内容
过去几个月里,我一直在攻克两个相互关联的难题:让 Claude 生成高质量的前端设计,以及让它无需人工干预即可构建完整的应用程序。这项工作的灵感源自我们此前在前端设计技能和长期运行的编码智能体框架方面的探索。当时,我和我的同事们通过提示词工程与框架设计显著提升了 Claude 的表现——远超基线水平。但两者最终都遇到了瓶颈。
为了突破限制,我尝试借鉴跨领域的新型 AI 工程方法。这些领域差异显著:一个关乎主观审美,另一个则依赖可验证的正确性与可用性。受生成对抗网络(GAN)启发,我设计了一个包含生成器与评估器的多智能体结构。要构建一个既能可靠打分、又具审美判断力的评估器,首先需要将“这个设计好不好?”这类主观问题转化为具体、可量化的标准。
随后,我将这些技术应用于长期自主编程任务中,延续了此前框架工作中的两条经验:将构建过程拆解为可管理的模块,并通过结构化工件在不同会话间传递上下文信息。最终成果是一个由规划器、生成器、评估器构成的三智能体架构,能够在数小时的完全自主编码过程中产出功能丰富的全栈应用。
为何简单的实现方案难以奏效
我们此前已证明,框架设计对长期运行智能体编程的效果有显著影响。在一项早期实验中,我们使用初始化智能体将产品需求分解为任务清单,再由编码智能体逐个特性地实现,并通过工件交接来维持跨会话的上下文连贯性。整个开发者社区也已达成类似共识,例如“Ralph Wiggum”方法就采用钩子或脚本机制,使智能体持续迭代。
然而,一些问题依然顽固存在。对于更复杂的任务,智能体仍会随时间推移逐渐偏离正轨。在分析这一现象时,我们发现智能体执行此类任务时存在两种常见失败模式。
其一是模型在处理长任务时会因上下文窗口填满而丧失连贯性(参见我们关于上下文工程的文章)。部分模型还会表现出“上下文焦虑”——即当接近其认为的上下文极限时,提前草率收尾工作。通过重置上下文窗口并重新开始新智能体,同时结合结构化交接机制传递前序状态与下一步计划,可同时解决这两个问题。
这与压缩(compaction)不同:压缩是在不中断当前智能体的情况下,将历史对话摘要嵌入原有上下文中继续推进。虽然压缩保持了连续性,但未给智能体提供“干净 slate”,因此上下文焦虑仍可能持续存在。而重置虽以牺牲交接工件的状态完整性为代价,却能确保下一阶段智能体能基于清晰上下文无缝承接工作。我们在测试中发现,Claude Sonnet 4.5 的上下文焦虑表现尤为明显,仅靠压缩无法满足长任务的高性能需求,因此上下文重置成为该框架设计的关键。这解决了核心问题,但也带来了编排复杂度、token 开销与延迟增加等代价。
第二个此前未解决的问题是自我评估。当被要求评价自身产出时,智能体往往自信地称赞作品——即便对人类观察者而言质量显然平庸。这一问题在设计类主观任务中尤为突出,因其缺乏类似软件测试的二元校验标准。“这个布局是否精致”属于主观判断,而智能体在自评时普遍偏向积极。
不过,即使在结果可验证的任务上,智能体有时也会做出错误判断,阻碍任务完成。将执行工作的智能体与评判它的智能体分离,被证明是解决此问题的有效手段。这种分离本身并不能立即消除偏袒倾向——因为评估器仍是倾向于宽容对待 LLM 生成内容的 LLM。但调优一个独立的怀疑型评估器,远比让生成器批判自己的作品更易操作;一旦获得外部反馈,生成器就有了具体的迭代依据。
前端设计:让主观质量变得可量化
我首先从前端设计入手,因为这里的自我评估问题最为直观。若无干预,Claude 通常倾向于安全但乏味的布局,技术上可用却缺乏视觉吸引力。
我构建前端设计框架时有两个关键洞察:其一,尽管美学无法完全量化(个人品味始终存在差异),但可通过编码设计原则与偏好的评分标准来提升;“这个设计美吗?”难以一致回答,但“它是否符合我们的优秀设计准则?”则为 Claude 提供了明确的评估基准。其二,将前端生成与前端评估分离,可建立驱动生成器产出更强结果的反馈循环。
基于此,我为生成器与评估器分别设定了四条评分标准:
- 设计质量:该设计是否呈现整体协调感而非零散拼凑?优秀表现为色彩、字体、布局、图像等元素协同营造出独特氛围与品牌识别度。
- 原创性:是否存在定制决策痕迹,还是模板化布局、库默认设置与 AI 生成模式的堆砌?人类设计师应能辨识出明确的创意选择。未经修改的库存组件,或 AI 生成特征(如白色卡片上的紫色渐变)均不符合要求。
- 工艺:技术执行:字体层级、间距一致性、色彩和谐度、对比度比例。此为能力检验而非创造力检验。多数合理实现默认达标,失败意味着基础原理错误。
- 功能性:独立于美学的可用性。用户能否理解界面功能、找到主要操作并完成目标而不需猜测?
