内容
我与他人共同撰写了一篇关于 AI 如何改变软件生命周期的 Google 白皮书。我不打算把整篇内容概括一遍。相反,这里列出我认为真正重要的几个观点,外加六张图,你可以随意复用。
Google 本周发布了 《带着氛围编码的新 SDLC》。这篇白皮书由我与 Shubham Saboo 和 Sokratis Kartakis 共同撰写,也是一个简短系列中的第一篇。
这是 Day 1 级别的论文,所以前几页讲的都是基础内容:什么是智能体,什么是“氛围编码”,为什么这份工作正在从写代码转向评判代码。如果你读这个博客,应该已经都懂了。我就跳过这些,只写我认为值得花时间看的部分,并摘出其中六张图。你可以在任何地方复用这些图。
智能体就是模型加上支架
这是论文里一个我一直反复回想的表述:智能体就是模型加上支架。
模型只是其中一个输入。其余的一切都是支架:指令和规则文件、工具和 MCP 服务器、运行它的沙箱、负责生成子智能体并在模型之间路由的编排逻辑、在固定节点运行确定性代码的钩子,以及告诉你它何时偏离的可观测性。论文给出的粗略划分是 10% 模型、90% 支架。除非你花一周时间调试过一个智能体,否则这听起来可能有点夸张。
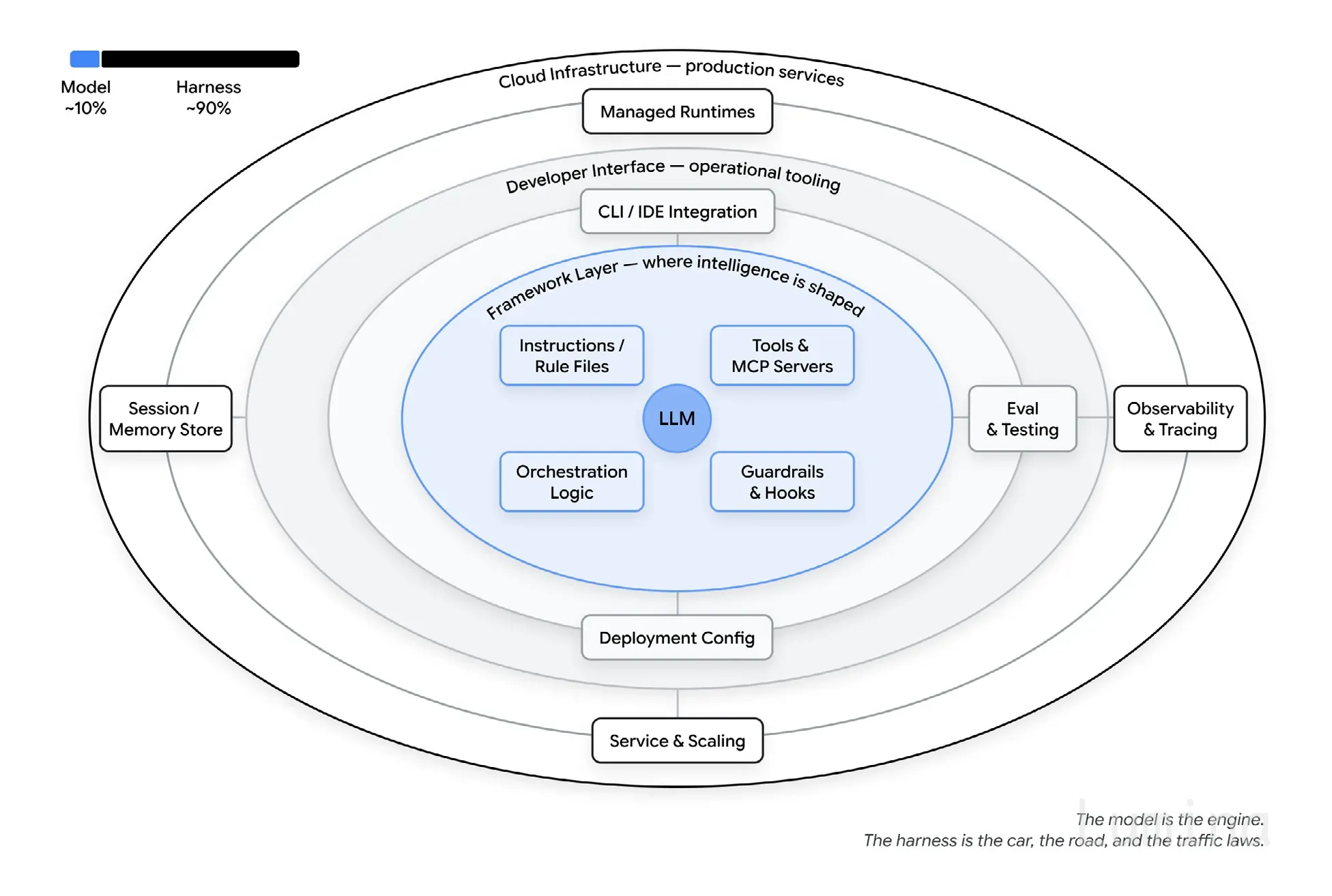 模型是引擎,支架则是汽车、公路和交通规则。
