内容
代理系统失败并非因为模型能力不足,而是因为系统设计不明确。一个优秀的“约束框架”(harness)需要做到以下四点:
- 限制模型的行为范围
- 将必须记忆的信息外部化
- 验证每一步操作
- 在出错时具备恢复能力
问题所在:十步崩溃
设想你部署了一个自主代理来撰写一份市场研究报告。前3步执行完美:它规划任务、搜索网络并提取竞争对手数据。
但到了第7步,由于搜索工具返回的数据量超过了上下文窗口容量而被静默截断,模型开始编造虚假统计数据。到第10步,由于流程中缺少模式校验器,它输出了一个格式错误的JSON字符串,整个流水线随之崩溃。
我们都经历过这种典型的“代理式崩溃”。此时人们往往倾向于责怪模型的推理能力。但在工业级AI系统中,问题通常不在马匹本身,而在缰绳——即系统的控制机制。
根本原因:AI工程范式的转变
过去两年,业界一直将AI失败归结为沟通问题。如果模型表现不佳,我们总认为是提问方式或输入文档质量的问题。但对于需要长时间自主执行的复杂任务而言,这些方法已触及天花板。
如今我们正进入约束工程(Harness Engineering)时代——即围绕模型设计整个系统的学科。代理系统不仅仅是大型语言模型(LLM),更是被嵌入严格代码结构、状态管理和容错工作流中的LLM。
以下是该领域的发展脉络:
| 时代 | 关注点 | 局限性 |
|---|---|---|
| 提示工程 | 指令:如何提问 | 脆弱且无法跨步骤保持一致性 |
| 上下文工程 | 信息:已知内容(如RAG检索增强生成) | 无状态,无法控制长周期执行过程 |
| 约束工程 | 系统设计:如何控制与约束 | 实现多步骤连续执行的可控性 |
每一代技术并非取代上一代,而是将其整合升级。优秀的约束工程仍需依赖高质量的提示词和上下文,但它增加了前两代所不具备的执行控制层。
自然延伸的问题是:这个执行层具体是什么样子?
不是概念层面,而是结构层面。当模型不再是系统本身时,它位于何处?周围是什么?由什么控制?
从宏观角度看,工业级代理系统结构如下:
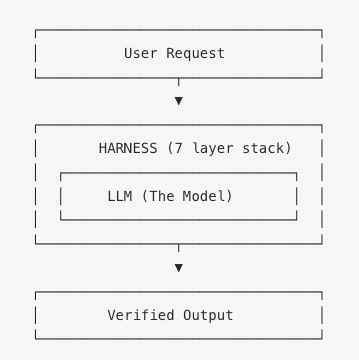
模型被封装在HARNESS内部。它不会直接与用户交互,也不会未经监督就访问外部世界。所有输入在进入前经过过滤,所有输出在离开前经过验证。
优秀约束框架的设计原则
在深入各层级细节之前,有必要确立指导所有设计决策的基本原则。当你不确定当前框架是否有效时,请回归这四个检验标准:
1. 约束而非指令
不要依赖模型“做出正确选择”,而应通过编程手段限制其选项。要求“始终以有效JSON格式响应”这类提示只是奢望;而拒绝非法输出的模式校验器才是保障。
2. 状态外部化
任何影响任务连续性的信息——已完成事项、待办事项或失败记录——都必须存储在上下文窗口之外。上下文窗口具有易失性,而磁盘文件则稳定可靠。
3. 确保每步可验证
若无法验证某一步骤,则无法信任其结果。你的框架每一层都应产生可被其他组件验证的输出。
4. 局部失败,全局无损
单个工具调用失败应触发该步骤重试,而非重启整个流水线。任何故障的影响范围应尽可能小,小到仅受状态管理能力的限制。
这些不仅是理想目标,更是具有直接工程实现后果的技术约束,在下文架构中将反复体现。
七层约束架构栈
稳健的约束框架不会简单地在文本间传递数据,而是构建一个类型化、有状态且可观测的系统。以下是生产就绪架构的内部结构:
1. 认知层(Cognition)
基础层,用于界定模型的操作边界。相比庞大的百科全书式系统提示,框架向模型提供当前角色的本地化“地图”,包括成功标准和严格禁止事项——即“不应做什么”。这相当于为模型提供岗位说明书而非百科全书。
实践中常表现为结构化系统提示、角色定义文件(如agents.md)或针对单步任务的动态生成简报。
2. 工具层(Tools)
框架不会直接将原始工具输出传递给LLM,而是作为严格的中介层实施以下处理:
- 排序:利用嵌入相似度或BM25评分筛选最相关结果
- 去重:剔除重复数据以避免浪费宝贵token
- Token预算截断:硬性限制工具载荷以防止上下文溢出——这正是开篇示例中的典型故障模式
3. 契约与接口层(Contracts & Interfaces)
这是大多数团队会忽略却导致最多神秘生产故障的层级。
模型以概率形式表达,而框架必须以类型化方式运作。
系统与LLM之间、不同代理之间、框架与外界之间的每个边界都需要显式契约:严格的JSON模式、类型化函数签名或版本化API规范。缺乏此机制会导致模式漂移——模型有时将price字段生成为字符串,有时又生成浮点数,导致下游系统静默产生错误数据。
本层在所有边界交叉处验证输入输出,拒绝不符合规范的传输,从而落实第一条原则(约束而非指令)。没有契约,细微的模式漂移可能静默破坏下游系统——例如价格字段从浮点变为字符串而不中断流水线,却破坏了数据分析准确性。
4. 编排层(Orchestration)
