从被动应对到主动出击:借助大语言模型弥合钓鱼攻击防御缺口
内容
电子邮件安全一直被定义为不稳定的状态。它是一场无止境的防御和攻击的对抗赛,防御的强度仅仅取决于最后一次绕过的漏洞,而攻击者则不断努力以微小的优势迭代。我们部署的每个控制措施最终都会成为昨天的解决方案。
这个挑战尤其困难的是,我们最大的弱点是不可见的。
这个问题最好的例子来自第二次世界大战。数学家 阿布拉罕·瓦尔德 被要求帮助盟军工程师决定如何加强轰炸机。工程师最初专注于返回任务的飞机上的弹孔。瓦尔德指出,错误在于他们正在加强那些已经能承受损伤而仍然能生存的飞机的区域。真正的弱点是那些从未返回的飞机。
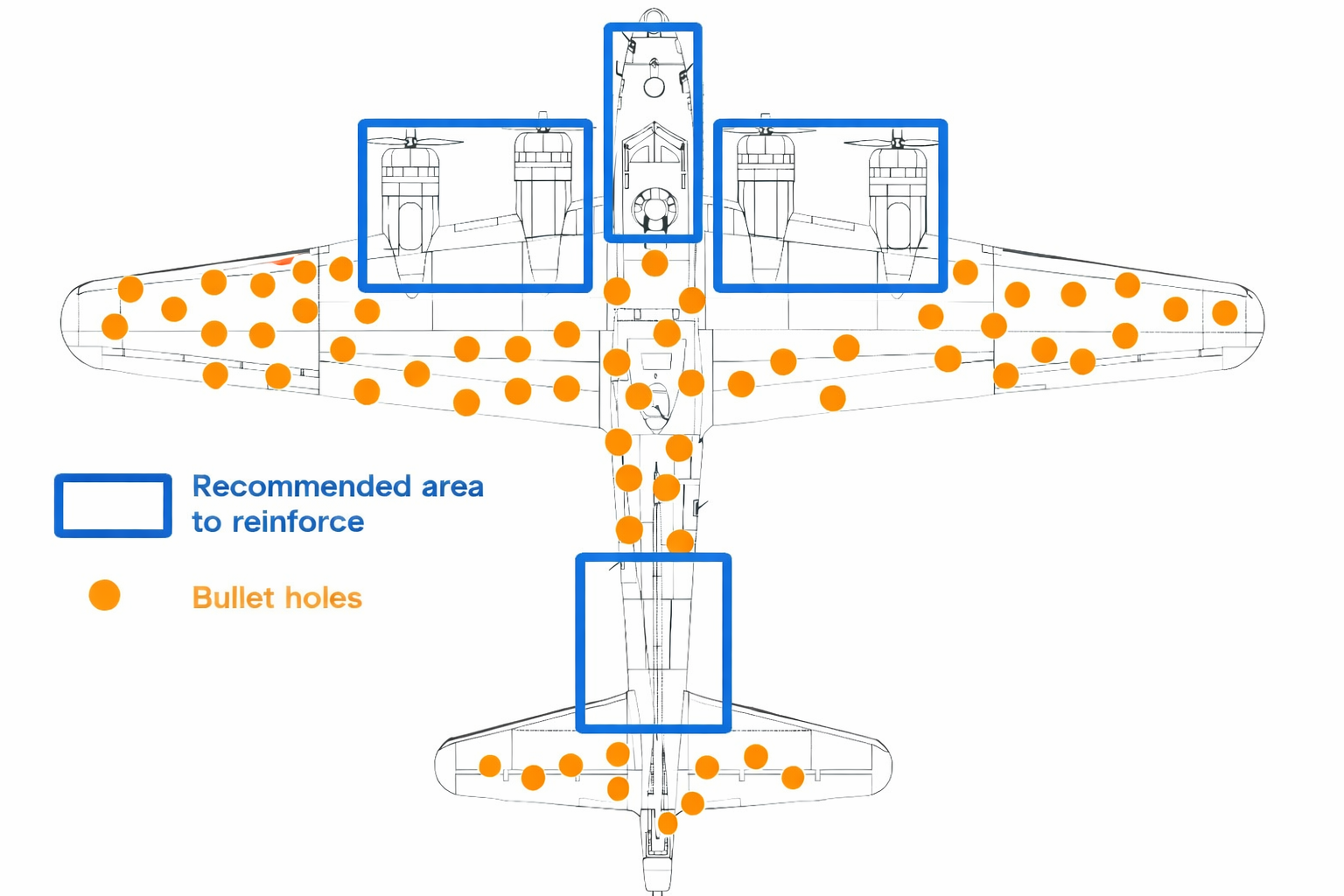
电子邮件安全面临着相同的障碍:我们的检测漏洞是不可见的。通过整合LLM,我们推进了电子邮件钓鱼保护,并从反应性到主动性检测改进。
反应性防御的局限性
传统的电子邮件安全系统主要通过用户报告的漏洞来改进。例如,如果我们标记了一条垃圾邮件为干净,客户可以将原始EML发送到我们的管道,让我们的分析师分析并更新我们的模型。这条反馈链是必要的和有价值的,但它是反应性的。它依赖于有人在事后发现失败并花时间报告它。
这意味着检测改进通常是由攻击者已经成功的东西驱动,而不是他们即将利用的东西。
为了关闭这个漏洞,我们需要一种系统地观察“没有回来的飞机”的方法。
使用LLM绘制威胁地图
