内容
今天,我们正式发布 Gemma 4——这是我们目前最智能的开源模型。该模型专为高级推理和智能体(agentic)工作流而设计,在单位参数量所体现的智能水平上实现了前所未有的突破。这一成果建立在令人振奋的社区发展势头之上:自第一代模型发布以来,开发者已累计下载 Gemma 超过 4 亿次,构建了拥有逾 10 万种变体的活跃Gemmaverse生态。我们认真倾听创新者对下一代 AI 技术的期待,Gemma 4 正是我们的回应:在 Apache 2.0 许可证下,以广泛可及的方式提供突破性能力。
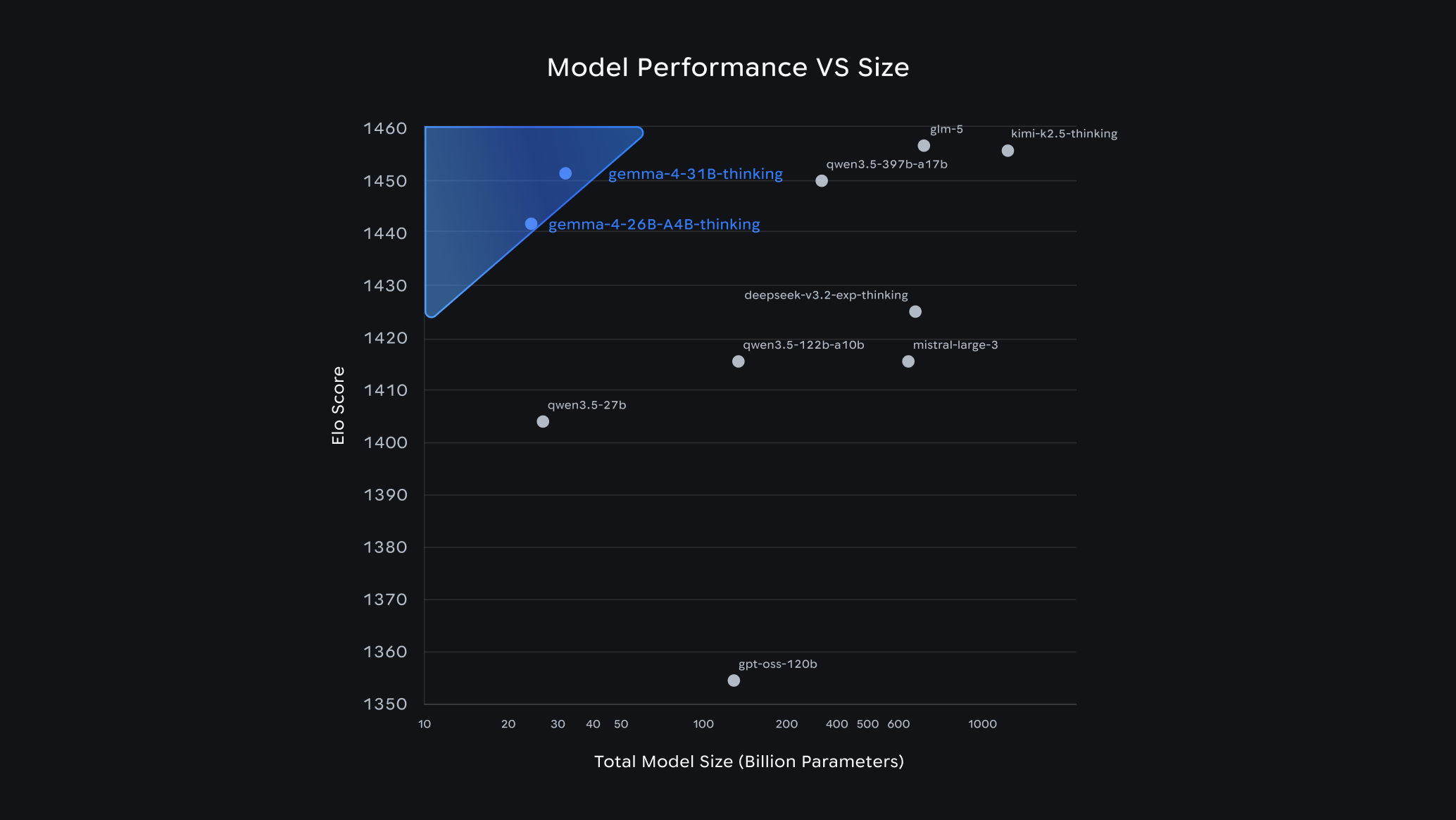
根据 Arena.ai 聊天竞技场数据(截至 4月1日),开源模型在不同规模下的性能表现对比。
Gemma 4 基于与 Gemini 3 相同的世界级研究和技术构建,是可在您硬件上运行的最强大模型系列。它与我们现有的 Gemini 模型形成互补,为开发者提供了业界最强大的开源与专有工具组合。
行业领先的能力,面向移动端的 AI 优先设计
我们推出四种灵活尺寸的 Gemma 4 模型:有效 2B(E2B)、有效 4B(E4B)、26B 专家混合模型(MoE) 和 31B 稠密模型(Dense)。整个模型家族已超越简单的对话交互,能够处理复杂的逻辑推理和智能体工作流。其中较大规模的模型在其尺寸类别中均达到顶尖性能水平:31B 模型目前在行业标准Arena AI 文本排行榜上位列全球第三大开源模型,26B 模型则位居第六名。更值得注意的是,Gemma 4 能以远小于自身 20 倍的参数量击败更大规模的竞品模型。对于开发者而言,这种“单位参数智能”的新高度意味着只需显著更低的硬件开销即可实现前沿级别的能力。
在边缘端,我们的 E2B 和 E4B 模型重新定义了设备本地的实用价值,优先考虑多模态处理能力、低延迟处理和无缝生态系统集成,而非单纯追求参数量。
强大、易用且完全开源
为了推动下一代开创性研究与应用的发展,我们特别针对各类硬件优化了 Gemma 4 模型的运行与微调效率——从全球数十亿台 Android 设备,到笔记本电脑 GPU,直至开发者工作站和加速计算平台。
通过使用这些高度优化的模型,您可以对 Gemma 4 进行微调,从而在特定任务上实现顶尖性能。我们已经看到这一方法取得了惊人成果:例如 INSAIT 团队创建了首个保加利亚语优先的语言模型(BgGPT),我们还与耶鲁大学合作开发了Cell2Sentence-Scale,用于发现癌症治疗的新路径,此类成功案例不胜枚举。
以下是 Gemma 4 成为我们迄今最强大开源模型家族的关键特性:
- 先进推理能力:具备多步骤规划与深度逻辑分析能力,在需要复杂推理的数学问题和指令遵循基准测试中表现显著提升。
