我们如何使用抽象语法树(AST)将 Workflows 代码转换为可视化图表
内容
Cloudflare Workflows 是一个持久化执行引擎,让你能够串联多个步骤、在失败时重试,并在长时间运行的流程中持久保存状态。开发者会用 Workflows 来驱动后台代理(agent)、管理数据流水线、构建有人参与审批(human-in-the-loop)的系统等等。
上个月,我们宣布,如今每个部署到 Cloudflare 的工作流,都可以在控制台中看到完整的可视化流程图。
我们之所以构建这个功能,是因为如今能够将应用可视化,比以往任何时候都更重要。编码代理(coding agents)正在编写代码,而这些代码你可能会看,也可能不会看。然而,最终构建出来的结构形态依然至关重要:步骤如何连接、在哪里分支,以及实际到底发生了什么。
如果你以前见过可视化工作流构建器生成的图,它们通常基于某种声明式描述:JSON 配置、YAML、拖放操作等。但 Cloudflare Workflows 本质上就是代码。它们可以包含 Promises、Promise.all、循环、条件判断, 也可以嵌套在函数或类中。这种动态执行模型使得流程图渲染变得更复杂一些。
我们使用抽象语法树(Abstract Syntax Tree,AST)来静态推导流程图,追踪 Promise 与 await 之间的关系,以理解哪些逻辑是并行运行的,哪些会阻塞,以及各部分之间如何连接。
继续往下读,了解我们是如何构建这些流程图的;或者你也可以直接部署自己的第一个工作流,亲自看看生成出来的图。
下面是一个由 Cloudflare Workflows 代码生成的流程图示例:
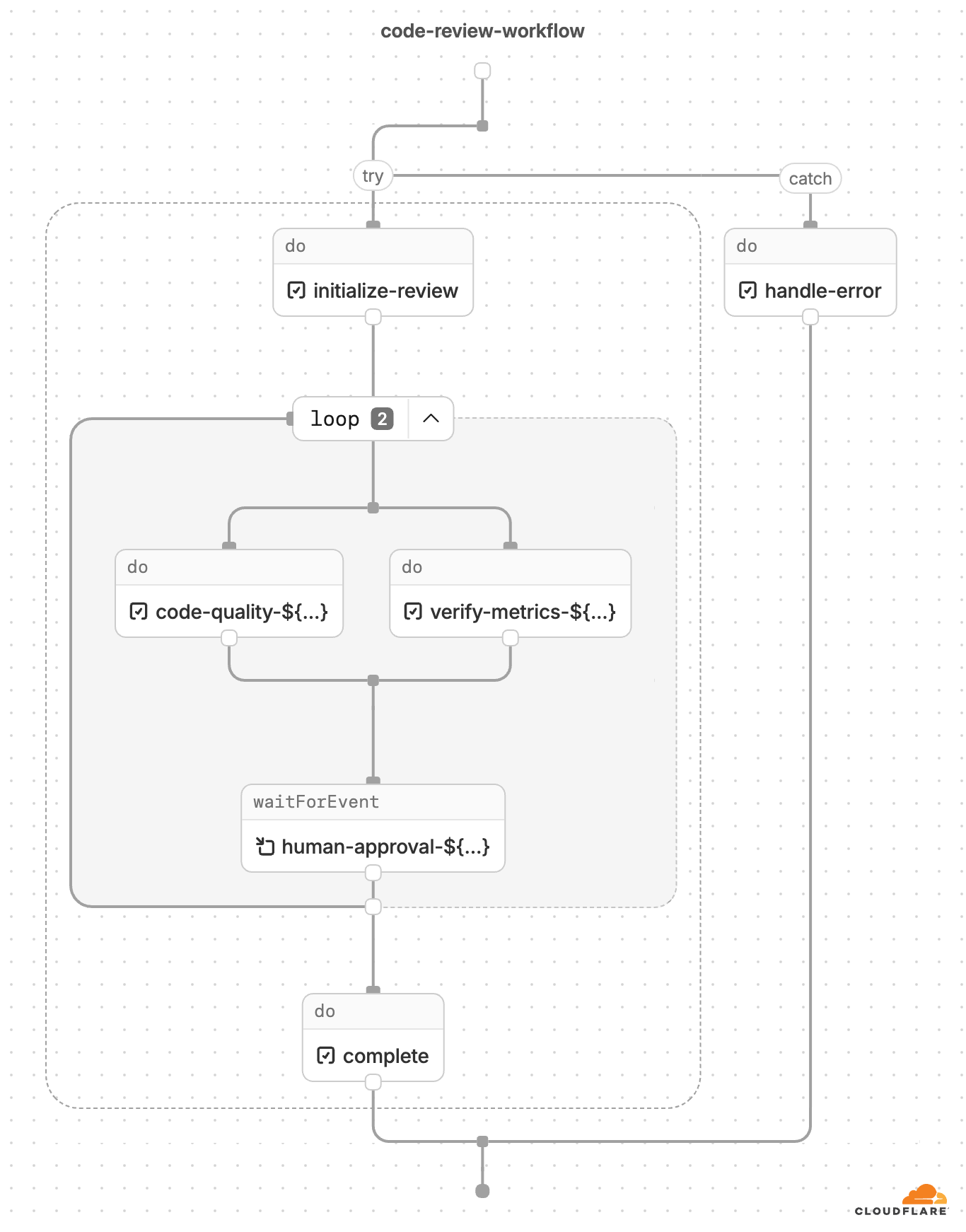
动态工作流执行
一般来说,工作流引擎通常会按动态执行顺序或顺序(静态)执行顺序来运行。顺序执行看起来也许更符合直觉:触发工作流 → 步骤 A → 步骤 B → 步骤 C,其中步骤 B 会在引擎完成步骤 A 后立即开始执行,以此类推。
Cloudflare Workflows 采用的是动态执行模型。由于工作流本身就是代码,步骤会在运行时遇到它们时执行。当运行时发现一个步骤时,这个步骤就会交给工作流引擎,由引擎负责管理其执行。除非显式 await,否则这些步骤并不是天然顺序执行的——所有未被 await 的步骤都会由引擎并行执行。这样一来,你就可以把工作流代码直接写成流程控制逻辑,而无需额外的包装层或指令。它们之间的交接过程如下:
- 会先启动一个引擎,它是该实例对应的“监督者”(supervisor)Durable Object。这个引擎负责实际工作流执行的逻辑。
- 引擎通过动态分发触发一个用户 Worker,将控制权交给 Workers 运行时。
- 当运行时遇到
step.do时,会把执行权再交还给引擎。 - 引擎执行该步骤,持久化结果(如果有需要也会抛出错误),然后再次触发用户 Worker。
在这种架构下,引擎并不会天然“知道”自己正在执行的步骤顺序——但对于流程图来说,步骤顺序却是关键信息。这里的挑战在于:如何把绝大多数工作流准确地转换成一个对诊断有帮助的图;当前流程图功能仍处于测试版(beta),我们会继续迭代并改进这些表示方式。