大型语言模型(LLM) 在2022年和2023年末进入了主流市场,根本改变了我们处理未结构化数据的方式。它们的核心是使用深度学习和巨大的数据集来预测序列中的下一个令牌,从而能够理解上下文和细微差别。它们特别适合电子邮件安全,因为它们可以阅读自然语言并 characterization 复杂概念(如意图、紧迫性和欺骗)跨数百万条消息。
每天,Cloudflare处理数百万条不想要的电子邮件。以往,这是不可能深入 characterization 每条消息的除粗糙分类之外的任何内容。手动将电子邮件映射到细致的威胁向量根本不适用。
现在,Cloudflare已经将LLM整合到电子邮件安全工具中,以便在攻击者发动之前识别威胁。通过使用LLM的力量,如下所述,我们可以最终看到威胁地图的清晰和全面图景。
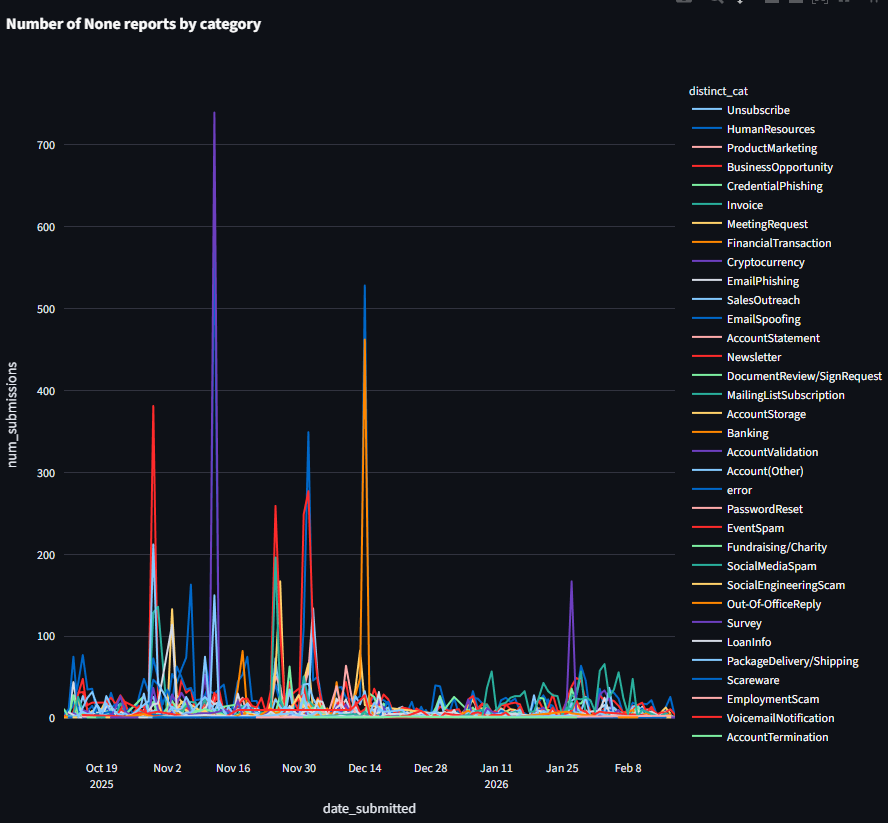
我们的LLM驱动分类显示了几个明显的峰值和持续趋势,包括“奖金通知”和“销售 outreach”。
这些LLM生成的标签为Cloudflare分析师提供了高保真度的信号,几乎实时。以前需要花费数小时的调查和复杂查询才能完成的任务现在可以自动完成,附带相关的上下文。这直接增加了我们能够构建新的目标机器学习模型或重新训练现有模型以应对新行为的速度。
由于Cloudflare在全球互联网上运营,我们可以收集这些见解比以往任何时候都更早,通常在客户报告的漏洞之前。
销售 Outreach 威胁
我们使用这个新知识识别出的最清晰的模式是恶意邮件结构化以看起来像销售 Outreach 风格的钓鱼邮件的持续存在。这些电子邮件设计来模仿合法的B2B通信,通常呈现购买或收到“特别交易”的机会来诱骗目标点击恶意链接或提供凭据。