- 智能体工作流支持:原生支持函数调用、结构化 JSON 输出以及系统级指令,使您能构建可可靠地与各类工具和 API 交互并执行自动化流程的自主智能体。
- 代码生成:支持高质量的离线编程,将您的开发工作站转变为本地优先的 AI 编程助手。
- 视觉与音频处理:所有模型均原生支持视频与图像处理,可适应可变分辨率输入,并在 OCR(光学字符识别)和图表理解等视觉任务中表现优异;此外,E2B 和 E4B 型号还具备原生语音输入功能,可用于语音识别与自然语言理解。
- 超长上下文窗口:可无缝处理长篇内容。边缘端模型配备 128K 上下文窗口,大型模型则提供高达 256K 的窗口长度,允许您将整个代码仓库或长文档一次性输入提示词中。
- 140+ 种语言支持:基于超过 140 种语言原生训练而成,Gemma 4 助力开发者为全球受众构建包容性强、高性能的应用程序。
多样化模型适配不同硬件环境
我们针对不同硬件平台和使用场景发布了多款 Gemma 4 模型权重版本,确保无论何时何地都能获得前沿级别的推理能力:
26B 与 31B 模型:个人电脑上的前沿智能,离线运行
针对研究人员和开发者的可访问性硬件进行了优化,我们的非量化 bfloat16 权重可高效部署于单张 80GB NVIDIA H100 GPU 上。对于本地部署环境,量化版本可直接在消费级 GPU 上原生运行,为您的 IDE、编程助手及智能体工作流提供支持。我们的 26B 专家混合模型(MoE)专注于降低延迟,在推理过程中仅激活其总参数量的 38 亿个,从而实现极高的每秒 token 生成速度;而 31B 稠密模型则致力于最大化原始质量,并为后续微调提供强大基础。
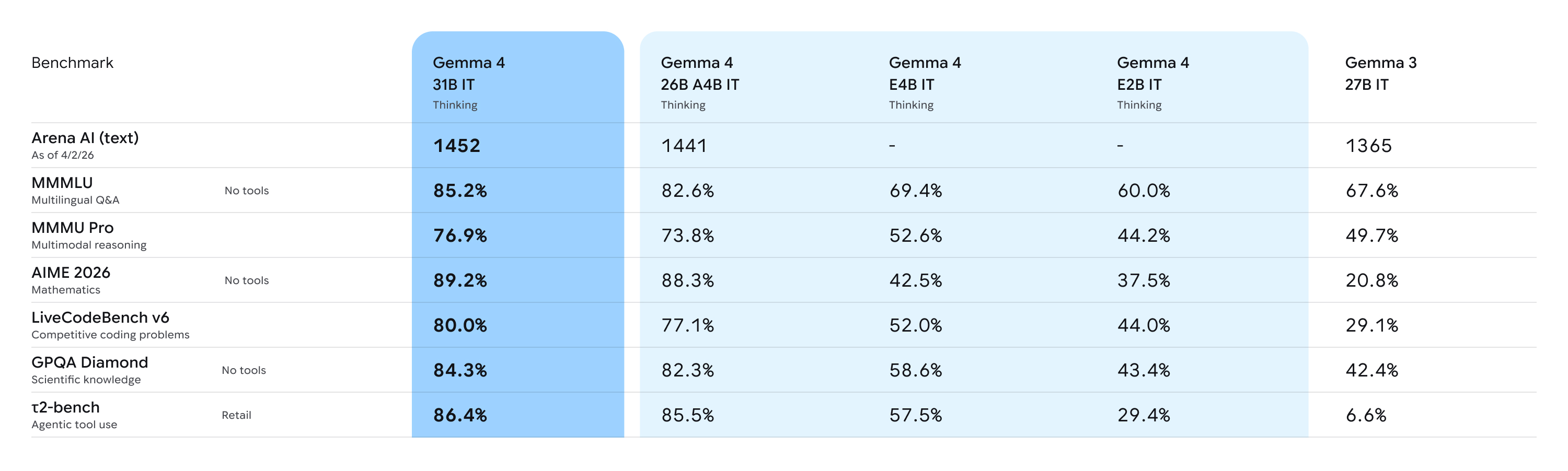
这些模型经过大量数据集与评估指标的综合测试,全面覆盖文本生成的各个方面。更多基准测试结果请参见我们的模型卡片。
E2B 与 E4B 模型:移动设备与物联网设备的新智能层级
从底层架构开始就针对最大化的计算与内存效率进行设计,这些模型在推理时分别激活相当于 20 亿与 40 亿参数的效果,从而有效节省 RAM 与电池消耗。通过与 Google Pixel 团队及高通技术公司、联发科等移动硬件领导厂商紧密协作,这些多模态模型可在手机、树莓派、NVIDIA Jetson Orin Nano 等边缘设备上实现近乎零延迟的完全离线运行。Android 开发者现已可通过AICore 开发者预览版直接原型化智能体流程,并与即将发布的 Gemini Nano 4 保持向前兼容。
开源许可协议
您提出了宝贵意见,我们认真采纳。构建 AI 的未来需要协作精神,我们相信应通过开放赋能开发者生态,消除限制性障碍。正因如此,Gemma 4 采用商业友好的 Apache 2.0 许可证发布。
这一开源许可为基础提供了完整的开发者灵活性保障与数字主权支持,赋予您对数据、基础设施和模型的全权控制。它使您能够在任何环境中自由构建并安全部署,无论是在本地数据中心还是云端。