解析代码
在部署时而不是运行时获取脚本,使我们能够对整个工作流进行解析,从而静态生成流程图。
先退一步看,这就是一个工作流部署的生命周期:
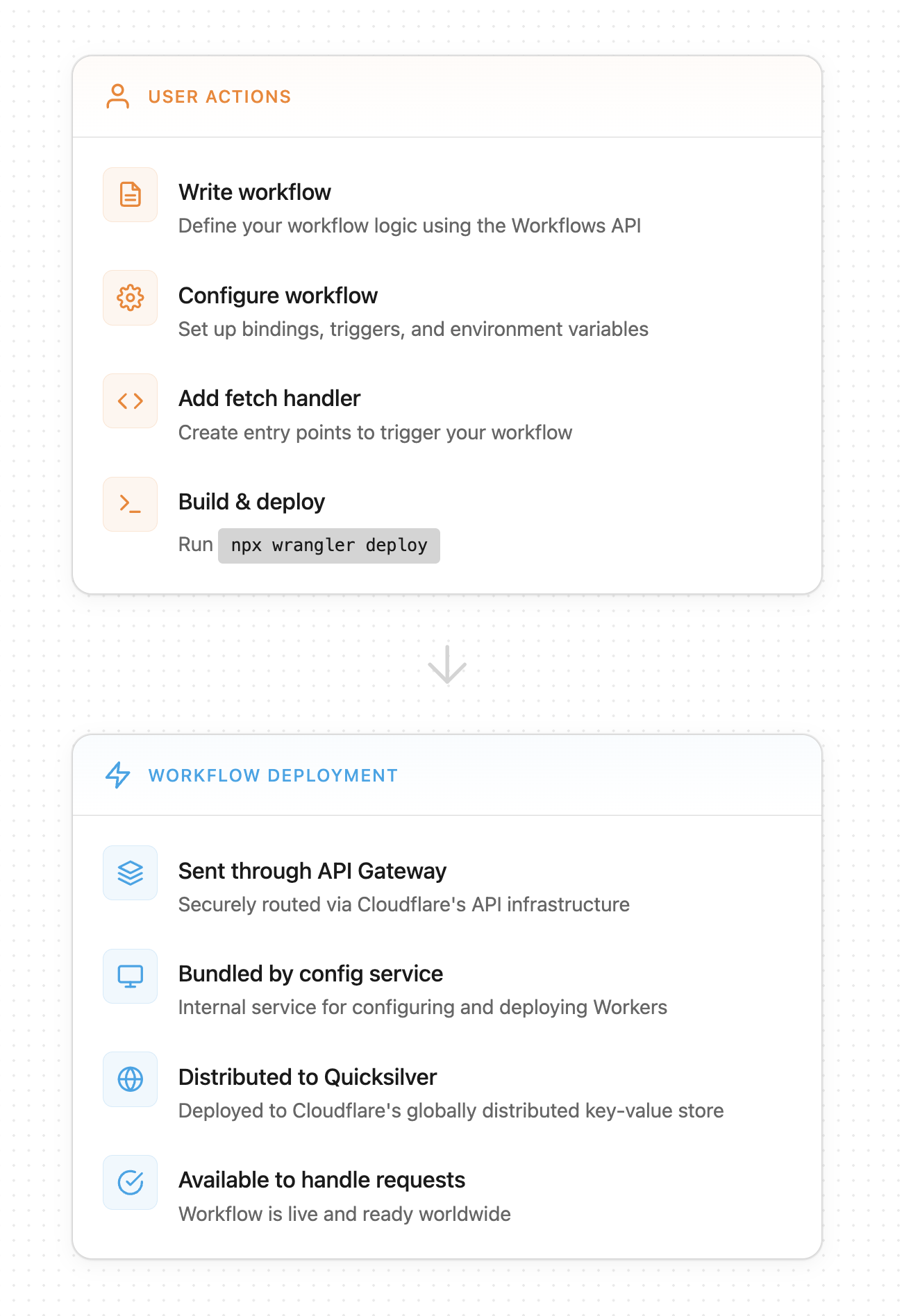
为了生成流程图,我们会在部署 Workers 的内部配置服务完成打包后获取脚本(即“Workflow deployment”中的第 2 步)。随后,我们使用解析器创建一个表示工作流的抽象语法树(AST),再由内部服务生成并遍历一个中间图结构,其中包含所有 WorkflowEntrypoint 以及对工作流步骤的调用。最后,我们根据 API 中的最终结果来渲染流程图。
当一个 Worker 被部署时,配置服务会对代码进行打包(默认使用 esbuild)并压缩,除非另有指定。这又带来了一个挑战——虽然 TypeScript 中的 Workflows 通常遵循一种直观的模式,但它们压缩后的 JavaScript(JS)往往会变得紧凑且难以阅读。而且根据打包器的不同,代码压缩的方式也会不同。
下面是一个展示代理并行执行的 Workflow 代码示例:
const summaryPromise = step. do (
`summary agent (loop ${loop} )` ,
async () => {
return runAgentPrompt (
this . env ,
SUMMARY_SYSTEM ,
buildReviewPrompt (
'Summarize this text in 5 bullet points.' ,
draft,
input. context
)
);
}
);
const correctnessPromise = step. do (
`correctness agent (loop ${loop} )` ,
async () => {
return runAgentPrompt (
this . env ,
CORRECTNESS_SYSTEM ,
buildReviewPrompt (
'List correctness issues and suggested fixes.' ,
draft,
input. context
)
);
}
);
const clarityPromise = step. do (
`clarity agent (loop ${loop} )` ,
async () => {
return runAgentPrompt (
this . env ,
CLARITY_SYSTEM ,
buildReviewPrompt (
'List clarity issues and suggested fixes.' ,
draft,
input. context
)
);
}
);
使用 rspack 打包后,压缩代码片段大致如下:
class pe extends e { async run ( e,t ){ de ( "workflow.run.start" ,{ instanceId :e. instanceId }); const r= await t. do ( "validate payload" , async ()=>{ if (!e. payload . r2Key ) throw new Error ( "r2Key is required" ); if (!e. payload . telegramChatId ) throw new Error ( "telegramChatId is required" ); return { r2Key :e. payload . r2Key , telegramChatId :e. payload . telegramChatId , context :e. payload . context ?. trim ()}}),s= await t. do ( "load source document from r2" , async ()=>{ const e= await this . env . REVIEW_DOCUMENTS . get (r. r2Key ); if (!e) throw new Error ( `R2 object not found: ${r.r2Key} ` ); const t=( await e. text ()). trim (); if (!t) throw new Error ( "R2 object is empty" ); return t}),n= Number ( this . env . MAX_REVIEW_LOOPS ?? "5" ),o= this . env . RESPONSE_TIMEOUT ?? "7 days" ,a= async (s,i,c)=>{ if (s>n) return le ( "workflow.loop.max_reached" ,{ instanceId :e. instanceId , maxLoops :n}), await t. do ( "notify max loop reached" , async ()=>{ await se ( this . env ,r. telegramChatId , `Review stopped after ${n} loops for ${e.instanceId} . Start again if you still need revisions.` )}),{ approved :! 1 , loops :n, finalText :i}; const h=t. do ( `summary agent (loop ${s} )` , async ()=> te ( this . env , "You summarize documents. Keep the output short, concrete, and factual." , ue ( "Summarize this text in 5 bullet points." ,i,r. context )))...
或者,使用 vite 打包后,压缩片段会像这样:
class ht extends pe {