一旦LLM分类表明销售 Outreach 是一个主要向量,我们就从广泛可见性转向了目标数据收集。
使用LLM生成的标签,我们开始系统地隔离那些表现出销售 Outreach 特征的电子邮件,包括我们的全球数据集。这产生了一个不断增长的、高精度的实例库,包括确认的恶意邮件以及传统系统难以分类的边缘案例。从这个库中,我们建立了一个专门的训练管道。
首先,我们通过将消息分组,根据LLMs识别出的共享语言和结构特征来筛选训练数据。这些特征包括说服性框架、制造紧迫性、交易性语言和微妙的社会证明。
接下来,我们专注于提取情绪和意图而不是静态指标。模型学习如何请求的方式、如何建立信任和如何在正常的商业对话中嵌入呼吁行动。
最后,我们训练了一个专门针对销售 Outreach 行为的目的构建的情绪分析模型。这样可以避免过载一个通用钓鱼分类器,并允许我们调整精确度和召回率。
将语言转化为执法
这个模型的输出是反映电子邮件与已知销售 Outreach 攻击模式的匹配程度的风险评分。这个评分与现有的信号,如发送者声誉、链接行为和历史背景一起评估,以确定电子邮件是否应该被阻止、隔离或允许。
这个过程是持续的。攻击者随着他们的语言的适应,新观察到的电子邮件会被反馈到管道中,并用于细化模型,而不需要等待大量用户报告的漏洞。LLMs作为发现层面,表面新的语言变体,而专门的模型进行快速和可伸缩的执法。
这是在实践中展现的全面进攻。它是一条反馈链,其中大规模语言理解驱动了专注、高精度的检测。结果是对一个依赖于细微差别的威胁类别的更早干预,以及更少的恶意销售电子邮件到达收件箱。
行动的结果