模型是引擎,支架则是汽车、公路和交通规则。
一些公开数据把这件事说得更具体。在 Terminal Bench 2.0 上,某个团队只改支架、不换底层模型,就把一个编码智能体从前 30 名之外提升到了前 5 名。LangChain 的另一项实验,则在固定模型不变的前提下,仅通过改系统提示词、工具和中间件,就在同一基准上提升了 13.7 分。两者都没有动模型本身。
所以,当智能体做出蠢事时,我学会先调试支架。通常问题出在:缺少某个工具、我写的规则太宽、忘了加某个护栏,或者上下文窗口里塞满了垃圾。大多数智能体故障,其实都是配置故障。对我来说,这反而令人振奋,因为配置是我今天就能修好的部分,不必等更好的模型。模型迟早也会被支架下方的部件替换掉。关于这一点,我已经写过更长的文章:支架工程 和 工厂模型。
上下文工程决定你的账单
如果说支架是整个系统,那么上下文工程就是里面最重要的调节旋钮。论文把智能体上下文分成六类:指令、知识、记忆、示例、工具和护栏。真正关键、也最直接体现在账单上的决策,是哪些内容放进静态上下文,哪些放进动态上下文。
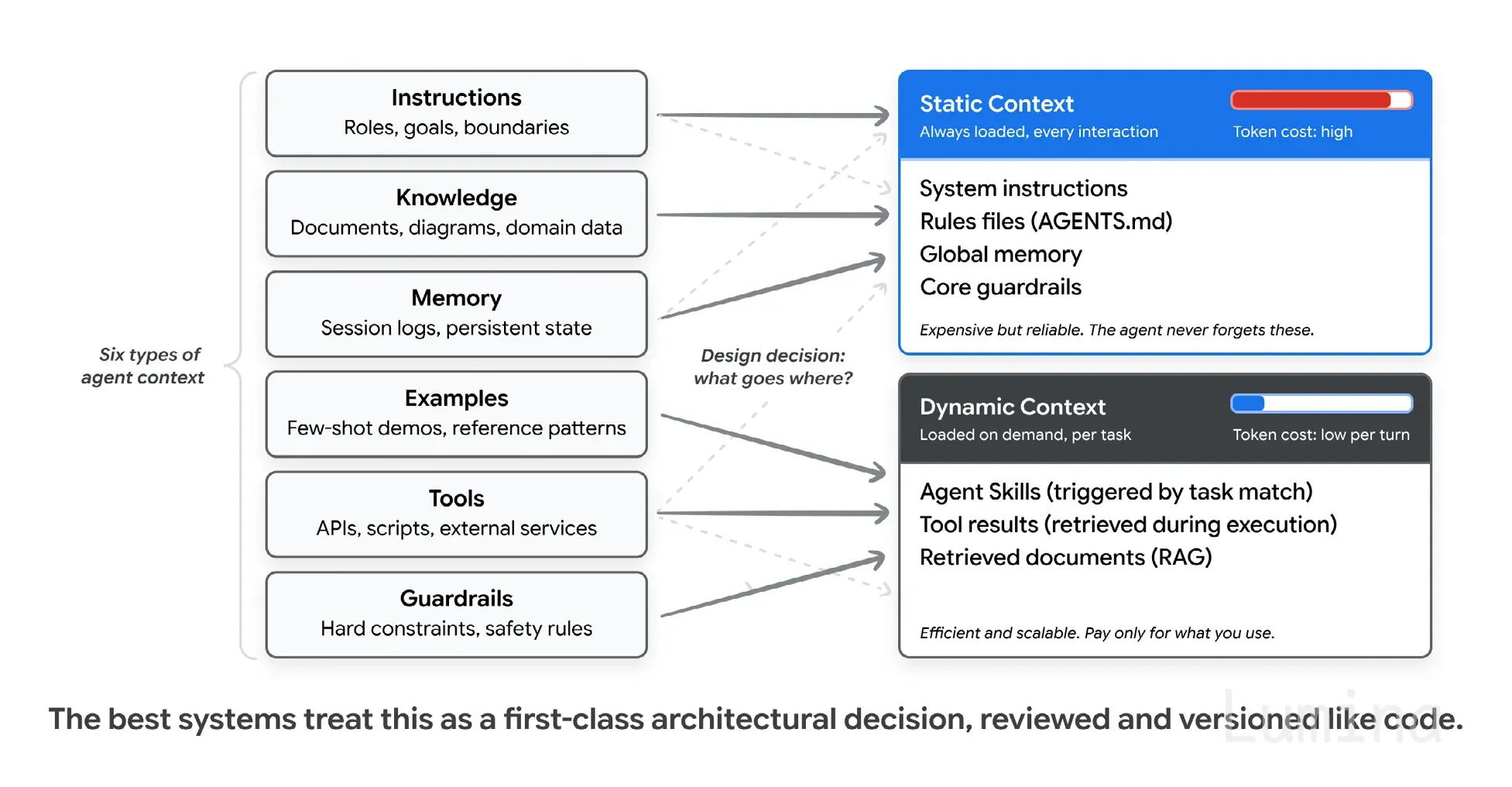 静态上下文每轮都会加载,因此更可靠,也更昂贵。动态上下文按需加载,所以你只需为任务真正需要的部分付费。