我更强调设计质量与原创性,而非工艺与功能性。Claude 在工艺与功能性上默认表现良好,因其所需的技术能力天然适配模型特性。但在设计与原创性方面,Claude 常输出平淡无奇的结果。标准明确惩罚高度通用的“AI 垃圾”模式,并通过加重设计权重,推动模型敢于尝试更具美感的方案。
我通过少量示例校准评估器,提供详细得分 breakdown,确保其判断与我偏好一致,减少迭代过程中的分数漂移。
我基于 Claude Agent SDK 构建了整个循环流程,使编排保持简洁。首先生成器根据用户提示创建 HTML/CSS/JS 前端页面。接着,我赋予评估器 Playwright MCP,使其能直接与实时页面交互,逐项评分并撰写详细批评。实践中,评估器会自主浏览页面,截屏并仔细研究实现细节后给出评估。反馈随即回流至生成器,作为下一轮迭代的输入。每次生成我运行 5 到 15 轮迭代,每轮通常推动生成器朝更具特色的方向演进,回应评估器的批评。由于评估器需实际操控页面而非静态截图,每轮耗时真实时钟时间。完整运行最长可达四小时。我还指示生成器在每轮评估后做出策略决策:若分数趋势良好则优化当前方向,否则彻底转向全新风格。
多轮运行中,评估器的判断逐步改善并最终趋于稳定,仍有提升空间。部分生成渐进式优化,另一些则在迭代间发生鲜明的美学转向。
标准的措辞甚至引导生成器走向我未曾预料的路径。例如“最佳设计如同博物馆藏品”这类表述,促使设计向特定视觉风格收敛,表明标准提示词本身直接塑造了输出特征。