LLM驱动的映射使我们能够改进检测的可见性。我们不再等待攻击者成功并依赖于下游用户报告,而是能够识别系统性漏洞并在源头上解决它们。这一从反应性修复到主动性强化的转变直接转化为可量化的客户影响。
最直接的成功信号是客户摩擦的显著降低。销售 Outreach 相关的钓鱼邮件历史上产生了大量用户报告的漏洞,主要是因为这些邮件非常类似于合法的商业通信,并且通常会绕过传统的基于规则或声誉的系统。我们的专门模型上线并不断细化使用LLM提供的见解后, fewer 这些邮件首先就到达了收件箱。
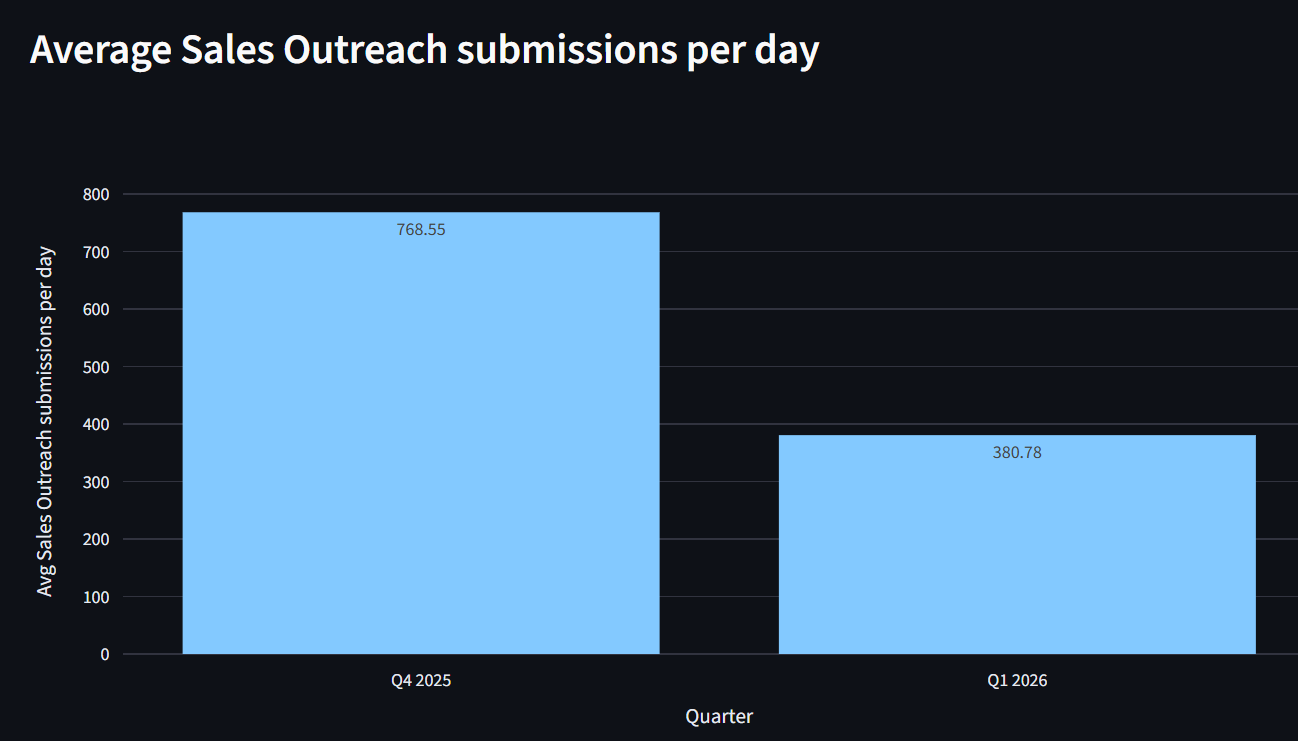
数据反映了这一变化。平均每日销售 Outreach 提交 ——标记为干净但实际上是销售 Outreach 钓鱼邮件的电子邮件 ——从2025年第三季度的965条减少到2025年第四季度的769条,代表了 20.4% 的报告漏洞减少 在一个季度内。
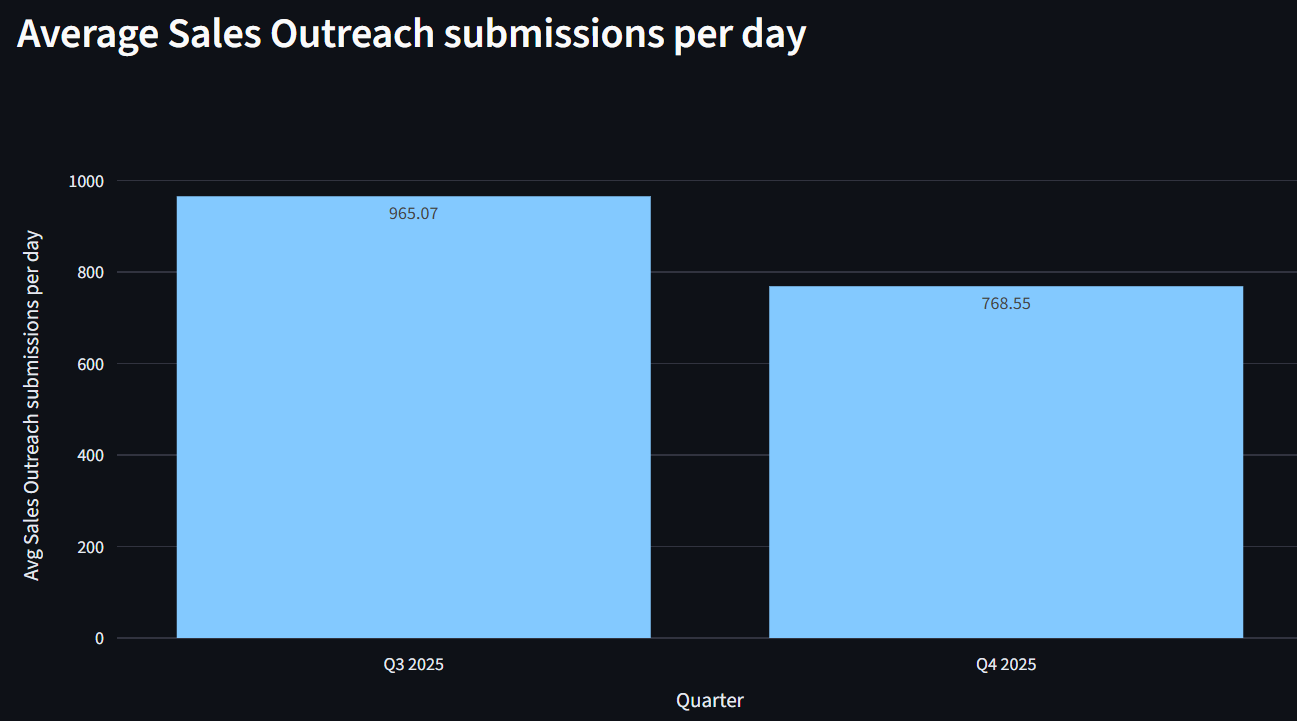
这个减少不仅仅是一个指标改进;它代表了每天几千次的中断减少。每次避免的提交都是一个在发动之前被阻止的钓鱼尝试,这意味着信任不会被侵蚀,分析师的时间不会被浪费,用户也不会被迫在工作流中做出安全判断。我们已经在2026年第一季度看到这种趋势继续,平均每日提交减少了三分之二。
实际上,LLMs使我们能够“看到”那些从未返回的飞机。通过照亮之前不可见的失败模式,我们能够加强防御,精确地在攻击者集中攻击的位置。结果是系统不仅改进了检测率,还改善了人们依赖它的日常体验。