静态上下文每轮都会加载,因此更可靠,也更昂贵。动态上下文按需加载,所以你只需为任务真正需要的部分付费。
静态上下文每轮都会加载:系统指令、规则文件(AGENTS.md、CLAUDE.md、GEMINI.md)、全局记忆、核心护栏。它可靠,但也昂贵,因为每次调用都要为此付费。动态上下文则按需加载:任务匹配时触发的技能、工具结果、从 RAG 中拉取的文档。你只为某个任务实际用到的部分付费。
这个平衡一旦偏向任一侧,要么会浪费 token 并淹没信号,要么会让智能体忘掉那些保证安全的规则。论文给出的建议我很认同:把这条边界当作真正的架构决策来处理,在拉取请求里审查,像代码一样版本化。
让动态上下文能够规模化的技巧,是带有渐进式披露的智能体技能。智能体启动时先看到少量元数据,任务匹配后再加载完整指令,只有在真正需要时才拉入厚重的参考材料。这就是一个智能体能携带几十个技能、却只为当前使用的那一个付费的原因。
验证才是氛围编码与工程化之间的分界线
同一个智能体,你可以把它放在从氛围编码到智能体工程化的任何位置。决定最终落点的,是验证。
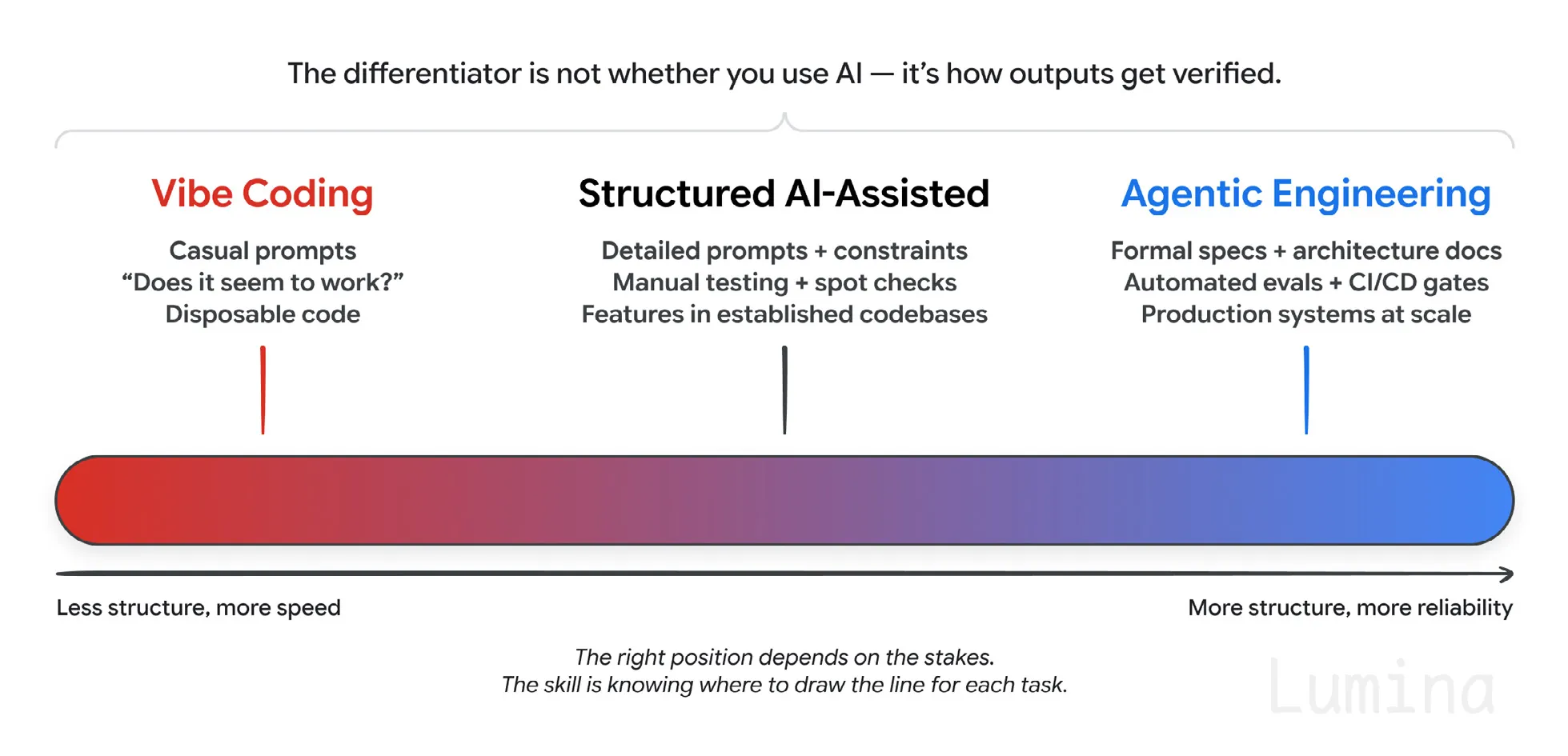 这个光谱上的合适位置取决于风险大小。关键能力在于知道每项任务该把线画在哪里。
这个光谱上的合适位置取决于风险大小。关键能力在于知道每项任务该把线画在哪里。