尽管分数总体呈上升趋势,但并非总是线性增长。后期实现整体更优,但我仍常发现中间某轮优于最后一轮。随着轮次推进,实现复杂度也递增,生成器为响应评估器反馈而追求更宏大的解决方案。即便首轮输出,也已明显优于无任何提示的基线,说明标准及其语言本身在评估器反馈前,便已将模型从通用默认值中引导出来。
一个典型案例是,我要求模型为荷兰艺术博物馆创建网站。第九轮时,它已生成一个简洁的深色主题着陆页,视觉效果 polished 但仍在预期范围内。第十轮却彻底推翻重来,将网站重新构想为空间体验:一个用 CSS 透视渲染的棋盘地板房间,艺术品随意悬挂墙面,通过门洞导航切换展厅,而非滚动或点击。这是我此前从未在单次生成中见过的创造性飞跃。
扩展至全栈开发
掌握这些发现后,我将此 GAN 启发的模式应用于全栈开发。生成器-评估器循环自然映射到软件开发生命周期中,代码审查与 QA 在此结构与设计评估器扮演相同角色。
架构设计
在我们早期的长期运行框架中,我们通过初始化智能体、逐个特性实现的编码智能体,以及会话间的上下文重置,解决了多会话连贯编码问题。其中上下文重置是关键突破:该框架使用 Sonnet 4.5,其具备前述“上下文焦虑”倾向。构建一个能在重置后仍稳定工作的框架,是确保模型专注任务的核心。Opus 4.5 已基本消除此行为,因此我得以完全移除该框架中的上下文重置。所有智能体在一个连续会话中运行,全程构建过程由 Claude Agent SDK 自动处理上下文增长。
本次工作中,我在原始框架基础上构建了一个三智能体系统,每个智能体针对我此前运行中观察到的特定 gap 进行优化。系统包含以下智能体角色:
