内容
我于今天在 O'Reilly AI CodeCon 上发表了关于编排编码智能体(coding agents)的演讲。本次分享涵盖了协调现实世界软件工作流程中 AI 编码智能体的各种模式——从启动第一个子智能体,到运行具有质量保障机制的并行智能体团队,确保所有输出都值得信赖。本文是对我演讲内容的整理,旨在帮助大家将这些模式付诸实践。
如果你想跟随互动式幻灯片学习或获取所有相关资料,请参考以下链接:

我们所处的历史时刻
过去你只与一个 AI 结对编程。如今你管理的是一整个智能体团队。
六个月前,大多数开发者都通过一个紧密同步的循环与单个 AI 助手协作:你输入提示词,等待响应,审阅输出,给予反馈,然后重复这一过程。你的能力上限受限于单次对话的上下文窗口大小,而整个对话线程就是你的工作空间。
如今,这种模式已被取代。最具生产力的开发者正在协调多个异步运行的智能体——每个智能体都有独立的上下文窗口、文件作用域和职责范围,而你作为开发者则进行顶层调度。代码库变成了你的画布,而非对话记录。这标志着从“指挥者”(conductor,一人实时指导)到“管弦乐指挥”(orchestrator,管理整个乐团异步协作)的转变。我在文章 《Agentic Coding 的未来》 中曾探讨过这一转变的早期迹象。
本次演讲将重点讲解如何实际落地这一转型:包括所需模式、工具、质量保障机制以及必要的纪律性。
AI 辅助编码的八个层级
大多数开发者目前仍停留在第 3-4 级。而真正的编排层级始于第 6 级,它需要一套与达到第 5 级截然不同的技能体系。
Steve Yegge 最近提出了开发者与 AI 工具协同演进的八个层级框架,这对理解自身所处位置及未来方向很有帮助。
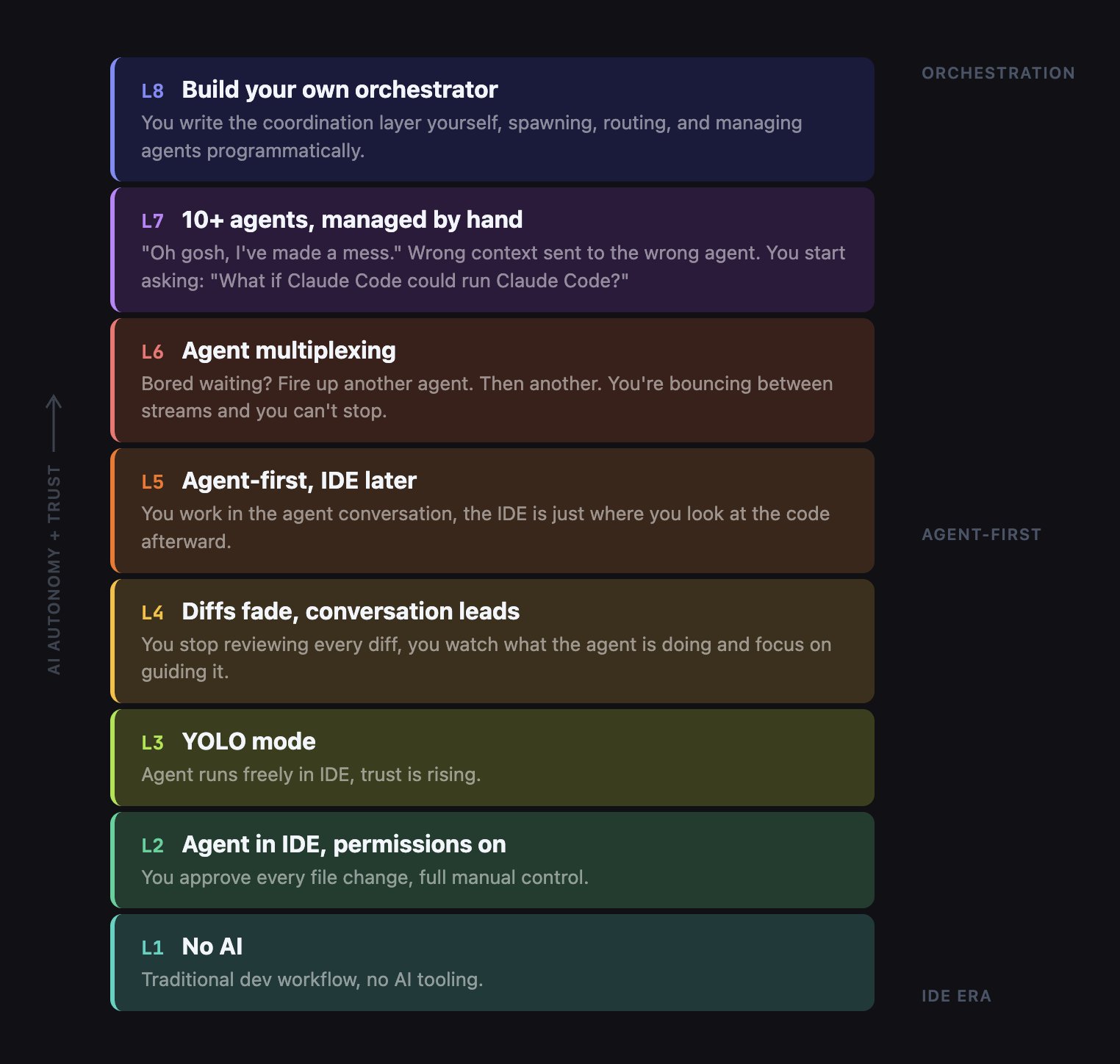
本次演讲聚焦于第 5 至第 8 级。你在哪一级?
核心转变:指挥者 → 管弦乐指挥
指挥者模型仅提供单一智能体,同步交互,且上下文窗口是硬性天花板;而管弦乐指挥模型则支持多个拥有独立上下文窗口的智能体,在异步协作中由你进行规划与检查。
这一转变的核心心智模型差异,在于从结对编程(pair programming)到管理团队的区别。在指挥者模型中,你实时引导单个 AI 智能体,整个过程同步、顺序执行,上下文窗口成为硬性限制。代表工具包括 Claude Code CLI 和 Cursor 编辑器内的智能体模式。
而在管弦乐指挥模型中,你需要协调一整支智能体乐团。多个智能体各自拥有独立上下文窗口,以异步方式工作。你负责规划任务、分配工作,并定期检查进度。代表工具包括 Agent Teams、Conductor、Codex 和 Copilot Coding Agent。
就像管理真实团队一样,现在你需要掌握不同的技能:清晰的规格说明(specs)、任务分解能力,以及对输出的验证能力,而不是自己编写代码。
单智能体的天花板
每位开发者最终都会遇到三个瓶颈:上下文过载、缺乏专业化分工,以及无法实现协调。子智能体解决了前两个问题,而智能体团队则同时解决了全部三个问题。
为什么一个智能体无法包揽所有工作?原因在于三大约束:
上下文过载。单个智能体能承载的信息量有限,大型代码库会迅速耗尽其上下文窗口容量,导致重要细节随着对话增长而被遗忘。
缺乏专业化。让一个智能体同时处理数据层、API、UI 和测试,相当于让其成为“样样通却无一精”的通才。专注于数据层的智能体,其编写的数据库代码质量显著高于那些需要兼顾整个代码库的通用型智能体。
无法协调。即使你尝试派生子智能体,它们之间也无法通信、共享任务清单或解决依赖关系。没有协调原语的情况下增加更多智能体,只会让问题愈发复杂化。
为何选择多智能体协作?