在 Hugging Face 首日即上线 Gemma 4 系列,这标志着一个重大里程碑。我们对此深感兴奋。” —— 克莱芒・德朗格,Hugging Face 联合创始人兼首席执行官
建立在信任与安全的基础之上
这些模型均接受与我们专有模型相同的严格基础设施安全协议审查。选择 Gemma 4,企业和主权机构将获得值得信赖、透明可靠的基石,既能享受顶尖技术水平,又能满足最高标准的安全性与可靠性要求。
丰富的生态系统选择
- 秒级启动实验:立即体验 Gemma 4 并开始构建应用。可在 Google AI Studio(31B 与 26B MoE)或 Google AI Edge Gallery(E4B 与 E2B)中探索 Gemma 4。对于Android 开发,可使用其在Android Studio中驱动 Agent Mode,并通过ML Kit GenAI Prompt API开始在 Android 生产环境中构建应用程序。
- 使用您喜爱的工具:首日即支持 Hugging Face(Transformers、TRL、Transformers.js、Candle)、LiteRT-LM、vLLM、llama.cpp、MLX、Ollama、NVIDIA NIM 和 NeMo、LM Studio、Unsloth、SGLang、Cactus、Baseten、Docker、MaxText、Tunix、Keras 等多种流行框架与库,让您自由选择最适合项目的工具组合。
- 下载模型权重:可从Hugging Face、Kaggle 或 Ollama 获取模型权重文件。
- 按需定制 Gemma 4:使用您偏好的平台(如 Google Colab、Vertex AI 甚至游戏级 GPU)对模型进行训练与适配。
- 在 Google Cloud 上扩展至生产环境:虽然本地设备端推理适合离线使用,但 Google Cloud 彻底解除算力限制。您可通过 Vertex AI、Cloud Run、GKE、主权云、TPU 加速服务以及针对监管合规工作负载的最高等级认证保障,以任意方式部署您的应用。了解更多关于 Google Cloud 起步指南请点击此处。
- 跨多硬件平台加速 AI 开发:Gemma 4 开箱即用即针对业界领先硬件进行了优化。无论是从 NVIDIA Jetson Orin Nano 到 Blackwell GPU 的 NVIDIA AI 基础设施,还是通过开源 ROCm™ 栈集成 AMD GPU,亦或是在 Trillium 与 Ironwood TPU 上实现大规模高效部署,均可体验极致性能表现。
- 参与影响世界的挑战:加入 Kaggle 上的Gemma 4 Good 挑战赛,共同打造能为世界带来积极变革的产品。