规划器:我们之前的长期运行框架要求用户预先提供详细规格说明。我希望自动化这一步骤,于是创建了规划器智能体,它能将简短的 1-4 句提示扩展为完整的产品规格。我要求它大胆设定范围,并聚焦于产品背景与高阶技术设计,而非过早陷入细粒度技术实现。这是为了避免规划器在规格中指定错误的技术细节,导致错误 cascading 到下游实现。更聪明的做法是约束智能体需交付的成果,让他们在工作过程中自行探索路径。我还要求规划器在产品规格中寻找融入 AI 特性的机会。(附录中有示例。)
生成器:早期框架采用的“逐个特性实现”方式在范围管理上效果良好。此处我沿用类似模型,指示生成器以冲刺(sprint)为单位工作,每次从规格中领取一个特性。每个冲刺使用 React、Vite、FastAPI 与 SQLite(后续转为 PostgreSQL)栈实现应用,并要求生成器在每个冲刺结束时自我评估工作,再交由 QA 验收。生成器还使用 git 进行版本控制。
评估器:早期框架的应用常外观 impressive,但实际使用时却存在真实 bug。为捕捉这些问题,评估器使用 Playwright MCP 像普通用户一样点击运行中的应用,测试 UI 功能、API 端点与数据库状态。然后它根据前端实验建模的标准集,对每个冲刺进行评估,涵盖产品深度、功能性、视觉设计与代码质量。每个标准设有硬性阈值,任一标准低于阈值即判定冲刺失败,生成器将获得关于出错细节的详细反馈。