并行性、专业化、隔离性和复合学习能力并非简单叠加,而是呈指数级放大效应。三个专注的智能体,其表现始终优于一个通用型智能体连续工作三倍时长。
转向多智能体的四大复合优势如下:
- 并行性(3 倍吞吐量提升):前端、后端和测试三个智能体可同时推进开发。
- 专业化(聚焦上下文):每个智能体仅接触自己负责的文件。例如,仅了解
db.js的智能体,其编写的数据库代码质量远高于需要处理整个代码库的智能体。 - 隔离性(安全执行环境):Git worktree 为每个智能体提供独立工作目录,避免并发修改冲突。
- 复合学习:通过维护一份 AGENTS.md 文件,系统可积累跨会话的模式识别和经验教训,使每次新会话都比上一次更优。
模式一:子智能体 —— 精准委派
子智能体是最简单的多智能体模式,也是你应该首先尝试的方案。
子智能体利用 Task 工具,由父级编排器(parent orchestrator)创建专门化的子代智能体。父级将任务拆解为若干部分,分别为每部分创建子智能体,并手动管理依赖关系图。
以下是一个具体示例:你向 Claude Code 输入提示词:“使用 Express 和 SQLite 构建一个名为 Link Shelf 的书签管理器。”父级编排器将其分解为三个子智能体任务:
- 数据层子智能体:构建
db.js文件,包含 schema 和 CRUD 操作,完成后生成DATA.md报告; - 业务逻辑子智能体:构建
validation.js,定义输入规则,完成后生成LOGIC.md报告; - API 路由子智能体:读取上述两份报告后,构建
server.js,集成 Express 路由。
前两个子智能体相互独立,可并行执行;第三个则需等待前两者的报告文件就绪后方可启动。父级需手动管理此依赖关系图。
演示 1:子智能体构建 Link Shelf
观看父级如何解析提示词,并行启动 Data 和 Validation 子智能体,待两者报告就绪后再启动 API Routes 子智能体,最终通过全部测试。
子智能体解决的问题:实现智能体间的上下文隔离与专业化分工,支持独立任务的并行执行,总体 token 消耗基本持平(约 22 万 tokens)。
仍存在的不足:父级必须手动管理依赖关系图,智能体间无对等通信机制,缺乏共享任务列表,若文件作用域划分不当,还可能导致多个智能体写入同一文件。
简而言之:子智能体实现了带手动协调的并行执行,适用于简单任务分解。但当协调本身成为瓶颈时,你就需要转向智能体团队(Agent Teams)。
进阶技巧:分层子智能体 —— 团队中的团队
不要止步于单层委派。让功能负责人(feature lead)自行招募自己的专家,这样可在不扩大任何智能体上下文负担的前提下,实现三倍的深度分解。
与其让顶层编排器直接派生六个子智能体(这会分散其注意力),不如派生两名功能负责人。每位负责人再分别招募两到三名专项专家。
此时顶层编排器只需与两名智能体交互,保持自身上下文清晰。例如 Feature Lead A 接到“构建搜索功能”的任务后,可自行将其拆分为 Data、Logic 和 API 子智能体。顶层编排器无需介入这些细节。
这种方式模仿了真实工程组织的运作模式:你不会让 CEO 直接给每位工程师分配任务,而是通过技术负责人层层传递指令。
模式二:智能体团队 —— 真正的并行执行
智能体团队引入了子智能体所缺失的关键协调机制:共享任务列表(含依赖追踪)、队友间点对点消息传递,以及防止冲突的文件锁定功能。
智能体团队(Agent Teams)是 Claude Code 的实验性功能,旨在实现真正的并行执行。启用方法如下:
export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1
其架构分为三层:
- 团队负责人(Team Lead):位于顶层,负责任务分解、创建任务清单、综合结果;
- 共享任务列表(中间层):包含状态为 pending/in_progress/completed/blocked 的任务,具备依赖追踪与文件锁定功能;
- 团队成员(底层):每个成员均为独立的 Claude Code 实例,拥有专属上下文窗口,运行于 tmux 分屏终端中。
团队成员可自主认领共享列表中的任务。他们之间直接通信(点对点),无需经过负责人。当某位成员完成任务并标记为完成时,所有依赖于此任务的阻塞任务将自动解除阻塞。任何时候按下 Ctrl+T 即可切换显示任务列表的可视化覆盖层。
演示 2:智能体团队并行构建搜索功能
这是核心演示环节。我们从已运行的 Link Shelf 应用出发,向 Claude Code 发出一条指令:“创建一个三人智能体团队,添加搜索功能。” 负责人随即派出 Backend、Frontend 和 Test 三位队友。后端队友开始构建搜索 API 端点,前端队友同步开发搜索 UI,测试队友初始处于阻塞状态——等待 API 就绪。一旦后端完成并向前端发送 API 契约,测试任务便自动解锁,三位队友得以同步推进。
演示 3:智能体团队近距离通信观察
这个简短演示聚焦于通信机制本身。你可以看到 Ctrl+T 任务列表覆盖层、后端标记 API 端点完成时测试任务自动解锁的过程,以及后端直接向发送 API 契约给前端(不经过负责人)的队友间点对点消息。
智能体团队的工作原理
两大机制支撑智能体团队的正常运行:一是具备自动依赖解析功能的共享任务列表,二是防止负责人成为瓶颈的队友间点对点通信。
共享任务列表为每个任务赋予状态(pending/in_progress/completed/blocked),其中阻塞任务明确指定依赖项。当后端队友标记搜索 API 完成时,原本阻塞的测试编写任务会自动转为 pending 状态,并由任意空闲队友接手。文件锁定机制确保同一时间只有一个队友能编辑特定文件。
点对点消息是另一关键组件。后端智能体直接告知前端智能体 API 契约:“GET /search?q= 返回 [{id,title,url}]”。此消息不经过负责人中转。当某位队友进入空闲状态时,负责人会自动收到通知。这种点对点设计有效避免了负责人成为协调瓶颈。
智能体团队的关键要点
三到五名队友是最佳规模。Token 成本随人数线性增长,而三名专注的队友通常优于五名分散的成员。
- 真正并行 + 协调保障:不仅是同时运行,而是通过带依赖追踪的共享任务列表确保工作按正确顺序执行。
- 点对点消息防瓶颈:队友间直接沟通。后端向前端传递 API 契约时无需负责人中介。
- 高风险任务需计划审批:要求队友在实施前先提交方案,由负责人审核批准或驳回,从而在代码产生前发现架构问题。
- 合理配置团队规模:三到五名队友是理想区间。Token 成本随团队规模线性上升。
智能体团队的可靠性进阶技巧
循环护栏(Loop Guardrails)配合强制反思步骤,能大幅减少卡死的智能体数量。配备专职 @reviewer 队友并在每次任务完成后自动触发审查,意味着负责人看到的始终是绿色审查通过的代码。
循环护栏 + 反思步骤。每位队友设置硬性 MAX_ITERATIONS=8 限制。每次重试前强制其执行反思提示:
“哪里失败了?具体什么改动可以修复?我是不是还在用同样的错误方法?”