async run ( e, r ) {
b ( "workflow.run.start" , { instanceId : e. instanceId });
const s = await r. do ( "validate payload" , async () => {
if (!e. payload . r2Key )
throw new Error ( "r2Key is required" );
if (!e. payload . telegramChatId )
throw new Error ( "telegramChatId is required" );
return {
r2Key : e. payload . r2Key ,
telegramChatId : e. payload . telegramChatId ,
context : e. payload . context ?. trim ()
};
}), n = await r. do (
"load source document from r2" ,
async () => {
const i = await this . env . REVIEW_DOCUMENTS . get (s. r2Key );
if (!i)
throw new Error ( `R2 object not found: ${s.r2Key} ` );
const c = ( await i. text ()). trim ();
if (!c)
throw new Error ( "R2 object is empty" );
return c;
}
), o = Number ( this . env . MAX_REVIEW_LOOPS ?? "5" ), l = this . env . RESPONSE_TIMEOUT ?? "7 days" , a = async (i, c, u) => {
if (i > o)
return H ( "workflow.loop.max_reached" , {
instanceId : e. instanceId ,
maxLoops : o
}), await r. do ( "notify max loop reached" , async () => {
await J (
this . env ,
s. telegramChatId ,
`Review stopped after ${o} loops for ${e.instanceId} . Start again if you still need revisions.`
);
}), {
approved : ! 1 ,
loops : o,
finalText : c
};
const h = r. do (
`summary agent (loop ${i} )` ,
async () => _ (
this . env ,
et,
K (
"Summarize this text in 5 bullet points." ,
c,
s. context
)
)
)...