每个冲刺前,生成器与评估器协商冲刺合同:在编写任何代码前,就如何定义“完成”达成一致。这步存在是因为产品规格有意保持高层级,而我需要一个步骤弥合用户故事与可测试实现之间的 gap。生成器提出其将构建的内容及成功验证方式,评估器审核提案以确保生成器正在构建正确的东西。双方迭代直至达成共识。
通信通过文件处理:一个智能体写入文件,另一智能体读取后在该文件或新文件中回应,前一智能体再读取后者内容。生成器据此构建符合合同的工作,再移交 QA 验收。这确保了工作忠实于规格,同时避免过早过度指定实现细节。
运行框架
首个版本的框架我使用 Claude Opus 4.5,将用户提示同时提交给完整框架与单智能体系统进行对比。我选用 Opus 4.5,因为这是我开始实验时的最佳编码模型。
我写下如下提示生成复古视频游戏制作工具:
创建一个包含关卡编辑器、精灵编辑器、实体行为与可玩测试模式的 2D 复古游戏制作器。
下表显示框架类型、运行时间与总成本。
| 框架 | 时长 | 成本 |
|---|---|---|
| 单智能体 | 20 分钟 | $9 |
| 完整框架 | 6 小时 | $200 |
框架成本高出 20 倍以上,但输出质量的差异立竿见影。
我原本期望看到一个界面,允许我构建关卡及其组件(精灵、实体、瓦片布局),然后点击播放真正游玩关卡。我先打开单智能体运行的输出,初始应用似乎符合这些预期。
但随着点击深入,问题逐渐浮现。布局浪费空间,固定高度的面板使大部分视口空置。工作流程 rigid。尝试填充关卡时,我必须先创建精灵与实体,但 UI 未提供任何引导序列。更重要的是,实际游戏 broken。我的实体出现在屏幕上,但对输入毫无响应。深入代码后发现,实体定义与游戏运行时之间的连接断裂,且无任何表面迹象表明问题所在。