这一简单调整就能显著降低卡死智能体的比例。没有它,智能体会陷入无限循环重复同一种失败策略;有了它,它们就能自我纠正。
专职 @reviewer 队友。部署一名常驻审查员,配置如下:
- 模型:Claude Opus 4.6(只读权限)
- 工具:仅允许 lint、test、security-scan
- 触发条件:TaskCompleted 事件自动触发
- 配比:每 3-4 名 builder 配 1 名 reviewer
如此一来,负责人看到的就全是经过绿色审查的代码。这相当于把持续集成(CI)的质量门禁内置到了团队内部。
模式三:规模化编排
当你需要管理 5、10 甚至 20 个以上智能体,横跨多个仓库和功能模块时,就需要专门的编排工具。截至 2026 年,所有工具均可归入三大层级——选择适合当前任务的层级即可。
2026 年的工具生态可分为三大层级:
第一层级:进程内子智能体与团队(In-process subagents and teams)
Claude Code 的子智能体和 Agent Teams。单终端会话即可完成,无需额外工具。从此起步。
第二层级:本地编排器(Local orchestrators)
你的本地机器启动多个智能体,各自运行于隔离的 worktree 中。你可通过仪表盘、diff 审查和合并控制保持参与感。最适合已知代码库上的 3-10 个并行智能体。代表工具包括 Conductor、Vibe Kanban、Gastown、OpenClaw + Antfarm、Claude Squad、Antigravity 和 Cursor Background Agents。
第三层级:云端异步智能体(Cloud async agents)
提交任务后合上笔记本,第二天回来就能看到拉取请求(PR)。智能体在云虚拟机中运行,无需终端或本地设置。代表工具包括 Claude Code Web、GitHub Copilot Coding Agent、Google 的 Jules,以及 OpenAI 的 Codex Web。
大多数 2026 年的开发者都会同时使用这三大层级:第一层级用于交互式开发,第二层级用于并行冲刺,第三层级则用来夜间清空积压任务。
工具亮点推荐
Melty Labs 的 Conductor
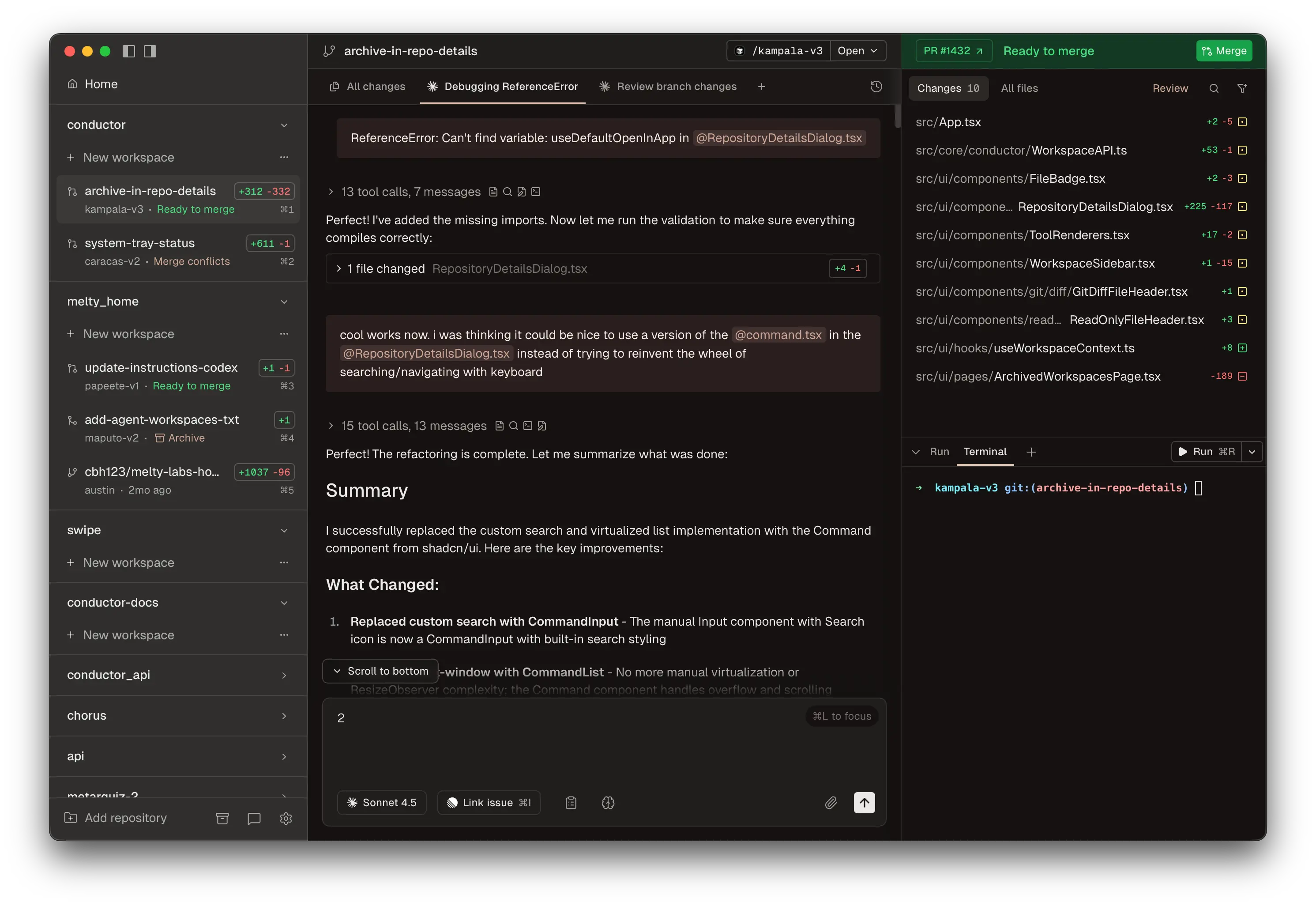
Conductor 是 Mac 平台上启动多智能体编排最快的方式。它能在各自的 git worktree 中并行运行多个 Claude Code 和 Codex 智能体,并提供可视化仪表盘和 diff-first 审查界面。完全免费——你只需支付 API 调用费用。目前仅限 macOS(Apple Silicon 和 Intel 均支持)。最佳适用场景是同一仓库上 3-8 个并行功能模块,辅以可视化监督。
Claude Code Web
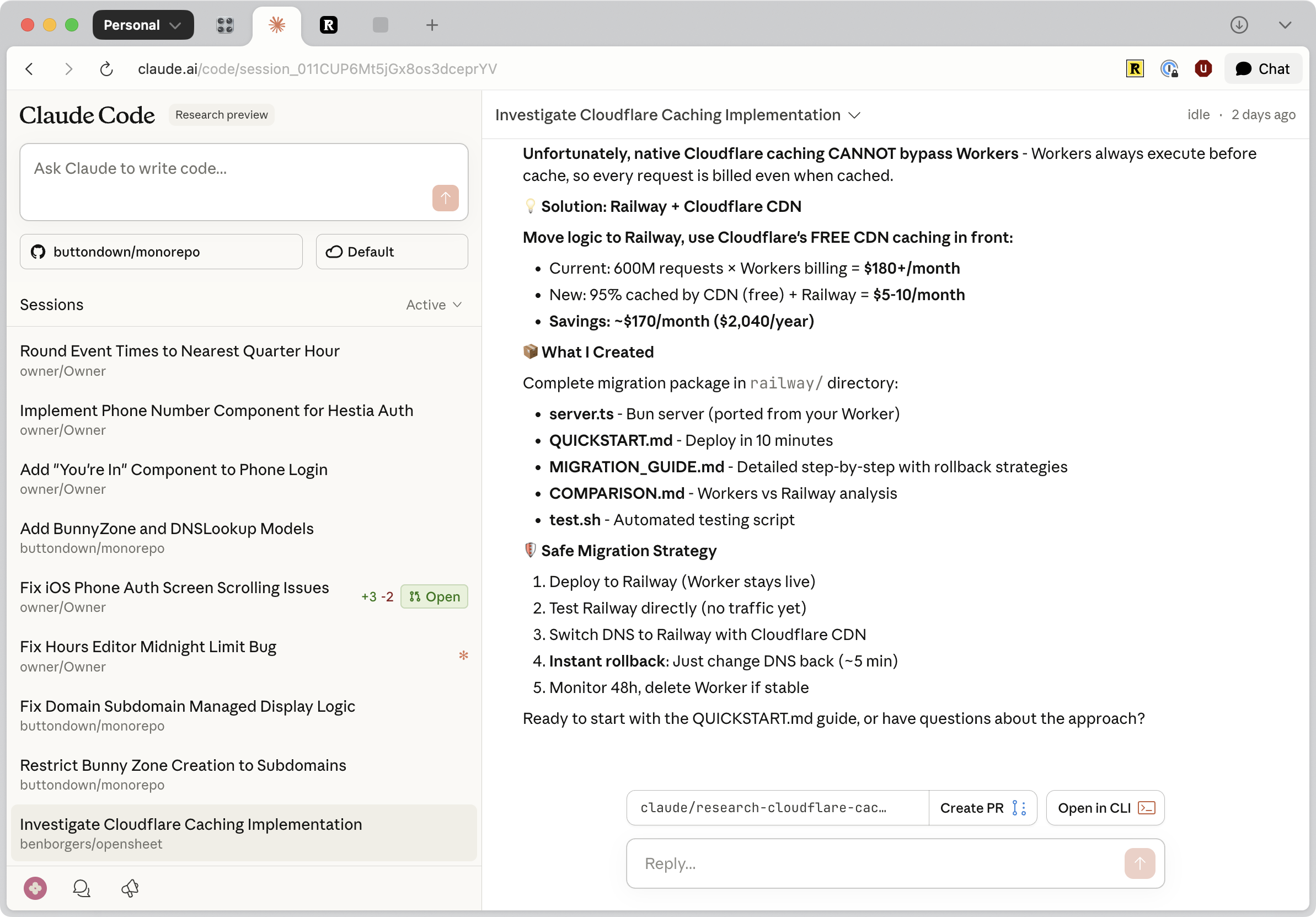
claude.ai/code 上的 Claude Code Web 版本是第一层级的云端形态——完全基于浏览器,无需终端。连接你的 GitHub 仓库,描述任务需求,智能体将在 Anthropic 托管的云虚拟机中运行。你可以在任务进行中干预调整,获得自动 PR 创建功能,并通过 iOS 应用访问。关键心智模型是:Teams(终端版)适合与智能体并肩工作;Web(浏览器版)则适合委托任务后离开。