这里有两种机制。测试覆盖的是确定性部分:这个输入,对应那个输出。评估覆盖的是不确定性部分,论文对它们的拆分方式我觉得很有用。输出评估关注最终结果是否正确。轨迹评估关注它抵达结果的路径,即工具调用和推理过程,是否合理。两者都需要。一个看起来正确、但跳过了检查的答案,比一个明显坏掉的答案更危险。
如果让我从论文里挑一句给管理者,我会选这句:把门槛设在评估上,而不是演示上。演示只能说明智能体能成功一次。带有真实评分标准的评估套件,才能说明它稳定可靠。我一直在强调这一点,参见 智能体代码审查。
各阶段到底发生了什么变化
AI 压缩了软件生命周期,但压缩得并不均匀,而这种不均匀才是全部故事。实施阶段从几周缩短到几小时。需求、架构和验证仍然很慢,因为它们属于判断工作。所以,规格质量成了瓶颈,而验证则移到了中间位置。
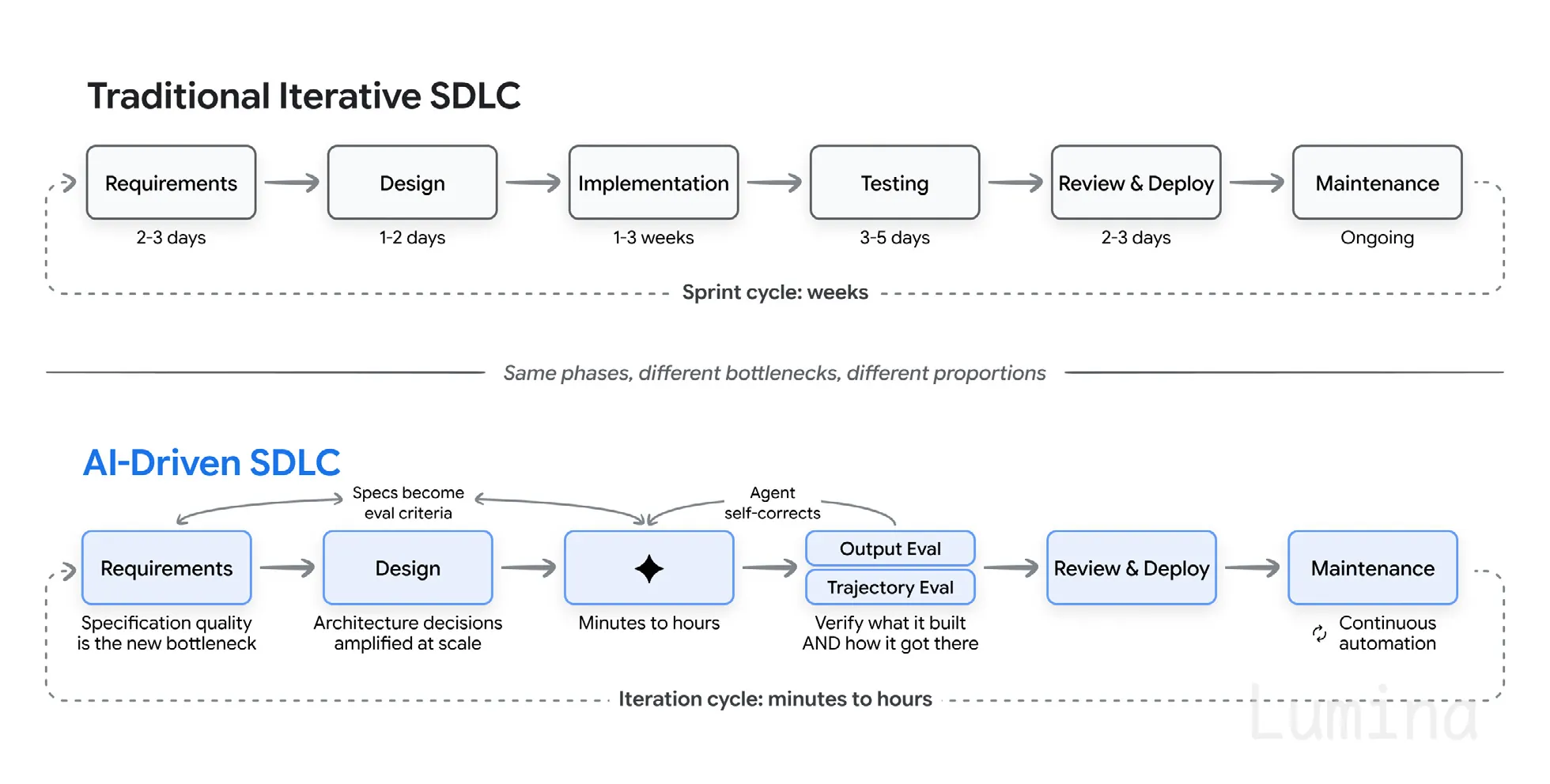 阶段还是那些阶段,但瓶颈变了,比例也变了。
阶段还是那些阶段,但瓶颈变了,比例也变了。
逐阶段来看:
- 需求 不再是你在团队之间传来传去的一份文档。它变成了一场对话,能同时产出规格和初版原型。智能体会根据简短描述起草用户故事、暴露边界情况,并在几分钟内把描述变成可运行的东西。