压缩代码很快就会变得相当“狰狞”——而且根据打包器不同,还会以各种不同的方式“狰狞”。
我们需要一种办法,既快又准确地解析各种形式的压缩代码。我们最终认为,来自 JavaScript Oxidation Compiler(OXC)的 oxc-parser 非常适合这项工作。最开始,我们通过运行 Rust 容器来验证这个思路。每个脚本 ID 都会被发送到一个 Cloudflare Queue,随后消息被取出并发送到容器中处理。确认这种方法可行后,我们将其迁移到了用 Rust 编写的 Worker 中。Workers 支持通过 WebAssembly 运行 Rust,而且这个包体积足够小,使得迁移过程相当直接。
这个 Rust Worker 的职责,首先是将压缩后的 JS 转换为 AST 节点类型,然后再把 AST 节点类型转换成会在控制台中渲染出来的工作流图形版本。为此,我们会为每个工作流生成一个由预定义节点类型组成的图结构,并通过一系列节点映射,将其转换为我们自己的图表示形式。
渲染流程图
将工作流渲染成流程图版本时,有两个挑战:一是如何正确追踪步骤与函数之间的关系,二是如何在尽可能简单的前提下定义工作流节点类型,同时覆盖足够全面的使用场景。
为了确保步骤与函数之间的关系能被正确追踪,我们需要同时收集函数名和步骤名。正如前面提到的,引擎本身只掌握步骤的信息,但一个步骤可能依赖于某个函数,反过来也可能存在函数依赖步骤的情况。例如,开发者可能会把步骤封装在函数中,或者把函数定义成步骤。他们也可能会在某个函数中调用来自不同模块的步骤,或者对步骤进行重命名。
虽然解析库帮我们跨过了第一道门槛,给出了 AST,但我们仍然要决定如何对其进行解析。有些代码模式需要额外发挥一些“创造力”。例如函数:在一个 WorkflowEntrypoint 内,可能存在一些函数,它们会直接调用步骤、间接调用步骤,或者根本不调用步骤。考虑这样一种情况:functionA 中包含 console.log(await functionB(), await functionC()),其中 functionB 会调用一个 step.do()。在这种情况下,functionA 和 functionB 都应该出现在工作流流程图中;但 functionC 不应该出现。为了捕获所有包含直接或间接步骤调用的函数,我们会为每个函数创建一个子图,并检查它本身是否包含步骤调用,或者它是否调用了另一个可能包含步骤调用的函数。这些子图会用函数节点来表示,函数节点中包含它所有相关的节点。如果某个函数节点是图中的叶子节点,也就是说它内部既没有直接也没有间接的工作流步骤,那么它就会从最终输出中被裁剪掉。
我们还会检查其他模式,包括一组静态步骤列表——我们可以据此推断工作流图——以及最多可通过十种不同方式定义的变量。如果你的脚本中包含多个工作流,我们会采用与函数子图类似的模式,只不过抽象层级再提高一层。
对于每一种 AST 节点类型,我们都必须考虑它们在工作流中的各种使用方式:循环、分支、Promise、并行、await、箭头函数……不一而足。即便是在这些类别之内,也存在几十种可能。仅以循环方式为例,就有下面这些写法:
for ( const item of items) {
await step. do ( `process ${item} ` , async () => item);
}
while (shouldContinue) {
await step. do ( 'poll' , async () => getStatus ());
}
await Promise . all (
items. map ( ( item ) => step. do ( `map ${item} ` , async () => item)),
);
await items. forEach ( async (item) => {
await step. do ( `each ${item} ` , async () => item);
});
再比如,除了循环之外,还要考虑如何处理分支:
switch (action. type ) {
case 'create' :
await step. do ( 'handle create' , async () => {});
break ;
default :
await step. do ( 'handle unknown' , async () => {});
break ;
}
if (status === 'pending' ) {
await step. do ( 'pending path' , async () => {});
} else if (status === 'active' ) {
await step. do ( 'active path' , async () => {});
} else {
await step. do ( 'fallback path' , async () => {});
}
await (cond
? step. do ( 'ternary true branch' , async () => {})
: step. do ( 'ternary false branch' , async () => {}));
const myStepResult =
variableThatCanBeNullUndefined ??