GitHub Copilot 编码智能体
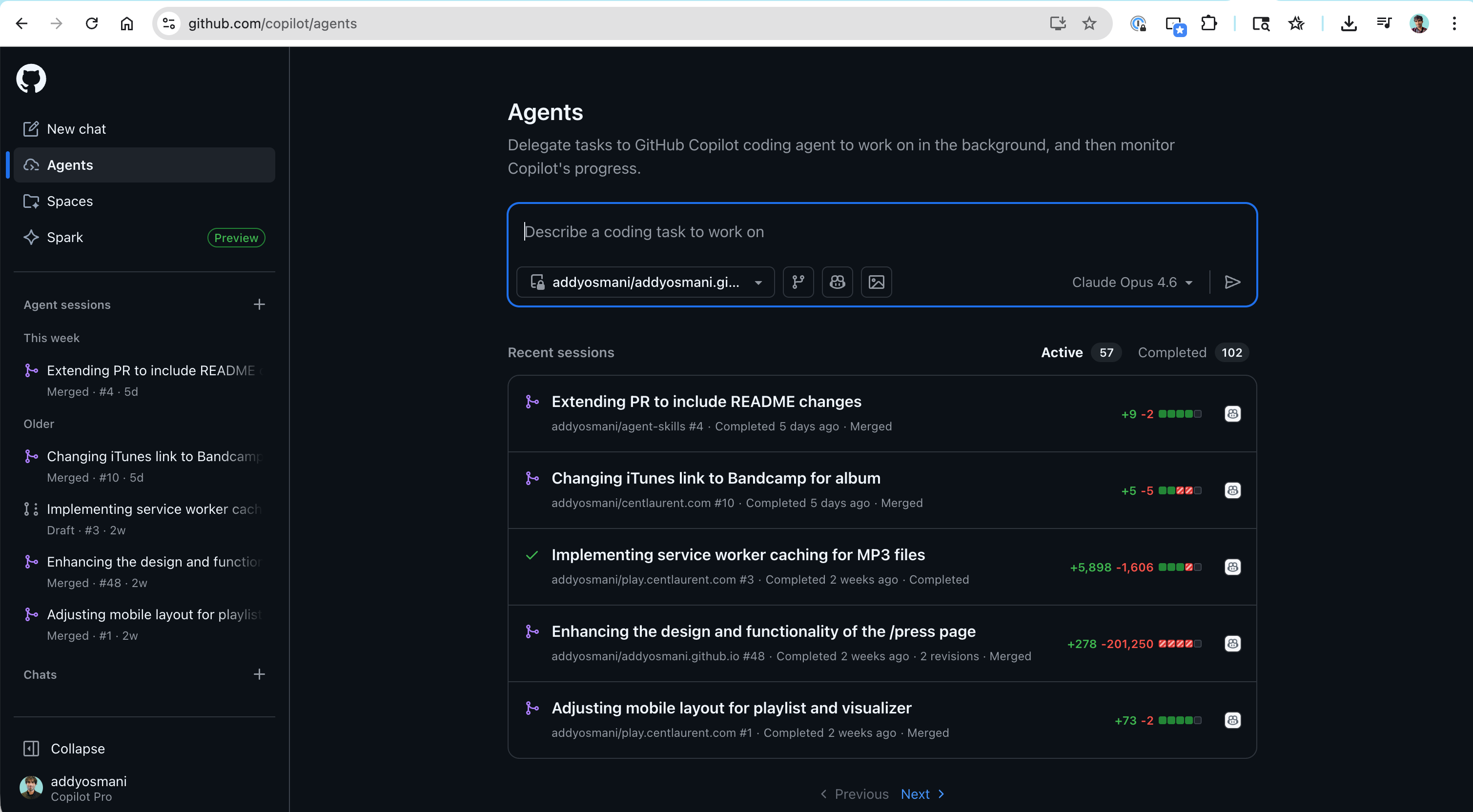
重要区分:IDE 中的 Copilot 智能体模式是同步且交互式的。而 GitHub 上的 Copilot Coding Agent 则是完全异步的。只需将任意 GitHub Issue 指派给 @copilot 或使用 Agents 面板,它就会在 GitHub Actions 环境中创建草稿 PR。现在它还会在标记你之前先执行自检流程。第三方智能体如 Claude Code 和 Codex 也可通过同一 Agents 面板访问,并支持从 Slack、Jira、Linear 和 Azure Boards 触发。
Google 的 Jules
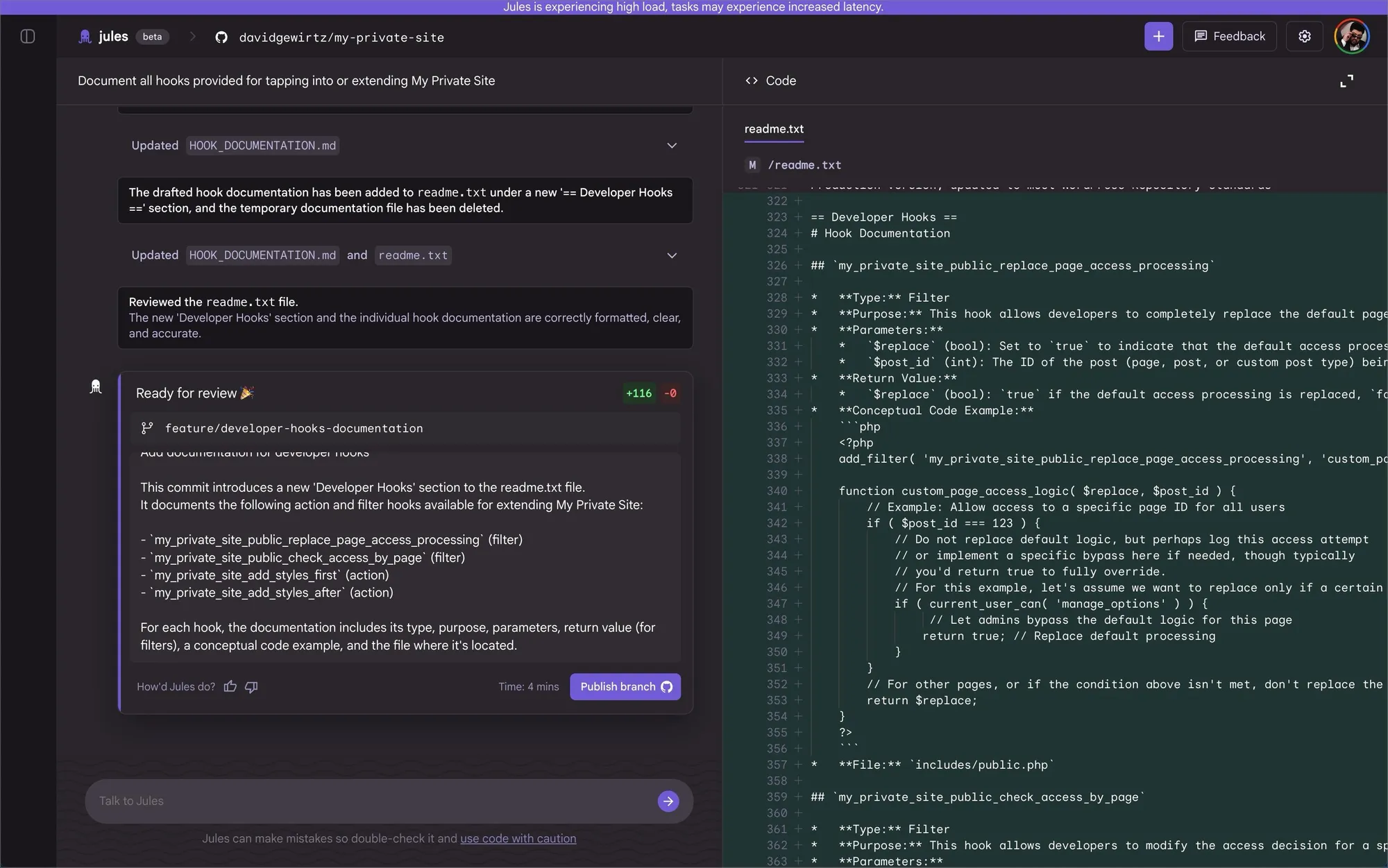
Jules 是 Google 开发的异步云端编码智能体,基于 Gemini 驱动。工作流程如下:连接 GitHub 仓库,描述任务,Jules 会生成一个你批准的计划(任何代码编写前必须经过此步),然后在云虚拟机中执行,最后返回带有完整推理过程和终端日志的 PR。特色功能包括音频变更日志、中途中断支持,以及 Jules Tools CLI(可直接导入 GitHub Issue)。它能自动读取你仓库中的 AGENTS.md,无需额外配置。
OpenAI Codex Web
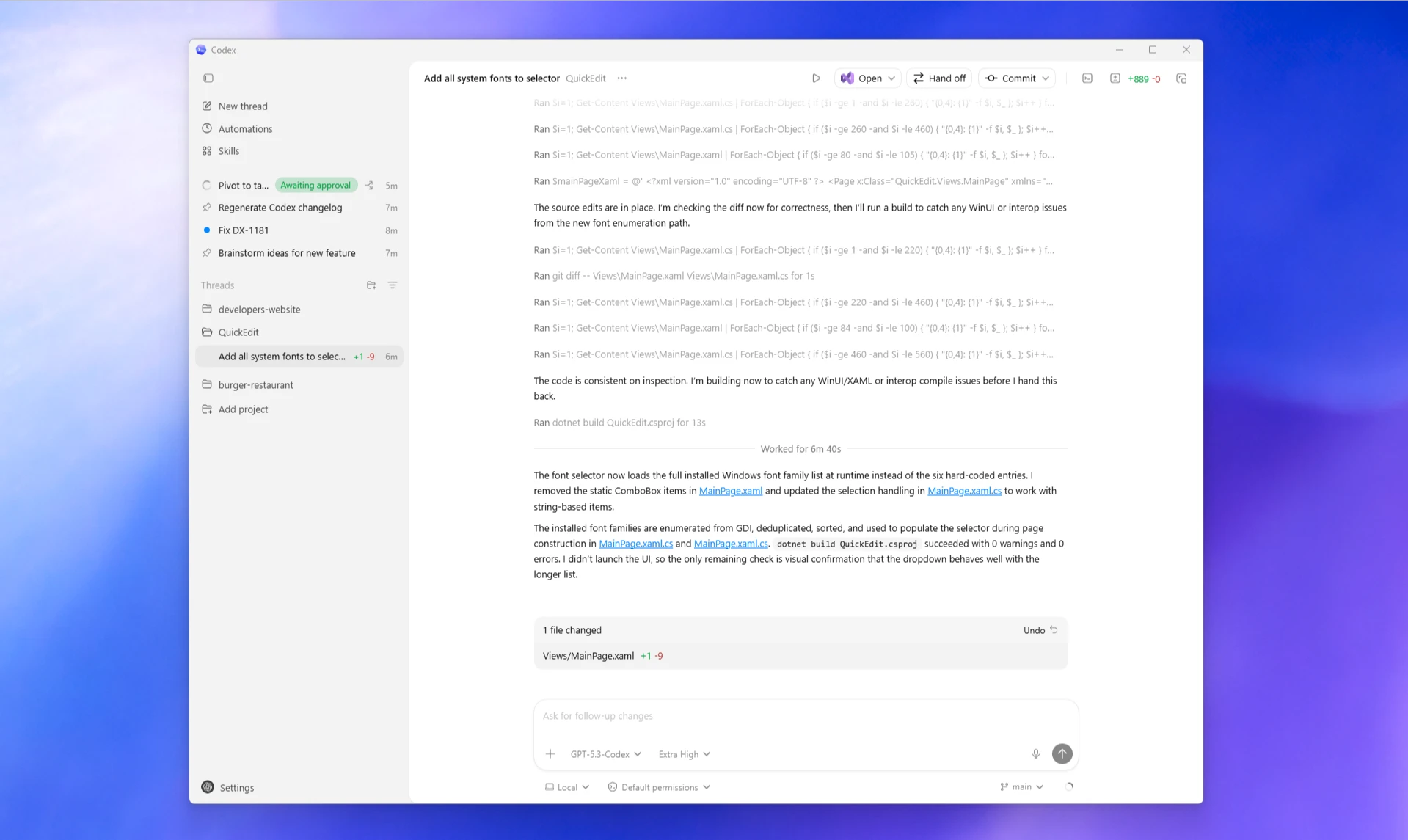
Codex Web 是该领域最广泛使用的工具之一。每个任务都在预加载了你 GitHub 仓库的沙盒容器中独立运行。其生态系统涵盖 Web、CLI(开源)、macOS App、IDE 插件和 GitHub 集成,全部通过你的 ChatGPT 账户关联。其“可验证证据”功能会为每个任务返回终端日志和测试输出的引用,让你能准确审计发生了什么。
Cursor Cloud Agents + Glass
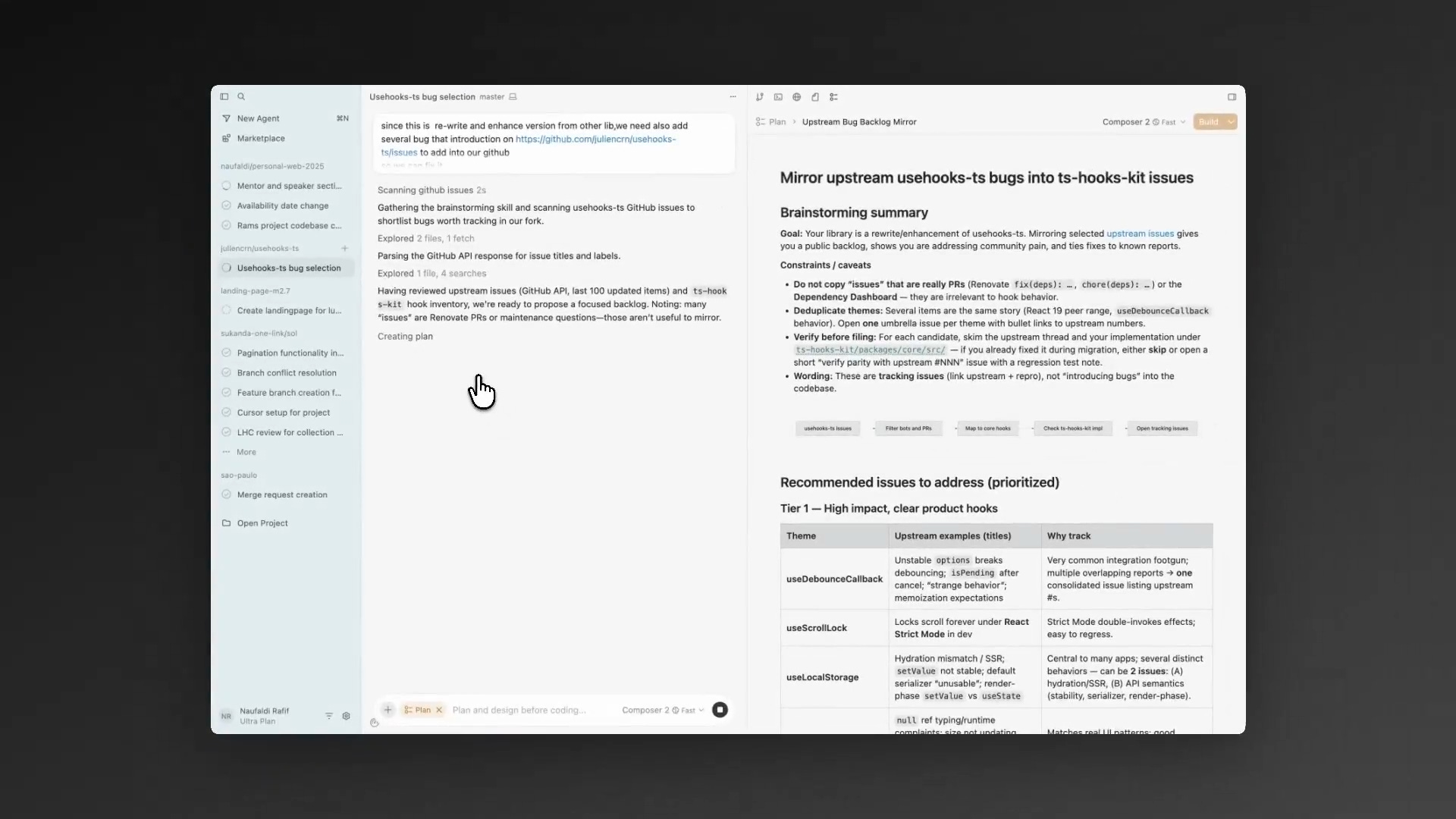
同样是智能体基础架构,但运行于隔离的云虚拟机中。你可以从网页、桌面应用、Slack、Linear、GitHub、API 甚至手机 PWA(cursor.com/agents)启动智能体。Glass 是 Cursor 的新界面,它将智能体管理设为主要交互面,传统编辑器仅在必要时使用。这反映了整个生态系统的普遍趋势:控制平面(control plane)正成为主要体验,而编辑器只是其中的一个工具。
Vibe Kanban
Vibe Kanban 解决了“ doomscrolling gap”——即智能体工作时你无事可做的 2-5 分钟空白期。你可以创建带详细提示词的任务卡片,拖拽至“进行中”列,每个任务都会获得独立的 worktree 和分支。在看板内直接审查 diff,并向运行中的智能体发送反馈。支持 Claude Code、Codex、Gemini CLI、Amp、Cursor Agent CLI 等多种工具。跨平台(Mac、Windows、Linux),免费,BYOK(自带密钥)。