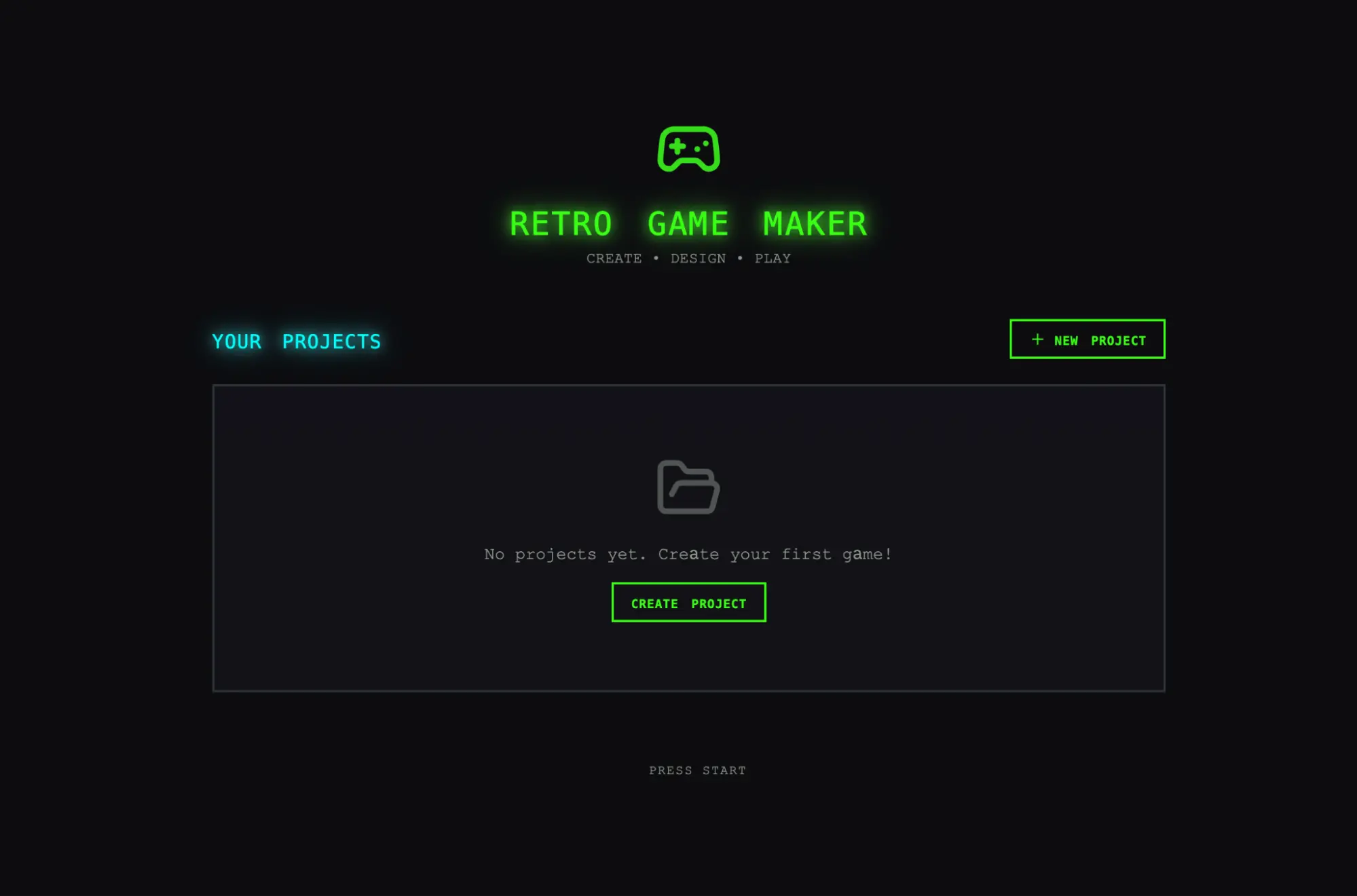 单智能体框架创建的 app 初始屏幕。
单智能体框架创建的 app 初始屏幕。
 单智能体框架创建的精灵编辑器。
单智能体框架创建的精灵编辑器。
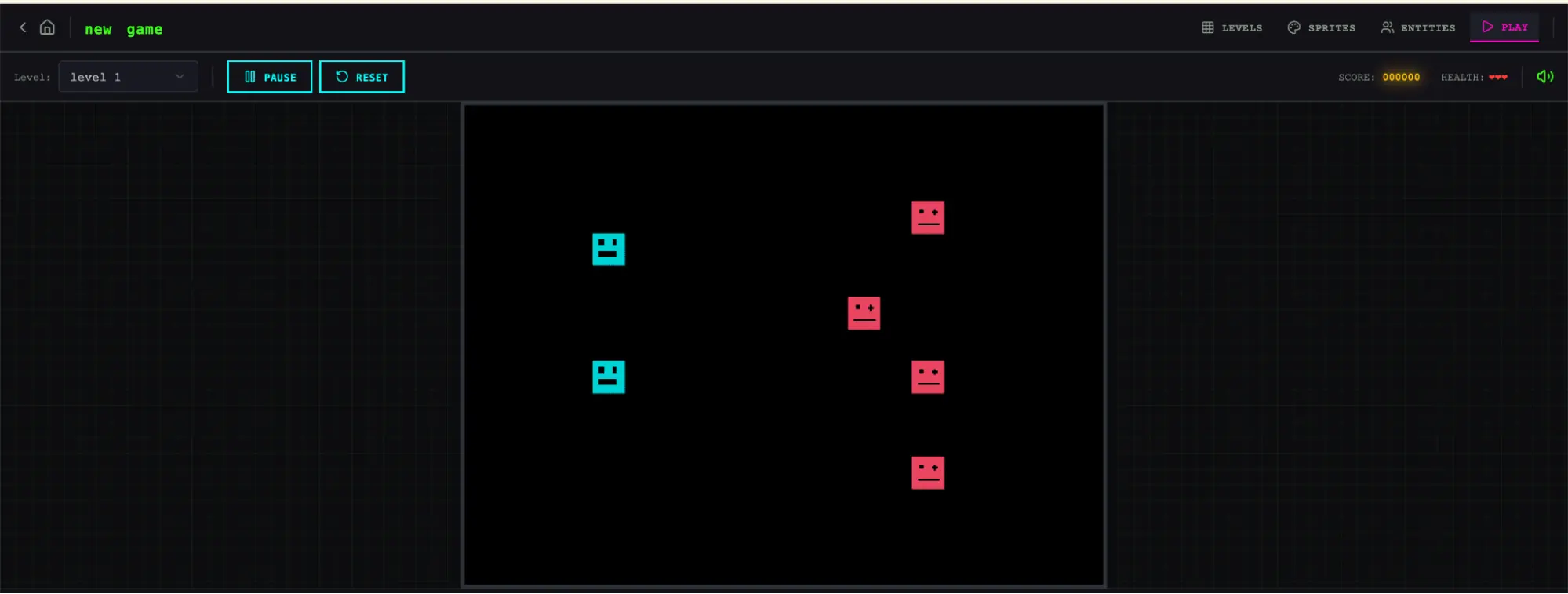 尝试游玩我创建的关卡未果。
尝试游玩我创建的关卡未果。
评估完单智能体运行后,我转向框架运行。该运行从相同的单句提示开始,但规划器步骤将其扩展为一个包含 16 个特性、横跨十个冲刺的完整规格。它远超前单智能体尝试的范围。除核心编辑器与播放模式外,规格还包括精灵动画系统、行为模板、音效与音乐、AI 辅助精灵生成器与关卡设计师,以及带分享链接的游戏导出功能。我给予规划器访问我们前端设计技能的权限,它读取并用于为 app 创建视觉设计语言,作为规格的一部分。每个冲刺中,生成器与评估器协商定义冲刺的具体实现细节与可测试行为。
应用立即展现出比单智能体运行更 polished 与流畅的体验。画布充分利用视口,面板尺寸合理,界面具有一致视觉身份,与规格中的设计方向相符。单智能体运行中的笨重感部分残留——工作流程仍未明确提示应在尝试填充关卡前先构建精灵与实体,我只能通过摸索发现这一点。这反映出基础模型的产品直觉 gap,而非框架设计意图解决的问题,但也表明框架内部针对性迭代可进一步提升输出质量。
在使用编辑器过程中,新运行相对于单智能体的优势愈发明显。精灵编辑器更丰富、功能更全,调色板 cleaner,颜色选择器更好用,缩放控件更易用。