- 架构 仍然是最顽固的人类阶段。比如一致性与可用性之间的权衡,取决于模型无法完整看见的业务上下文。开发者的任务变成做出并记录结构性决策,再让智能体去实现。
- 实施 是收益和限制都最集中的地方。调查显示生产力提升在 25% 到 39% 之间。METR 的一项研究发现,把检查和修复时间算进去后,有经验的开发者在某些任务上反而慢了 19%。这两种说法都成立。坦白说,AI 让实施从“编写”变成了“审查”。
- 测试与 QA 的逻辑被翻转了。测试和评估成了你告诉智能体“什么叫正确”的主要方式,并被接入一个循环:在基准上运行、聚类失败案例、修正导致问题的提示词或工具、用回归测试集检查、在生产环境中监控新问题。
- 维护 是我认为最被低估的一环。过去那些因为只有原作者才懂、所以“风险太高不敢动”的代码,现在可以由智能体来阅读、重构和现代化。那些因为太琐碎、太冒险而一直没做的迁移和弃用清理,也开始变得可行。
这一切的上限仍然是 80% 问题:智能体能很快完成某个功能的前 80%,而最后 20%,也就是边界情况和系统之间的缝隙,仍然需要模型通常不具备的上下文。
经济性:上下文和路由是财务杠杆
对管理者来说,真正重要的数字不是速度,而是总拥有成本。AI 时代把这件事拆成了两层,从而颠覆了我们对哪种方案更便宜的通常直觉。