规模化进阶技巧
多模型路由可在不牺牲质量的前提下降低成本。人工编写的 AGENTS.md 在任何长度下都优于机器生成的版本——研究表明 AI 撰写的规则不仅无效,反而可能轻微降低成功率(平均下降约 3%),同时增加超过 20% 的推理成本。
多模型路由
并非所有任务都需要最昂贵的模型。可将规划与架构任务路由至 Gemini/Claude/OpenAI 的较便宜模型,实现任务路由至 Sonnet、Opus 或 Codex,审查任务则分配给专用安全模型。创建 MODEL_ROUTING.md 文件:
Planning -> Gemini
Implementation -> Claude Opus or Sonnet
Review -> etc.
Tests -> etc.
Worktree 生命周期脚本
三个 shell 别名可自动化繁琐操作:
agent-spin <feature>
agent-merge <feature>
agent-clean
大约只需 12 行 bash 脚本。Conductor 已为你提供了可视化实现。
仅使用人工编写的 AGENTS.md
这是最关键的一点。研究表明(Gloaguen et al., ETH Zurich),LLM 生成的 AGENTS.md 文件不仅无效,反而可能轻微降低成功率(平均下降约 3%),同时增加超过 20% 的推理成本。相比之下,开发者手写的上下文文件能带来约 4% 的小幅提升。绝不要让智能体直接修改 AGENTS.md,每一行都必须经负责人批准。保持简洁,分块清晰:
## STYLE
- 使用带 hooks 的函数组件
- 优先采用命名导出
## GOTCHAS
- SQLite 需要开启 WAL 模式以支持并发读取
- Express 中间件顺序影响认证逻辑
## ARCH_DECISIONS
- 所有状态存储于 SQLite,不使用内存缓存
- 每个功能模块对应一个 Express 路由器
## TEST_STRATEGY
- API 路由优先使用集成测试而非单元测试
- 使用 supertest 进行 HTTP 断言
质量保障:信任但验证
三大质量保障机制可确保智能体输出可信:计划审批能在代码产生前发现糟糕的架构;钩子(hooks)在每次生命周期事件中强制执行自动化检查;AGENTS.md 则实现跨会话的知识累积。
计划审批。要求队友在编码前先提交方案,由负责人审核其思路是否合理,批准或驳回。相比修复糟糕的代码,修正糟糕的计划成本更低。流程如下:
队友 >>> 提交计划 >>> 负责人审查 >>> 批准/驳回 >>> 实施
钩子(Hooks)。在关键生命周期节点执行自动化检查。例如 TeammateIdle 钩子会在允许智能体停止工作前验证所有测试是否通过;TaskCompleted 钩子在标记任务完成前运行 lint 和测试。若钩子失败,智能体将继续工作直至通过:
任务完成 >>> 钩子运行 npm test >>> 通过?允许 | 失败?继续工作
AGENTS.md 实现知识累积。该文件记录已发现的模式、陷阱和风格偏好。每个会话开始时所有智能体都会读取它,而每次会话结束后都会更新它。第一次会话学会某个测试模式,更新 AGENTS.md,第二次会话就能避免同样错误。
