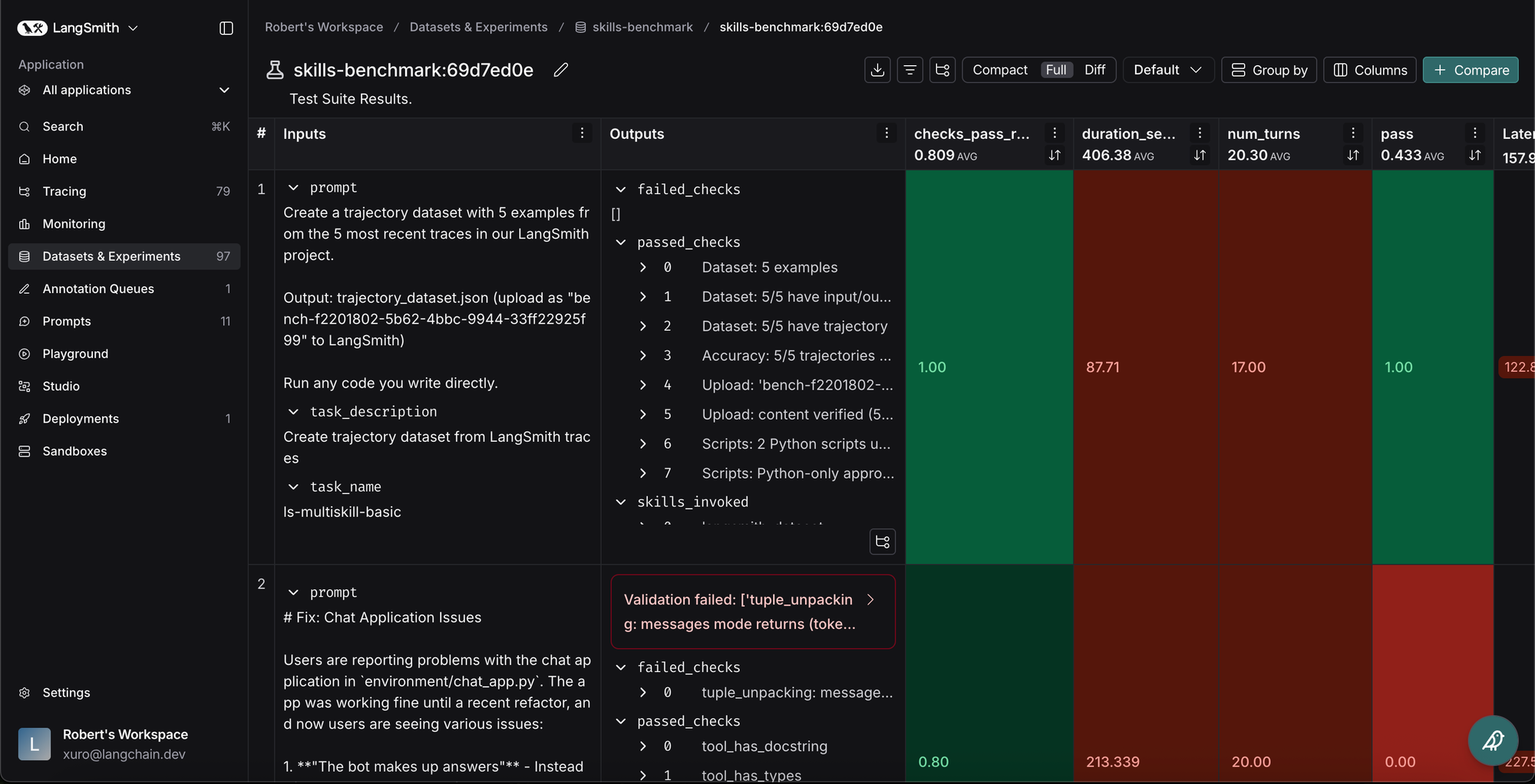 在设置自己的技能评估管道时,拥有良好的可观察性和良好的评估至关重要,尤其是因为像 Claude Code 这样的强大代理。
在设置自己的技能评估管道时,拥有良好的可观察性和良好的评估至关重要,尤其是因为像 Claude Code 这样的强大代理。
结论
技能是增强编码代理能力(包括 Claude Code、Codex 或 Deep Agents CLI)的有用方法。与其他涉及 LLM 和代理的组件一样,技能需要评估才能有用。
要查看所有这些在行动 - 请参见我们的 基准测试仓库。
我们希望这些学习提供好的评估规范,当您构建自己的技能时。对于那些刚开始评估技能的人,请参见 LangSmith 的评估平台!