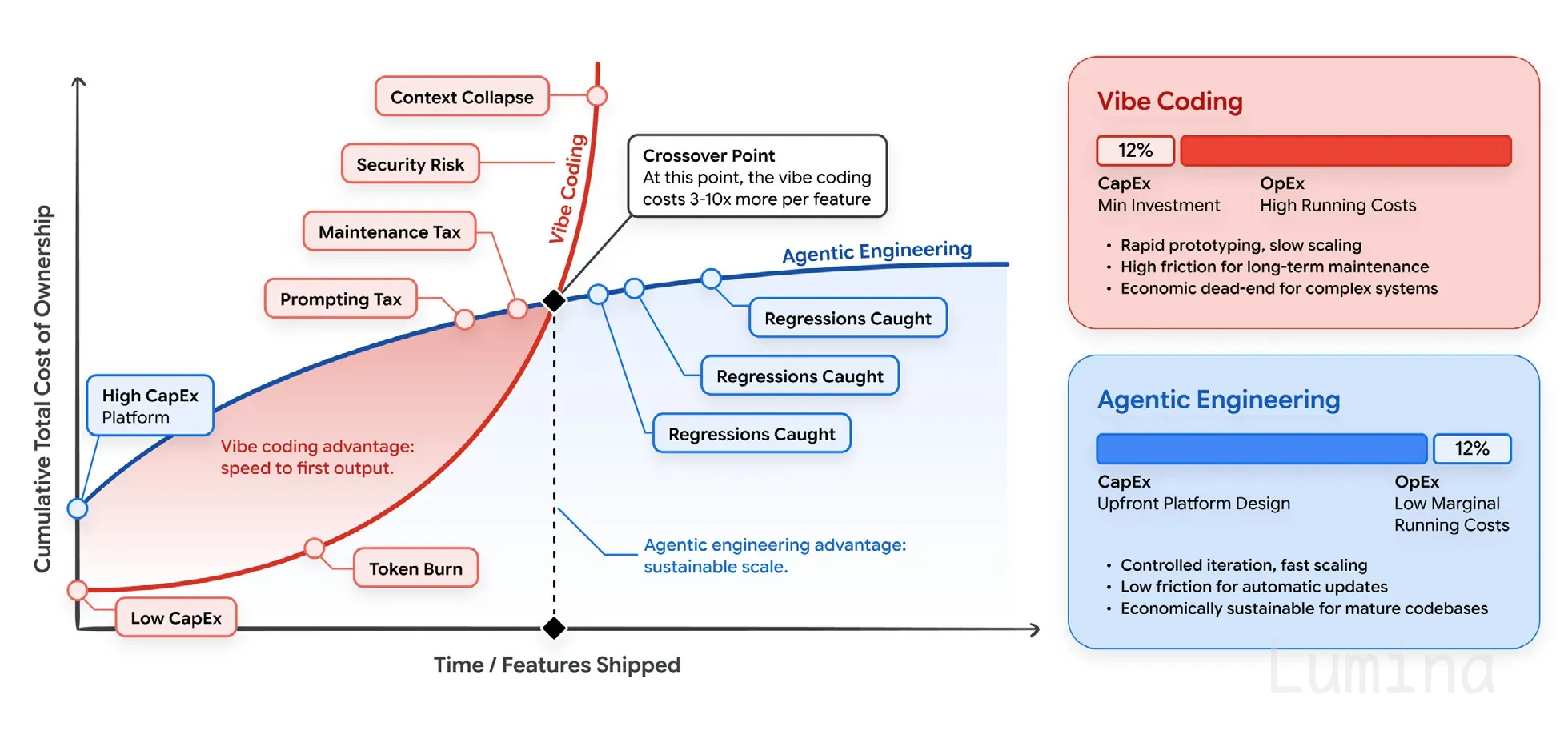 过了交叉点之后,氛围编码每个功能的成本会高出 3 到 10 倍。代码必须活多久,决定了你会不会走到那一步。
过了交叉点之后,氛围编码每个功能的成本会高出 3 到 10 倍。代码必须活多久,决定了你会不会走到那一步。
氛围编码前期便宜,后期昂贵。启动几乎不用花什么钱:订阅费加上一些提示词。然后账单在后面慢慢冒出来。因为把无结构的文件一股脑扔给模型,要求它修自己的错误,会消耗大量 token。还有维护税:几个月后得有人把这些临时拼出来的代码逆向理解一遍。还有安全清理:因为快速生成漏洞的速度,几乎和生成功能一样快。智能体工程化则相反:前期投入更多(模式、测试、结构化上下文),但每个功能的后续成本更低。
“氛围编码每个功能贵 3 到 10 倍”的交叉点只是说明性的,不是实测常数。我希望开发者真正带走的是:上下文工程和模型路由是财务杠杆,不只是技术杠杆。你不能每次提示都把一个 10 万 token 的仓库直接塞进去,还指望它能规模化。把高难度推理路由给大模型,把常规工作、测试生成、代码审查、CI 检查交给便宜的小模型。质量能保持,账单还能降下来。这就是我所说的 编排税 的金钱侧面。
原型正在变成生产级智能体
这是我最关注的论文部分。过去那种在终端里一闪而过、生成个临时脚本的工作流,现在已经可以在同一个地方产出生产级智能体,而且往往就是和你已经在用的编码智能体对话完成的。