瓶颈已转移
瓶颈不再是生成能力,而是验证。智能体能以惊人速度产出 impressive 的结果,但如何自信地判断这些结果是否正确,才是难点所在。
通过测试不代表能保证不引入回归。智能体可能写出技术上正确但遗漏关键场景的测试。上下文窗口限制意味着处理大型代码库的智能体可能忽略当前视图之外的重要约束。此外,原本对单个开发者而言只是烦人边缘情况的 flaky 环境,在四十个智能体同时遭遇同一 flaky 测试时会变成系统性阻塞。
在验证基础设施赶上生成能力之前,人工审查不是可选开销,而是安全系统。面对 impressive 的智能体输出,不应因其看起来不错就盲目信任,而应具备架构理解和测试纪律性,对其进行 rigorous 评估。
演示 4:质量保障与自改进智能体
这个演示整合了所有内容。请重点关注三点:第一,计划审批流程——某队友提议添加收藏功能,负责人发现其方案缺少数据库迁移步骤并驳回,队友据此修订;第二,任务完成时的钩子触发——TaskCompleted 钩子捕获到一个被遗忘的 console.log 语句,智能体自动修复后才标记任务完成;第三,结尾处 AGENTS.md 新增条目:“添加现有表列时必须包含 ALTER TABLE 迁移语句。” 这份学习成果将延续至所有未来会话。
Ralph 循环与自改进智能体
Ralph 循环模式将开发拆分为小而原子化的任务,并在无状态但迭代的循环中运行智能体。每个迭代周期包括:选择任务 → 实现 → 验证 → 若通过则提交 → 重置上下文并重复。这既避免了上下文溢出,又通过外部记忆维持连续性。
Geoffrey Huntley 和 Ryan Carson 推广的 Ralph 循环,正是“睡梦中交付”背后的模式。Carson 的独立工具 ralph(snarktank/ralph)实现了核心循环,而其 Antfarm 项目则在 OpenClaw 基础上叠加多智能体编排,沿用相同模式。该理念可泛化至各类工具。
五步循环如下:
- Pick:从 tasks.json 中选择下一个任务
- Implement:执行变更
- Validate:运行测试、类型检查和 lint
- Commit:若所有检查通过,则提交并更新任务状态
- Reset:清除智能体上下文,准备处理下一任务
关键洞察在于“无状态但迭代”。通过每次重置上下文,智能体避免积累混乱。小范围有界任务比单个巨大提示词更能产出干净代码,减少幻觉现象。
可靠性保障措施包括:将错误反馈给智能体以实现自动重试,但在卡住 3 次以上迭代后终止并重新分配。始终在特性分支上工作。为迭代次数、时间和 token 设置硬性限制。智能体打开 PR,你审查后再合并。
四种跨重置持久化记忆通道:git commit 历史、进度日志、任务状态文件(tasks.json)、以及作为长期语义记忆的 AGENTS.md。先从一次夜间循环开始,逐步过渡到十次循环、十个分支。
让智能体随时间变得更聪明
自反性(Self-Reflection)配合 REFLECTION.md 提案。每次任务后强制智能体撰写 REFLECTION.md:哪些地方出乎意料?应添加到 AGENTS.md 的一个模式是什么?如何改进提示词?负责人审核并合并批准的收获。这就是复合学习真正实现复合增长的方式——系统化而非临时性。