( await step. do ( 'nullish fallback step' , async () => 'default' ));
try {
await step. do ( 'try step' , async () => {});
} catch (_e) {
await step. do ( 'catch step' , async () => {});
} finally {
await step. do ( 'finally step' , async () => {});
}
我们的目标,是设计一个简洁的 API,传达开发者真正需要了解的信息,而不过度复杂化。但把工作流转换成流程图,就意味着必须覆盖所有可能的模式——无论它们是否符合最佳实践——以及各种边界情况。正如前面提到的,默认情况下,每个步骤并不会对其他步骤形成显式的顺序关系。如果一个工作流没有使用 await 和 Promise.all(),我们会假定步骤会按运行时遇到它们的顺序执行。但如果工作流中包含 await、Promise 或 Promise.all(),我们就需要一种方式来追踪这些关系。
最终我们决定追踪执行顺序:每个节点都带有 starts: 和 resolves: 字段。starts 和 resolves 的索引表示:某个 promise 是在什么时候开始执行的,以及它相对于第一个已开始但尚未立即结束的 promise,是在什么时候结束的。这与流程图 UI 中的垂直位置相对应(也就是说,所有 starts:1 的步骤都会在同一行内对齐)。如果步骤在声明时就被立即 await,那么 starts 和 resolves 都会是 undefined,此时工作流将按照步骤在运行时中出现的顺序执行。
在解析过程中,当我们遇到一个未被 await 的 Promise 或 Promise.all() 时,该节点(或这些节点)会被标记一个入口编号,并体现在 starts 字段中。如果随后遇到对该 promise 的 await,入口编号就会加一,并保存为出口编号(也就是 resolves 的值)。这样我们就能知道哪些 promise 是同时运行的,以及它们相对于彼此会在何时完成。
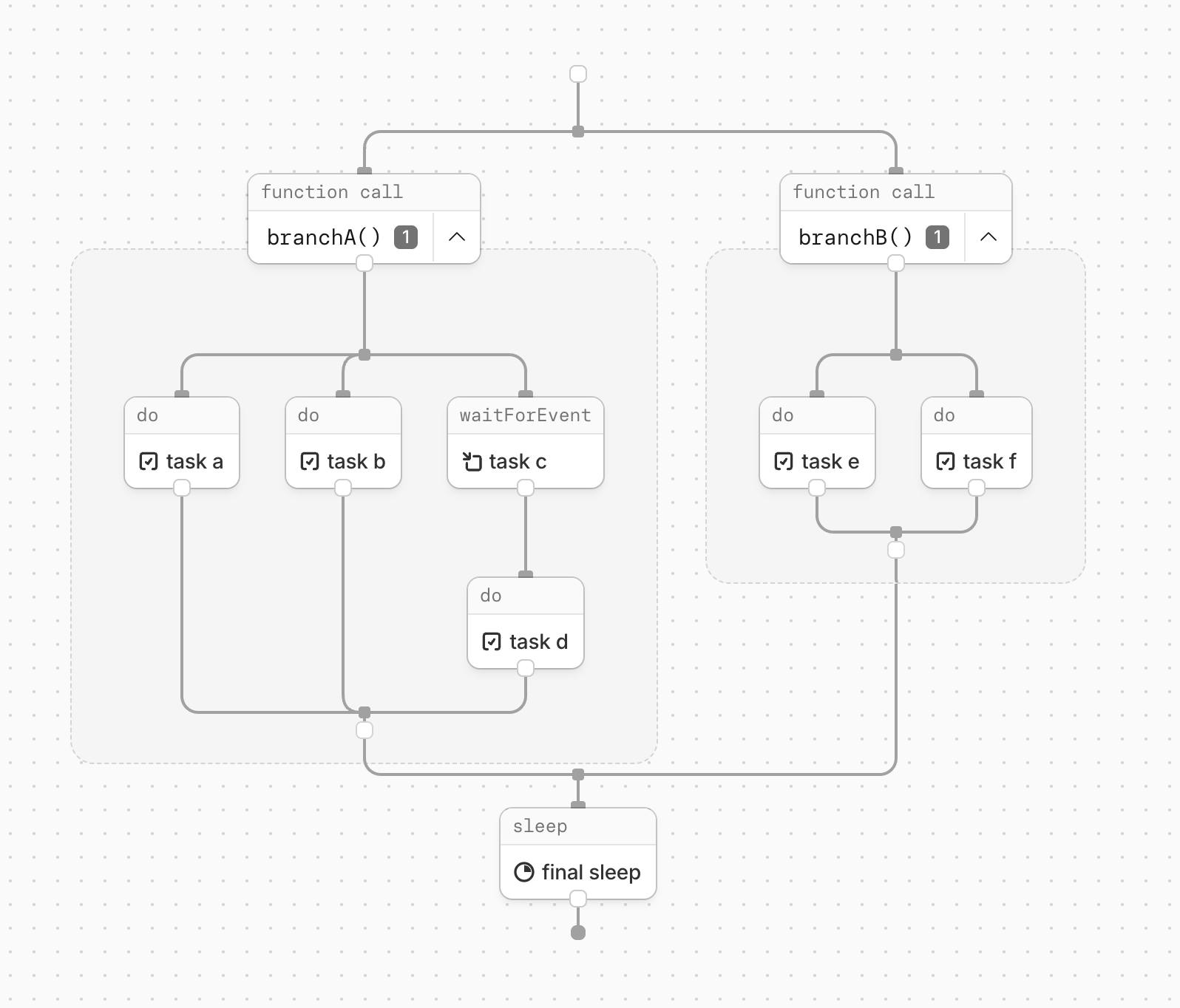
export class ImplicitParallelWorkflow extends WorkflowEntrypoint < Env , Params > {
async run ( event : WorkflowEvent < Params >, step : WorkflowStep ) {
const branchA = async ( ) => {
const a = step. do ( "task a" , async () => "a" );
const b = step. do ( "task b" , async () => "b" );
const c = await step. waitForEvent ( "task c" , { type : "my-event" , timeout : "1 hour" });
await step. do ( "task d" , async () => JSON . stringify (c));
return Promise . all ([a, b]);
};
const branchB = async ( ) => {