未来战役的下一个前沿
我们与LLMs的工作才刚刚开始。
为了在攻击的下一个演变中保持领先,我们正在向环境意识的全面模型迈进,通过精细化LLM以从每个交互中提取法医级细节来提取。这种精细的映射使我们能够识别特定的战术签名,而不是依赖广泛的标签。
同时,我们正在部署专门针对高混淆度向量的机器学习模型,专门针对传统防御漏洞的“边缘”。通过利用LLM数据作为战略指南,我们可以将人类专长从已知噪音转向下一个攻击的关键漏洞。
通过照亮“没有回来的飞机”,我们正在做的不仅仅是反应于漏洞的电子邮件;我们正在系统性地缩小战场。在电子邮件战役中,优势属于能够先看到不可见的那一方。
准备增强您的电子邮件安全?
我们为所有组织(无论是Cloudflare客户还是不是)提供免费访问我们的 Retro Scan 工具,使他们能够使用我们的预测AI模型扫描Microsoft 365中的现有收件箱电子邮件。
准备提升你的电子邮件安全性?
我们为所有组织(无论是 Cloudflare 的客户还是非客户)提供免费访问我们的 Retro Scan 工具,允许他们使用我们的预测 AI 模型扫描 Microsoft 365 中的现有收件箱邮件。
Retro Scan 将检测并突出显示发现的任何威胁,允许组织在电子邮件账户中直接修复它们。通过这些见解,组织可以实施进一步的控制,使用 Cloudflare Email Security 或他们偏好的解决方案,防止类似威胁在将来到达他们的收件箱。
如果你感兴趣了解 Cloudflare 如何帮助保护你的收件箱,请在这里注册一次钓鱼风险评估 here.