Token 预算与终止标准。为每个智能体设定硬性预算:前端 18 万 token,后端 28 万 token。达到 85% 预算时自动暂停并通知负责人。若在同一错误上卡住 3 次以上迭代,则终止并重新分配给全新智能体。
珠子(Beads)/ 持久化记忆。Gastown 的“珠子”模式:基于 git 的不可变决策与结果记录,附带完整溯源信息。智能体可通过任务图和 SQL 寻址的数据平面查询过往珠子——这不是传统的向量 RAG,而是结构化、可查询的机构记忆,远超扁平 markdown 文件的范畴。
纪律性:成功的关键
人类瓶颈曾是优势而非缺陷。以人类节奏编码时,错误缓慢累积,痛苦促使早期修正。但动用一整支智能体军队后,微小失误会以超出你察觉能力的速度累积。
人类写代码慢时,你会 early 感受到 pain。测试失败、代码审查发现问题、发现重复代码——这些痛苦是即时的,因此你能边做边 fix。
但当你指挥一整支智能体大军时,天然瓶颈消失了。无害的小错误——这里一个代码异味,那里一处重复,或是不必要的抽象——会以不可持续的速度累积。你把自己移出了循环,直到为时已晚才感受到痛苦。某天你想加新功能时却发现架构不允许,连你自己写的测试也变得同样不可信,因为智能体也参与了编写。
正因如此,每个质量保障机制都至关重要。计划审批、钩子、token 预算、人工审查——它们的存在不是因为“锦上添花”,而是因为缺了它们,你就会不知不觉地把系统推向死胡同。
委托任务,而非判断力
让智能体处理有明确通过/失败标准的限定性任务、样板代码、迁移和测试脚手架。你自己保留:架构设计、决定不做什么、带着全系统上下文进行审查,以及能产出好系统的品味。
智能体擅长任何具备 tight evaluation function 的工作——即能衡量自身工作的场景。它们在样板代码、迁移、测试脚手架和探索多种方法方面 truly great。
你自己保留:架构与 API 设计(智能体见过太多糟糕架构,会 happily cargo-cult enterprise 模式到你 startup);决定不做什么(说“不”是智能体不具备的功能);以及带着全系统上下文审查智能体输出(智能体永远只有局部视角)。
少做 feature,但要做对的。代码生成速度是 siren song。减速 enough 以保持理解。因为如果你失去了对自己系统的理解,你就失去了修复、扩展,甚至知道何时 broken 的能力。
你的 spec 就是杠杆
当你并行调度五十个智能体时,模糊思维不只是拖慢你,而是成倍放大错误。 ambiguous requirements 在数十个并行运行中传播,每个都 slightly wrong in a slightly different direction。 strong engineers 从智能体获得的 leverage 更多,而不是更少。
mediocre 输出与 exceptional 输出的区别几乎 entirely 取决于你的 spec 质量。 vague spec 会让整个舰队放大错误。 precise spec——包含清晰架构、集成边界、边缘情况和不变量——会 everywhere 放大为 precise implementations。