const e = step. do ( "task e" , async () => "e" );
const f = step. do ( "task f" , async () => "f" );
return Promise . all ([e, f]);
};
await Promise . all ([ branchA (), branchB ()]);
await step. sleep ( "final sleep" , 1000 );
}
}
你可以在流程图中看到这些步骤的对齐方式:
在覆盖完所有这些模式之后,我们最终确定了如下节点类型列表:
| StepSleep
| StepDo
| StepWaitForEvent
| StepSleepUntil
| LoopNode
| ParallelNode
| TryNode
| BlockNode
| IfNode
| SwitchNode
| StartNode
| FunctionCall
| FunctionDef
| BreakNode;
下面是几种不同行为对应的 API 输出示例:
function 调用:
{
"functions": {
"runLoop": {
"name": "runLoop",
"nodes": []
}
}
}
if 条件分支到 step.do:
{
"type": "if",
"branches": [{
"condition": "loop > maxLoops",
"nodes": [{
"type": "step_do",
"name": "notify max loop reached",
"config": {
"retries": {
"limit": 5,
"delay": 1000,
"backoff": "exponential"
},
"timeout": 10000
},
"nodes": []
}]
}]
}
包含 step.do 和 waitForEvent 的 parallel:
{
"type": "parallel",
"kind": "all",
"nodes": [{
"type": "step_do",
"name": "correctness agent (loop ${...})",
"config": {
"retries": {
"limit": 5,
"delay": 1000,
"backoff": "exponential"
},
"timeout": 10000
},
"nodes": [],
"starts": 1
},
...{
"type": "step_wait_for_event",
"name": "wait for user response (loop ${...})",
"options": {
"event_type": "user-response",
"timeout": "unknown"
},
"starts": 3,
"resolves": 4
}
]
}
接下来会做什么
归根结底,这些 Workflow 流程图的目标,是成为一个全功能的调试工具。这意味着你将能够:
- 实时沿着图追踪一次执行过程
- 发现错误、等待人工审批(human-in-the-loop),并可为测试目的跳过某些步骤
- 在本地开发中访问可视化视图
你可以前往自己的 Workflow 概览页面查看这些流程图。如果你有任何功能建议,或者发现了任何问题,欢迎加入 Discord 上的 Cloudflare Developers 社区,直接向 Cloudflare 团队反馈。