内容
过去几周,我们一直在将开源大语言模型接入 Deep Agents 的 harness 评估体系,初步结果显示:它们不仅是闭源前沿模型的替代方案,甚至可以作为补充使用。GLM-5(z.ai)和 MiniMax M2.7 在文件操作、工具调用和指令遵循等核心智能体任务上的表现,已与闭源前沿模型相当。
如果你一直关注开源模型进展(例如通过 SWE-Rebench 和 Terminal Bench 2.0 等公开基准),这并不意外。工具调用稳定可靠,指令遵循也保持一致。对于在生产环境中部署智能体的开发者而言,开源模型如今已具备足够的稳定性和可预测性,使真实世界的自动化工作流变得切实可行。
为什么选择开源模型?
在探索开源模型时,开发者和客户通常会关注几个关键因素:成本、延迟 和 任务性能。
理想情况下,我们希望为每个任务都使用推理能力最强的闭源前沿模型。但在现实中,成本和延迟两大限制使得这一设想难以落地。闭源前沿模型在高吞吐场景下运行成本高出 8–10 倍,且响应速度往往无法满足用户对交互式产品的即时反馈需求。
| 模型 | 类型 | 输入($/M tokens) | 输出($/M tokens) |
|---|---|---|---|
| Claude Opus 4.6 (Anthropic) | 闭源 | $5.00 | $25.00 |
| Claude Sonnet 4.6 (Anthropic) | 闭源 | $3.00 | $15.00 |
| GPT-5.4 (OpenAI) | 闭源 | $2.50 | $15.00 |
| GLM-5 (Baseten) | 开源 | $0.95 | $3.15 |
| MiniMax M2.7 (OpenRouter) | 开源 | $0.30 | $1.20 |
背景说明:一个每日输出 1000 万 token 的应用,在 Opus 4.6 上日均成本约$250,而在 MiniMax M2.7 上仅需约 $12。这意味着每年可节省约 $8.7万 美元。
相比闭源前沿模型,开源模型通常规模更小,但可通过专用推理基础设施加速——例如 Groq、Fireworks 和 Baseten 等平台在延迟和吞吐量优化方面远超大多数团队自建系统的能力。OpenRouter 数据显示,GLM-5 在 Baseten 上平均延迟为 0.65 秒,输出速度达每秒 70 token;而 Claude Opus 4.6 分别为 2.56 秒和每秒 34 token。对于对延迟敏感的产品,这种差距难以通过工程手段弥补。
我们的评估方法
我们在 《如何为 Deep Agents 构建评估体系》 一文中详细阐述了评估方法论。所有评估均基于托管式推理服务运行,但 Deep Agents 也支持完全本地化部署,例如通过 Ollama、vLLM 等本地模型运行。
