内容
深度代理(deep agents)的一个关键特性是它们可以访问一组文件系统工具。深度代理可以使用这些工具来读取、写入、编辑、列出和搜索其文件系统中的文件。
在这篇文章中,我们将探讨为什么我们认为文件系统对于代理来说很重要。为了理解文件系统如何有助于代理,我们应该首先思考代理可能在哪里失败。它们可能由于以下两个原因失败:(a)模型不够好,或者(b)它们没有访问正确的上下文。上下文工程是“填充上下文窗口以便为下一步提供恰好合适的信息的微妙艺术和科学”(“delicate art and science of filling the context window with just the right information for the next step”)。了解上下文工程及其可能的失败方式对于构建可靠的代理至关重要。
上下文工程的视角
一种观察现代代理工程师工作的方式是通过上下文工程(context engineering)的视角。代理通常可以访问大量的上下文(所有支持文档、所有代码文件等)。为了回答一个传入的问题,代理需要一些重要的上下文(其中包含回答问题所需的上下文)。在尝试回答该问题时,代理检索一些上下文(以将其拉入其上下文窗口)。
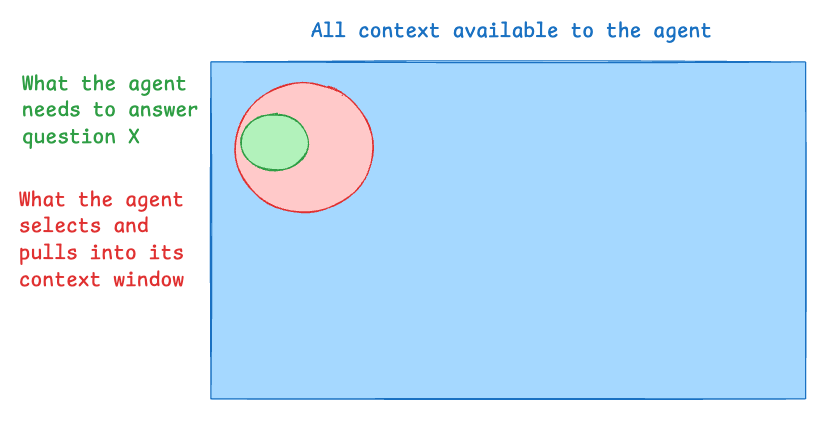
从这个视角来看,有很多方式可以使代理的上下文工程“失败”:
- 如果代理需要的上下文不在总上下文中,代理将无法成功。例如:客户支持代理需要访问某个文档页面来回答问题,但该页面尚未被索引。
- 如果代理检索的上下文不包含代理所需的上下文,则代理将无法正确回答。例如:客户支持代理需要访问某个文档页面来回答问题,该页面存在且已被索引,但代理未检索到它。
- 如果代理检索的上下文远大于代理所需的上下文,则代理将浪费资源(时间、令牌或两者)。例如:客户支持代理需要一个特定的页面,但代理检索了100个页面。
作为代理工程师,我们的工作是使检索的上下文与所需的上下文相匹配(确保代理检索的上下文是所需信息的最小超集)
在寻找适当的上下文时,会出现一些特定的挑战:
- 令牌过多(检索的上下文 >> 所需的上下文)一些工具,如网页搜索,可以返回大量的令牌。几个网页搜索可以快速积累到对话历史中的数万个令牌。您可能最终会遇到一个烦人的400错误,但在那之前,您的LLM账单会迅速增加,性能会下降。
- 需要大量上下文(所需的上下文 > 支持的上下文窗口)有时,代理可能需要大量信息来回答问题。这种信息通常无法在单个搜索查询中返回,这就是为什么许多人转向“代理搜索”(让代理重复调用搜索工具)的想法。然而,这种方法的问题是上下文的数量会迅速增长到无法全部放入上下文窗口的程度。
- 找到细致的信息(检索的上下文 ≠ 所需的上下文)代理可能需要引用埋藏在数百或数千个文件中的细致信息来处理输入。代理如何可靠地找到这种信息?如果找不到,那么检索的上下文将不是回答问题所需的上下文。是否有替代的方法(或补充)语义搜索?
- 随时间学习(总上下文 ≠ 所需的上下文)有时,代理可能没有访问回答问题所需的上下文(无论是在工具还是指令中)。最终用户可能会在与代理的交互中提供线索(隐式或显式),表明上下文可能是什么。代理是否可以在未来迭代中将其添加到上下文中?