构建、评估并部署一个真正的智能体——带有持久记忆、作用域权限、评估覆盖和可观测性——过去是另一套技术栈,也是另一份工作。现在它被收进了你本来就在跑的循环里。Google 的 Agents CLI 就是围绕这个设计的。完成一次性安装后,你的编码智能体就能获得整个生命周期所需的技能,而你只需要用自然语言驱动它:
# 一次性设置
uvx google-agents-cli setup
# 然后,在你的编码智能体中:
> 构建一个支持智能体,让它根据我们的文档回答问题。
> 在 FAQ 数据集上评估它。
> 将它部署到 Agent Engine。
在这条指令背后,它会搭建项目、编写代码、生成评估集、运行评估、部署到托管运行时,并给出结果。昨天还在你笔记本上的原型,今天就能变成对用户提供服务的生产级智能体,而且无需重写。智能体之间的协作则建立在开放标准之上:MCP 用于工具,A2A 用于把工作交给其他智能体。
论文里有一个实验,我一直会跟人提起。Anthropic 的一个团队在两周内让一组智能体用 Rust 构建出了一个可工作的 C 编译器,人类负责定方向和审查,而不是亲自写代码。大致上,这就是未来将要走向的形态。
在日常工作中,你会在论文所说的两种模式之间切换:指挥者 和 编排者。指挥者是实时的、发生在 IDE 里的,按键级别地运行,适合探索,也适合处理你还不熟悉的代码。编排者是异步的:你把一个目标交给一个或多个智能体,再审查它们返回的结果,适合规格明确的工作,比如迁移或生成测试。现在工具已经两种都能做了,有时甚至在同一个小时里都能切换。我认为,从指挥者到编排者的转变,首先是 技能转变,其次才是工具转变。
给其他人的那张图
再看一张图,这张不是给你看的。它是给你想带着一起前进的人看的:那个还以为这只是花哨自动补全的高管,那个还没跨过这一步的同事。
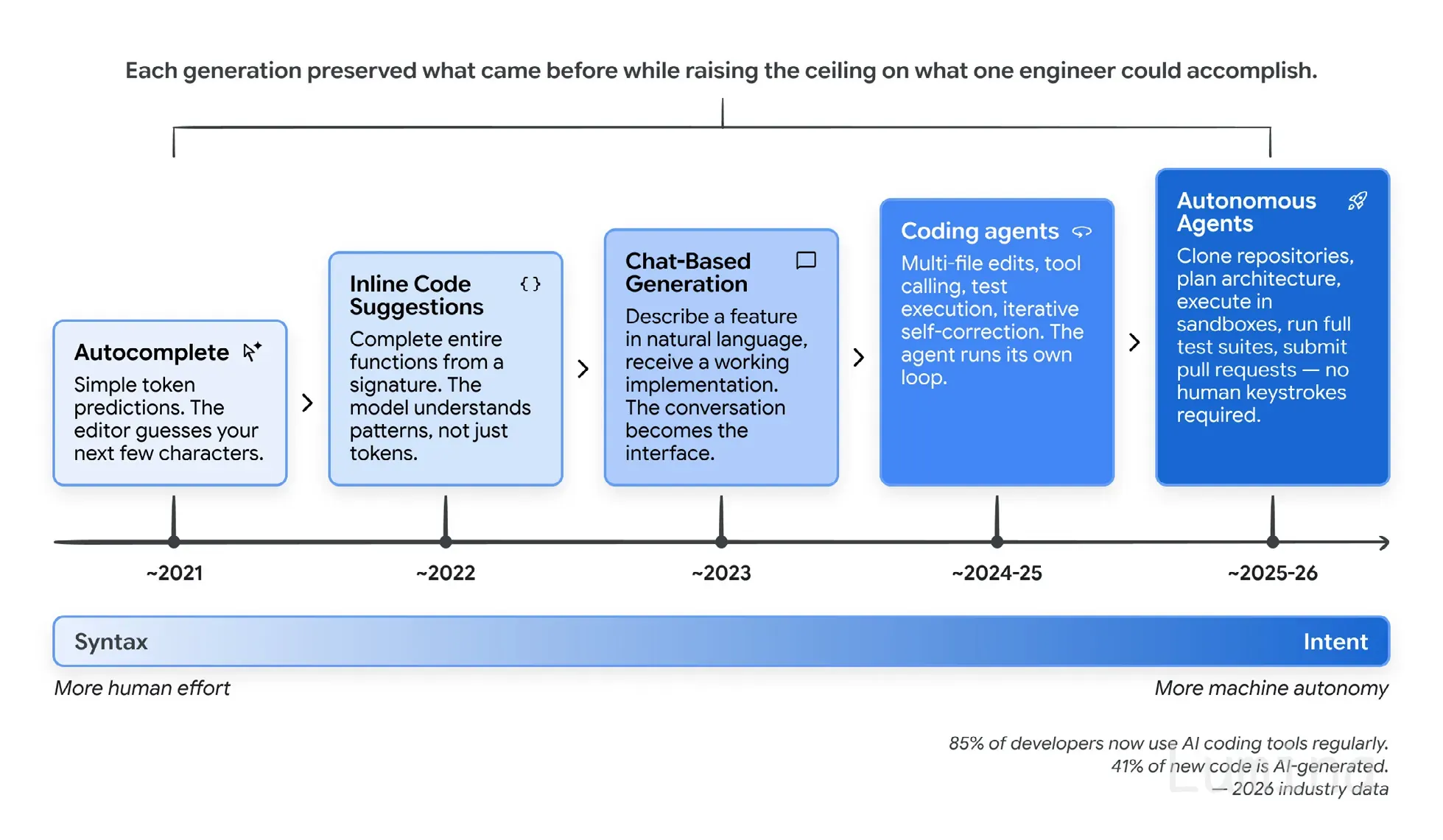 每一代都保留了前一代的能力,并抬高了单个工程师能做的上限。
每一代都保留了前一代的能力,并抬高了单个工程师能做的上限。
这张图里有那些通常会终结“这玩意儿到底是不是真的”争论的采用数据。截至 2026 年初,85% 的职业开发者会 नियमित 使用 AI 编码智能体,51% 每天使用,大约 41% 的新代码由 AI 生成。
从哪里开始
论文最后还给了个人、管理者和组织一整套更长的建议。我这里就不重复了。
如果只能从中带走一句话,那就是:AI 会放大它落入的工程文化,不管好坏。生成能力现在大体已经解决了。剩下要做的工作,是规格和验证,以及把它们连接起来的系统。我会优先把这部分练好。