针对开源模型,我们设置了七类评估项目:文件操作、工具调用、检索、对话、记忆、摘要生成和“单元测试”。这些任务检验的是基础能力:模型是否能可靠调用工具、遵循结构化指令、操作文件?这些是决定模型是否可用于任何智能体框架的前提条件。
每个评估用例定义了成功断言(硬性失败检查,用于判断正确性)和效率断言(软性检查,衡量模型达成目标的方式)。我们报告四项指标:
- 正确率 —— 模型解决问题的测试用例比例:通过数 / 总数。得分 0.68 表示 68% 的测试被正确解决,这是核心质量信号。
- 解决率 —— 准确性与速度的综合度量。对每项测试,计算
预期步骤 / 实际耗时,失败测试贡献为零。最终得分为所有测试的平均值,越高越好——既能正确完成任务又快速的模型得分最高。 - 步骤比 —— 模型实际执行的智能体步骤数与预期步骤数的比值:总实际步骤 / 总预期步骤。值为 1.0 表示恰好按预期执行。高于 1.0 表示效率较低(需更多步骤);低于 1.0 则表示比预期更高效。
- 工具调用比 —— 与步骤比类似,但统计的是单个工具调用次数。1.0 表示预算内,高于为超预算,低于为节余。
步骤比和工具调用比属于效率指标,不影响测试是否通过,但能揭示模型如何经济地达成答案。例如,一个模型用 2 步完成任务而非预期的 5 步,既正确又高效。
评估结果概览
这些仍是早期结果,我们正在持续维护和扩展评估集。您可在 GitHub Actions 页面 实时查看最新运行记录,也可访问 共享的 LangSmith 项目。
开源模型
查看 CI 运行记录(点击模型名称可查看单项评估)
| 模型 | 正确率 | 通过数 | 解决率 | 步骤比 | 工具调用比 |
|---|---|---|---|---|---|
| baseten:zai-org/GLM-5 | 0.64 | 94 / 138 | 1.17 | 1.02 | 1.06 |
| ollama:minimax-m2.7 | 0.57 | 85 / 138 | 0.27 | 1.02 | 1.04 |
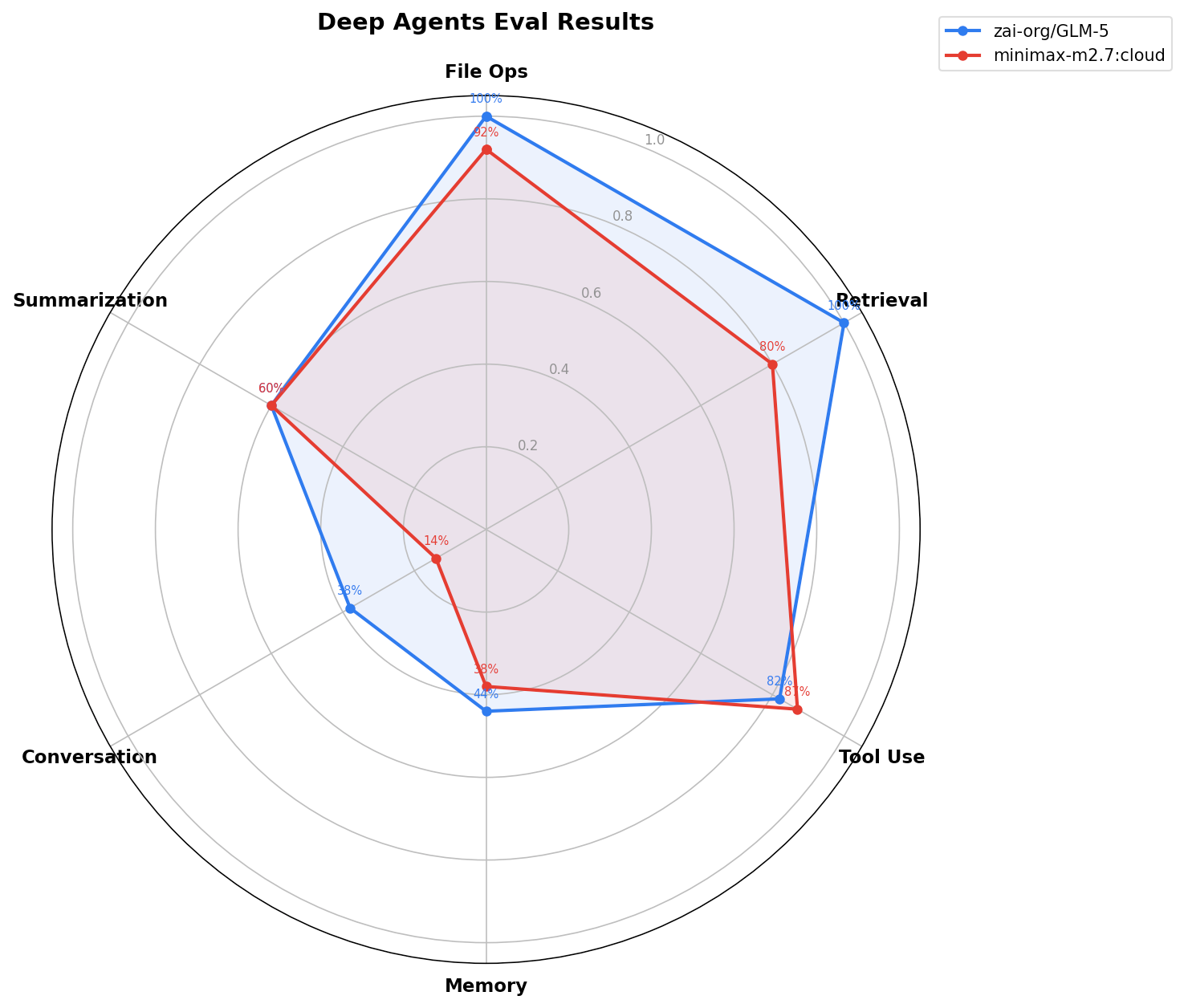 分类型正确率:
分类型正确率:
| 模型 | 对话 | 文件操作 | 记忆 | 检索 | 摘要 | 工具调用 | 单元测试 |
|---|---|---|---|---|---|---|---|
| baseten:zai-org/GLM-5 | 0.38 | 1 | 0.44 | 1 | 0.6 | 0.82 | 1 |
| ollama:minimax-m2.7:cloud | 0.14 | 0.92 | 0.38 | 0.8 | 0.6 | 0.87 | 0.92 |
闭源前沿模型
查看 CI 运行记录(点击模型名称可查看单项评估)