这些都是常见的障碍,我们大多数人以前都面临过不同版本的这些问题!
文件系统如何使代理更好?
用简单的话来说:文件系统提供了一个单一的接口,代理可以通过它灵活地存储、检索和更新无限量的上下文。
让我们看看这如何帮助上述每种情况。
令牌过多 (检索的上下文 >> 所需的上下文)
代理不必使用对话历史来存储所有工具调用结果和笔记,而是可以将它们写入文件系统,然后在需要时选择性地查找相关信息。Manus是第一个公开讨论这种方法的人(publicly talk about this approach)- 下面的图表来自他们的博客文章。
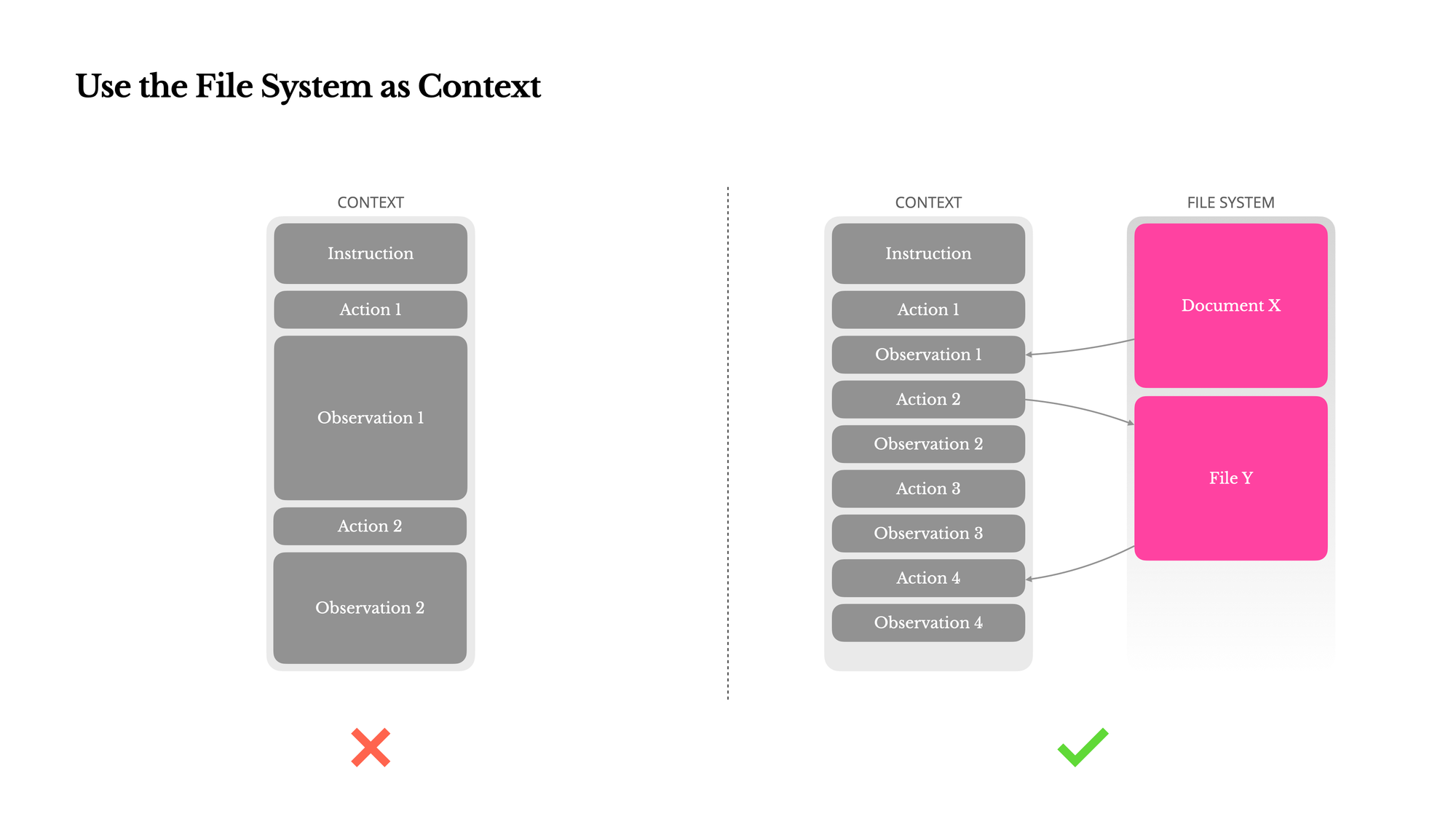
让我们考虑第一个例子,使用网页搜索工具。我运行网页搜索,并从工具中获取10k个令牌的原始内容。大部分内容可能并不总是必要的。如果我将其放入消息历史中,那么所有10k个令牌都将在整个对话过程中存在,增加我的Anthropic账单。但是,如果我将这个大型工具结果卸载到文件系统中,代理可以智能地使用grep搜索某些关键字,然后只读取必要的上下文到我的对话中。
在这个例子中,代理有效地使用文件系统作为大型上下文的临时存储。
需要大量上下文 (所需的上下文 < 支持的上下文窗口)
有时,代理需要大量上下文来回答问题。文件系统为LLM提供了一个很好的抽象,允许它们动态存储和检索更多信息。这种情况的例子包括:
- 对于长期的答案,代理需要制定计划并遵循它。通过将计划写入文件系统,代理可以稍后将此信息拉回上下文窗口,以提醒代理应该做什么(例如“通过背诵操纵注意力”)
- 为了浏览所有这些上下文,代理可能会创建子代理。随着这些子代理工作和学习东西,而不是只是将其发现回复给主代理,它们可以将知识写入文件系统(例如最小化电话游戏)
- 一些代理需要大量指令来执行任务。与其将所有这些指令塞入系统提示(并膨胀上下文),您可以将它们存储为文件,并让代理动态地读取它们(例如Anthropic技能)
找到细致的信息 (检索的上下文 ≠ 所需的上下文)
语义搜索是检索上下文的最流行方法之一。它在某些用例中可能有效,但取决于文档类型(例如技术API参考、代码文件),语义搜索可能由于缺乏语义信息而效果很差。
文件系统提供了一个替代方法,允许代理使用ls、glob和grep工具智能地搜索上下文。如果您最近使用过Claude Code,您就会知道它严重依赖glob和grep搜索来找到所需的上下文。这种技术成功的原因有几个:
- 当前的模型是专门训练的,以理解文件系统的遍历
- 信息通常已经以逻辑结构组织(目录)
- glob和grep允许代理不仅隔离特定的文件,还可以隔离特定的行和特定的字符
- read_file工具允许代理指定要从文件中读取哪些行
由于这些原因,在某些情况下,使用文件系统(以及文件系统提供的搜索功能)可以产生更好的结果。
请注意,语义搜索仍然可以很有用!并且可以与文件系统搜索一起使用。Cursor最近写了一篇博客,强调了同时使用两者的好处。
随时间学习 (总上下文 ≠ 所需的上下文)
代理出错的一个主要原因是它们缺乏相关的上下文。改进代理的一种好方法通常是确保它们可以访问正确的上下文。有时这可能看起来像添加更多的数据源或更新系统提示。
更新系统提示的常见做法是:
- 看到代理缺乏适当指令的例子
- 从主题专家那里获取相关指令
- 使用这些指令更新提示
通常,终端用户实际上是最好的主题专家。通过与代理的对话,他们可能会提供重要的线索(隐式或显式),表明正确的相关指令是什么。因此,考虑到这一点 - 是否有办法自动执行上述步骤中的第三步(使用这些指令更新提示)?
通常情况下,终端用户实际上是最好的领域专家。通过与代理的对话,他们可能会提供重要的线索(隐式或显式),以确定正确的相关指令。因此,考虑到这一点 - 是否有办法自动执行上述第三步(使用这些指令更新提示)?
我们认为代理的指令(或技能)与它们可能想要合作的任何其他上下文没有区别。文件系统可以作为代理存储和更新其自身指令的地方!
用户反馈一旦给出,代理就可以写入其自身的文件并记住一条重要信息。这对于快速、一次性的事实尤其有用,特别是可能为用户定制的内容,如其姓名、电子邮件或其他偏好。
这仍然是一个未完全解决的问题,并且是一个正在出现的模式,但这是LLM(大型语言模型)的一种令人兴奋的新方式,可以随着时间的推移增长其自身的技能和指令,确保在未来迭代中拥有必要的上下文。
查看深度代理如何使用其文件系统
我们有一个开源仓库,称为Deep Agents(Python、TypeScript),它允许您快速构建一个具有文件系统访问权限的代理。许多使用文件系统的上下文工程技巧都内置其中!可能会出现更多的模式 - 尝试Deep Agents并告诉我们您的想法!