这个spec不再是 prompt 了。spec 是 explicit 的产品思考。这就是为什么 strong software engineers 能从这些工具获得更多 leverage,而 weak ones 不能。机械性的打字工作正在被自动化,认知性的系统理解工作则被放大到一整支 autonomous workers 舰队。
工厂模型
你现在不只是写代码,而是在 build the factory that builds your software。这个工厂有一条生产线:Plan → Spawn → Monitor → Verify → Integrate → Retro。
工厂有质量控制。工厂有流程文档。工厂有 inputs that need to be precisely specified or outputs come out wrong。工厂在不可靠环境中 stalled。所有这些属性都直接映射到 agentic software development。
六步生产线:
- Plan:编写带验收标准的 specs。你的 spec 就是杠杆。
- Spawn:组建团队并分配智能体。
- Monitor:每 5-10 分钟 watch progress 并 resolve blockers。别 hovering。
- Verify:运行测试、审查代码。验证是 bottleneck,不是 generation。
- Integrate:合并分支、解决冲突。
- Retro:用新 pattern 更新 AGENTS.md。复合学习。
运行工厂的实际建议:
- 设置 WIP limits:别 run more agents than you can meaningfully review。3-5 是 sweet spot。
- 定义 kill criteria:若智能体在同一错误上卡住 3 次以上迭代,stop and reassign。
- Async check-ins:每 5-10 分钟 check progress。让智能体 autonomous 工作。
- One file, one owner:绝不让两个智能体编辑同一文件。冲突会 kill velocity。
更多关于此框架的内容,请参见《Factory Model》。
今日起可实践的五大模式
若要从本次演讲带走五点内容:
- 子智能体用于分解。使用 Task 工具创建 focused child agents,明确 brief 和文件所有权。零 setup。今天就开始。
- 智能体团队用于并行。启用
CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1。创建 lead + 3 teammates。用共享任务列表协调。 - Git worktrees 用于隔离。每个智能体独占一个 worktree。无合并冲突,clean integration。像 Conductor 这样的工具已自动处理。
- 质量保障建立信任。高风险变更需计划审批。添加在任务完成时运行测试的钩子。不信任智能体输出,除非经过验证。
- AGENTS.md 实现复合学习。记录模式、陷阱和风格偏好。每个会话读取它,每次会话更新它。知识 compounding。
今天从模式一开始。下周升级到智能体团队。然后叠加质量保障和复合学习。