| 模型 | 正确率 | 通过数 | 解决率 | 步骤比 | 工具调用比 |
|---|---|---|---|---|---|
| anthropic:claude-opus-4-6 | 0.68 | 100 / 138 | 0.38 | 0.99 | 1.02 |
| google_genai:gemini-3.1-pro-preview | 0.65 | 96 / 138 | 0.26 | 0.99 | 1.01 |
| openai:gpt-5.4 | 0.61 | 91 / 138 | 0.61 | 1.05 | 1.15 |
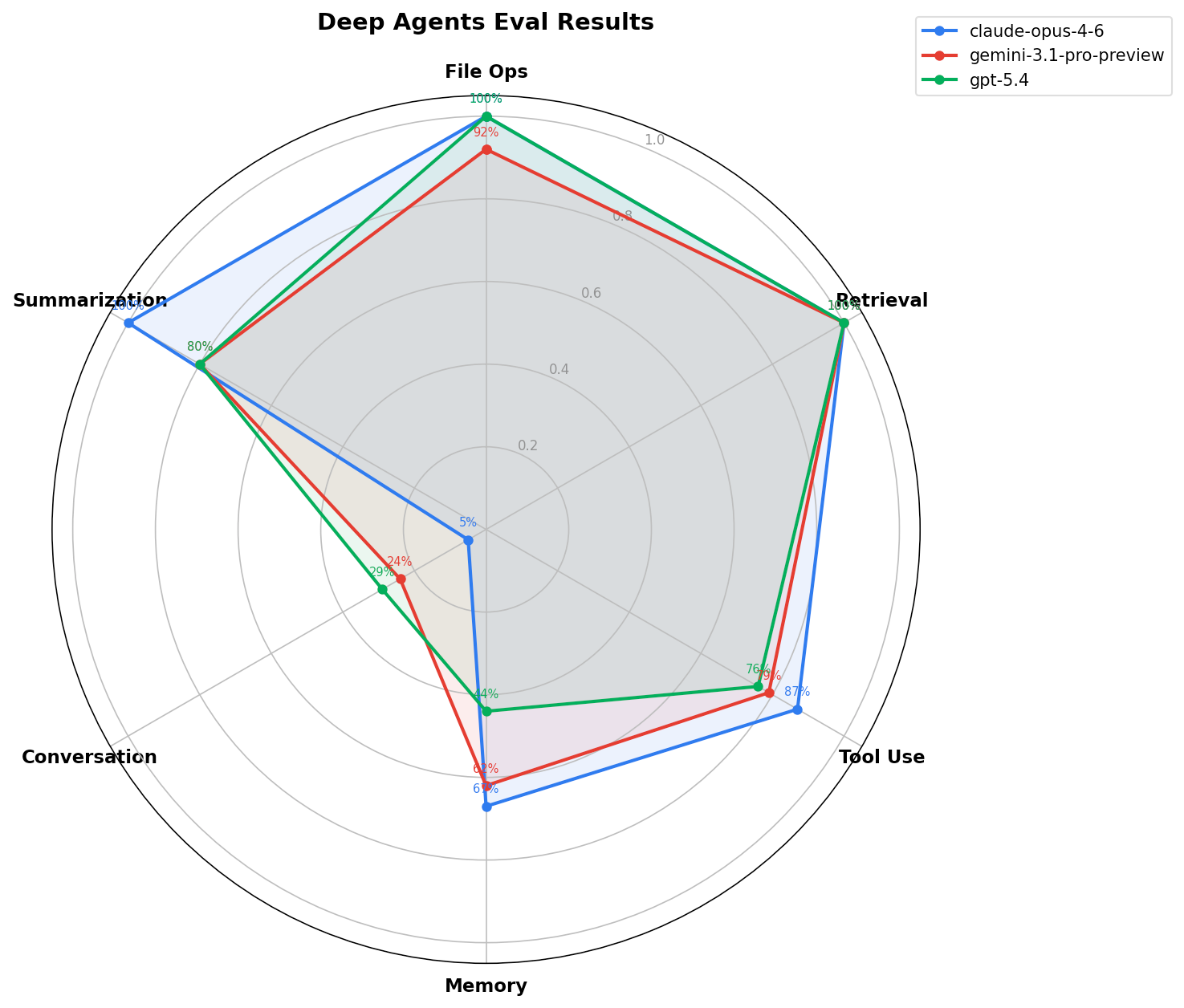 分类型正确率:
分类型正确率:
| 模型 | 对话 | 文件操作 | 记忆 | 检索 | 摘要 | 工具调用 | 单元测试 |
|---|---|---|---|---|---|---|---|
| anthropic:claude-opus-4-6 | 0.05 | 1 | 0.67 | 1 | 1 | 0.87 | 1 |
| google_genai:gemini-3.1-pro-preview | 0.24 | 0.92 | 0.62 | 1 | 0.8 | 0.79 | 0.92 |
| openai:gpt-5.4 | 0.29 | 1 | 0.44 | 1 | 0.8 | 0.76 | 1 |
所有模型均采用提供商默认的思考级别设置。 Gemini 3+ 为 high,OpenAI 为 medium,Claude 为无扩展思考模式。
DIY:在本地运行 Deep Agent 评估
我们的 CI 系统会在包含 52 个模型的评估套件中统一运行,这些模型按组划分——其中 open 组(包括 baseten:zai-org/GLM-5、ollama:minimax-m2.7:cloud、ollama:nemotron-3-super)每次评估都会自动执行。您可指定任意模型组运行:
查看所有开源模型评估:: pytest tests/evals --model-group open
针对特定模型运行:pytest tests/evals --model baseten:zai-org/GLM-5
这使得比较不同开源模型与闭源前沿模型在同一任务上的表现变得简单,且使用统一的评分标准。
在 Deep Agents SDK 中使用开源模型
切换至开源模型只需一行代码修改:
GLM-5:
# pip install langchain-baseten
from deepagents import create_deep_agent
agent = create_deep_agent(model="baseten:zai-org/GLM-5")
MiniMax M2.7:
# pip install langchain-openrouter
from deepagents import create_deep_agent
agent = create_deep_agent(model="openrouter:minimax/minimax-m2.7")
就这么简单。Harness 会自动处理其余逻辑——识别模型上下文窗口大小、禁用不支持的功能模态,并在系统提示中注入正确的身份信息,让智能体清楚自己正在使用何种模型。
同一开源模型常可通过多个提供商获取。选择最符合你约束条件的即可。例如 GLM-5 可通过 baseten:zai-org/GLM-5、fireworks:fireworks/glm-5 或自托管方式 ollama:glm-5 使用。同样是该模型,同样使用 Harness,只是底层基础设施不同。
LangChain 目前支持主流开源模型提供商:Baseten、Fireworks、Groq、OpenRouter 和 Ollama(云端)。
针对模型的 Harness 级适配
开源模型在上下文窗口、工具调用格式及失败模式上与闭源前沿模型存在差异。Deep Agents Harness 已内置对这些差异的抽象,无需开发者额外处理:
- 模型身份注入 —— 运行时动态修补系统提示,加入模型名称、提供商、上下文限制和支持的功能模态。智能体能明确知道自己是什么、能做什么。
- 上下文管理 —— 压缩、卸载和摘要生成的阈值会根据模型的实际上下文窗口自适应调整,而非硬编码默认值。例如 4K 上下文的模型会比拥有 100 万 token 的 Opus 采用更激进的压缩策略。
Deep Agents CLI
每个模型也集成于 Deep Agents CLI。Deep Agents CLI 是我们的开源编程智能体,可作为 Claude Code 的替代方案。
除了 SDK 的全部功能外,CLI 还支持 运行时模型切换。我们引入了一个新的中间件(ConfigurableModelMiddleware),允许会话中途更换模型而无需重启智能体。这支持“闭源模型规划 + 开源模型执行”等混合架构。
通过 /model 斜杠命令即可实现会话中切换模型。例如可以先以闭源模型启动任务进行规划,再切换到低成本的开源模型执行具体操作。
后续计划
我们即将分享以下内容:
- 针对不同开源模型家族的 Harness 调优模式文档
- 多模型子智能体配置测试(例如:闭源模型作为协调器 + 开源模型作为执行子智能体)
如今,开源模型已适用于智能体场景。我们希望展示那些帮助我们构建良好 Harness 并设计精准评估体系的设计模式,真正衡量对你任务有价值的部分。
Deep Agents 是开源项目。欢迎尝试你偏爱的开源模型,和我们一起打造出色的评估体系和智能体吧。