由于我要求规划器在规格中融入 AI 特性,应用还内置了 Claude 集成,允许我通过提示生成游戏的不同部分。这显著加速了工作流程。
 初始屏幕:使用完整框架构建的新游戏创建界面。
初始屏幕:使用完整框架构建的新游戏创建界面。
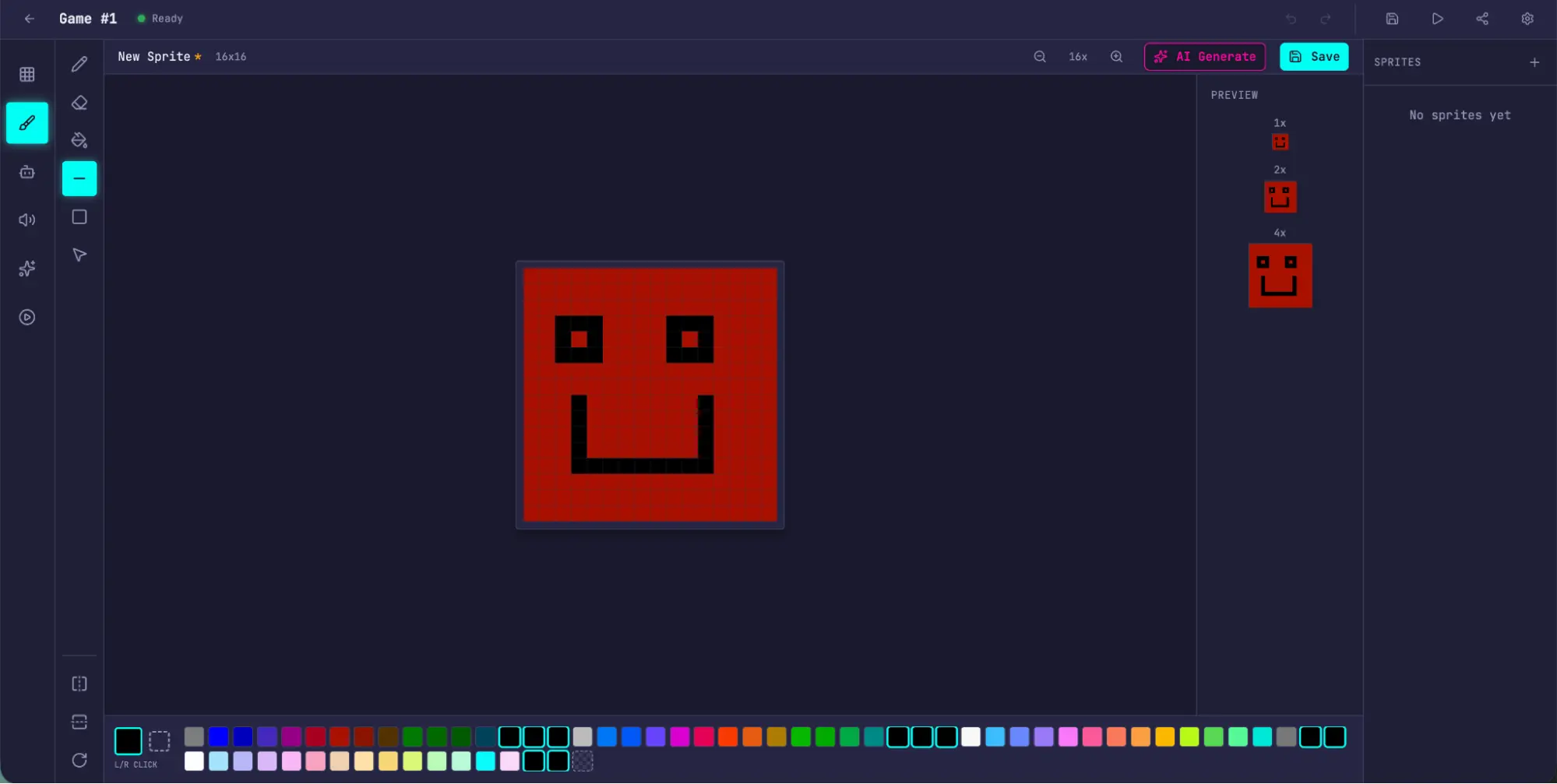 精灵编辑器感觉更 clean 易用。
精灵编辑器感觉更 clean 易用。
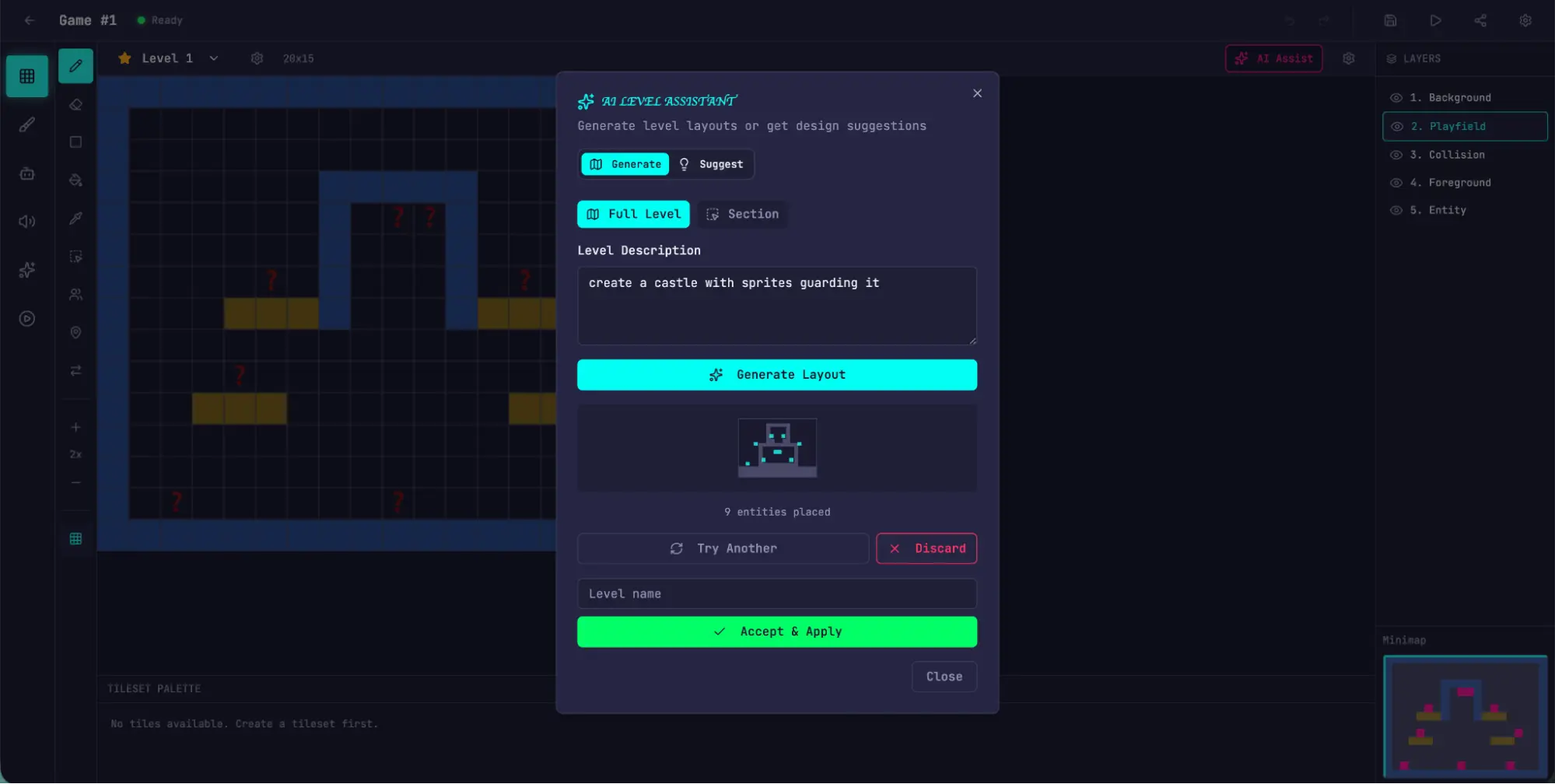 使用内置 AI 功能生成关卡。
使用内置 AI 功能生成关卡。
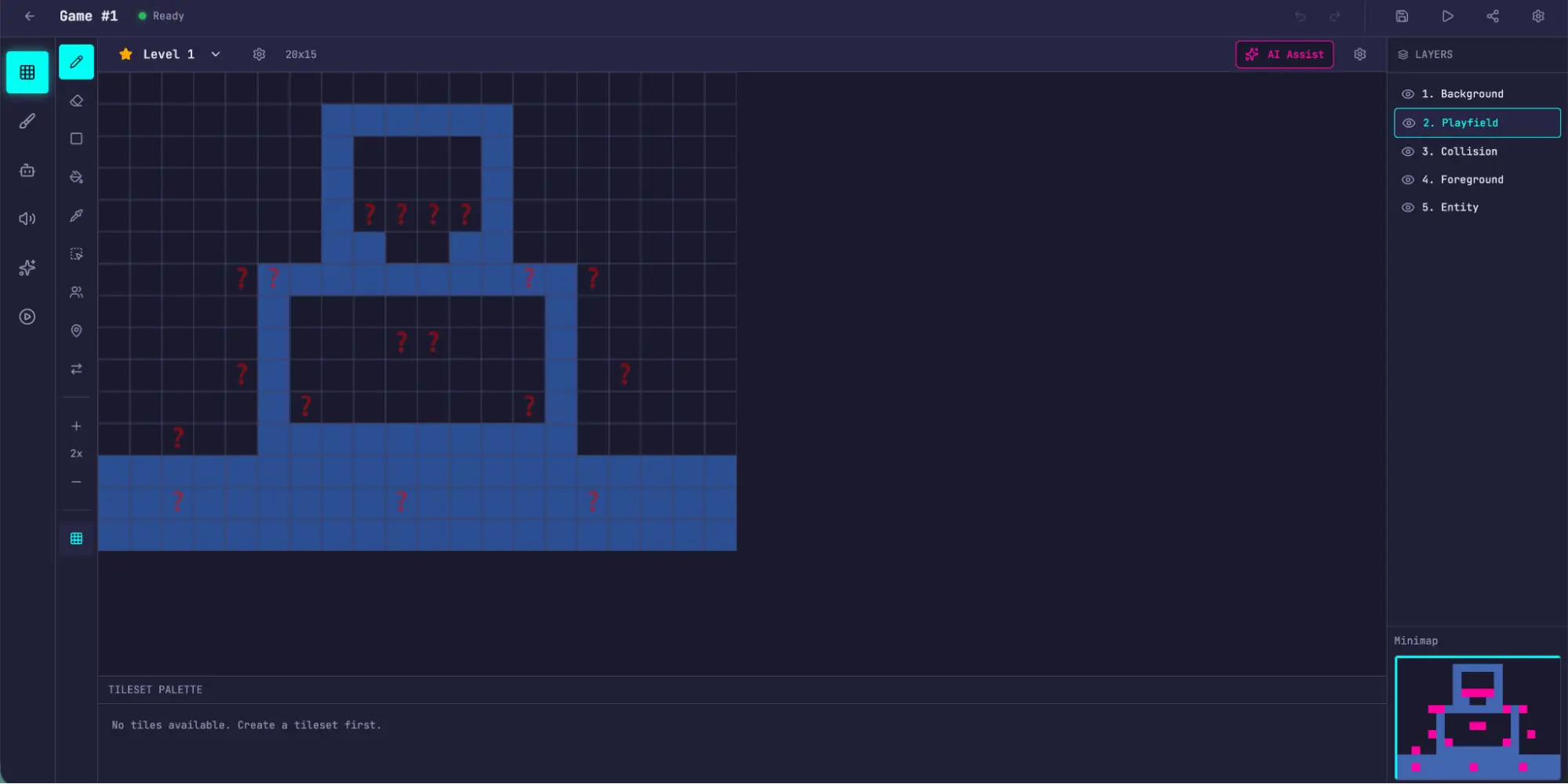 使用内置 AI 功能生成关卡。
使用内置 AI 功能生成关卡。
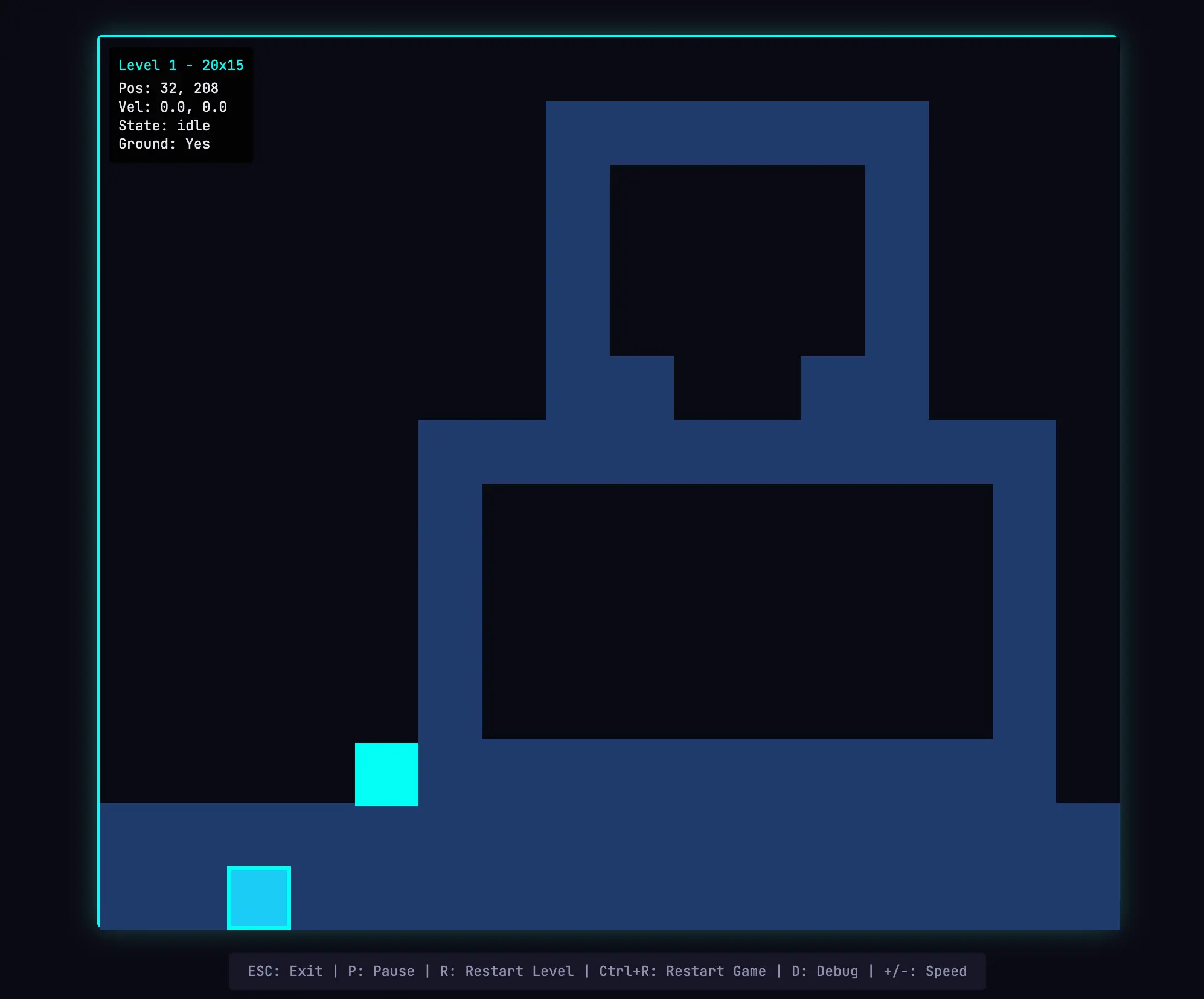 游玩我生成的游戏。
游玩我生成的游戏。
最大差异体现在播放模式。我居然可以移动实体并真正游玩游戏。物理引擎有些粗糙——我的角色跳到平台上却与之重叠,直觉上感觉不对——但核心功能 work,而单智能体运行未能做到这点。稍作移动后,我发现 AI 的游戏关卡构建存在局限。有一堵高墙我无法跳过,于是 stuck。这表明框架可通过处理常识改进与边缘情况,进一步优化应用。
阅读日志可知,评估器始终将实现与规格对齐。每个冲刺,它遍历冲刺合同的测试标准,通过 Playwright 操作运行中的应用,对任何偏离预期行为的內容记录 bug。合同非常 granular——仅第 3 冲刺就有 27 条覆盖关卡编辑器的标准——评估器的发现足够具体,无需额外调查即可采取行动。下表展示评估器识别的几个问题示例:
| 合同标准 | 评估器发现 |
|---|---|
| 矩形填充工具允许点击拖拽以用选定瓦片填充矩形区域 | FAIL — 工具仅在拖拽起点/终点放置瓦片,而非填充区域。fillRectangle 函数存在但未在 mouseUp 时正确触发。 |
| 用户可选择并删除已放置的实体生成点 | FAIL — LevelEditor.tsx:892 的 Delete 键处理器要求 selection 与 selectedEntityId 同时设置,但点击实体仅设置 selectedEntityId。条件应为 selection |
| 用户可通过 API 重新排序动画帧 | FAIL — PUT /frames/reorder 路由定义在 /{frame_id} 路由之后。FastAPI 将 'r eorder' 匹配为 frame_id 整数并返回 422:“无法解析字符串为整数。” |
要让评估器达到此水平需要大量工作。开箱即用的 Claude 是个糟糕的 QA 智能体。早期运行中,我看到它识别出真实问题,然后自我说服认为问题不大并批准工作。它还倾向于 superficial 测试,而非深入边缘情况,因此许多 subtle bug 漏网之鱼。调优循环是阅读评估器日志,找到其判断与我分歧的例子,并更新 QA 提示以解决这些问题。经过几轮此开发循环,评估器才以我认为合理的方