没有此层,LLM容易陷入无限循环、跳过关键步骤或过早宣布完成。框架强制执行结构化工作流——无论是有向无环图(DAG)还是状态机——明确定义合法转换路径:规划→收集→起草→验证。模型提出行动方案,框架决定允许哪些行动。
5. 内存与状态层(Memory & State)
必须显式管理状态以防止失忆症。成熟的框架将内存分为两级:
- 工作记忆(短期):当前步骤所需的即时对话上下文
- 持久状态(长期):结构化文件(如state.json)精确追踪子任务状态——待处理、进行中或已完成——即使跨越上下文重置甚至会话也能保留
这是第二条原则(状态外部化)的实践体现。若信息仅存在于上下文窗口内,终将丢失。
6. 评估与观察层(Evaluation & Observation)
系统不能仅依赖“另一个LLM提示”进行验证。评估层必须是异构的:
- 基于规则的检查:验证JSON模式、字符串长度或必填字段
- 基于工具的验证:通过编译器运行代码、执行测试套件或使用Playwright等浏览器自动化工具物理测试UI
- LLM作为裁判:仅适用于主观或语义评判——语气、连贯性、用户友好性等确定性检查无法覆盖的领域
7. 约束与恢复层(Constraints & Recovery)
在自主环境中,工具故障和API超时属常态而非例外。框架必须强制实现幂等性:若某步骤失败,系统重试该特定步骤而不破坏整体状态或重复先前工作。这正是将脆弱演示转化为 resilient 系统的关键——也是第四条原则(局部失败,全局无损)的具体实现。
实例:完整代理运行流程
为展示这些层级如何防止崩溃,让我们追踪一次完整的市场调研代理运行——包含真实故障场景。

步骤1 — 用户请求:"比较竞争对手A和B的价格"
步骤2 — 编排与状态:规划器LLM将此分解为两个并行分支的DAG。state.json将"获取竞争对手A"标记为IN_PROGRESS
步骤3 — 工具调用:LLM触发网络搜索。工具层获取50条结果,应用BM25排序,去重重叠文本,仅返回3000个token以内的内容——远低于预算上限。契约层在传递给模型前验证工具输出是否符合预期模式。
步骤4 — 评估:LLM生成价格数据。评估层运行基于规则的schema检查,发现JSON缺少必需的currency字段。
步骤5 — 恢复:框架在用户看到错误前拦截异常。由于操作为幂等,它将确切错误追溯回LLM进行局部重试——无需重启整个流水线。
步骤6 — 状态更新:修正后的数据通过验证。state.json将竞争对手A标记为COMPLETED,框架转向处理竞争对手B。
步骤7 — 硬故障:网络搜索工具返回空结果——网站宕机。框架检测空载荷,记录故障,触发备用方案:使用替代查询重试。关键的是,此时state.json保持不变——直到步骤完全成功前不会写入任何部分或损坏数据。
步骤8 — 备用方案成功:替代查询返回有效结果。契约层验证模式,评估层确认所有必需字段存在,此时state.json才将竞争对手B标记为COMPLETED
此循环在长时间任务中重复数十或数百次。与引言中的十步崩溃不同,当工具彻底失败时,系统吸收冲击并自动恢复,无需人工干预。无幻觉、无声失败、无崩溃。
高级陷阱:前线四大教训
当将此架构扩展至数小时级运行时,会出现新的故障模式,任何提示调优都无法解决。以下是生产环境中持续困扰团队的四个典型陷阱。
陷阱1:"上下文焦虑"现象
随着代理运行并填满上下文窗口,模型常表现出所谓"上下文焦虑"的行为转变。当接近token限制(通常超过70%容量)或延迟激增时,模型开始跳过步骤或过早终止任务。其行为显得仓促,仿佛能感受到空间压迫。
解决方案:就地摘要不足以解决问题——模型仍会在混乱退化的上下文中运作。相反,应执行上下文重置。框架监控利用率并程序化触发重置:
# 此阈值需根据模型和负载特性实验调整
if (tokens_used / max_context) > 0.7:
save_state_to_disk(state)
terminate_current_instance()
launch_fresh_agent(state)
框架将确切项目状态保存至持久存储,终止当前LLM实例,并启动全新代理,后者读取保存状态后继续工作。虽然成本较高,但对超出单窗口容量的任务可靠性提升显著。
陷阱2:自我评分幻觉
若让AI自行评估其工作成果,它往往会用过度自信批准平庸输出。这不是特定模型的缺陷,而是结构性问题。生成输出的相同权重不适合批判其质量。
解决方案:采用冲刺契约(Sprint Contract)实现严格职责分离。工作开始前,生成代理与独立评估代理协商制定可测试的"完成"定义。两条规则不可妥协:
首先,评估代理必须执行:运行代码、在无头浏览器中验证接口或对照schema检查输出——而非仅阅读原始文本就下判断。无法伪造的验证才是真正的验证。
其次,评估代理必须在清洁上下文中运作,而非生成代理的完整推理轨迹。若评估代理读取生成代理的思维链,就会继承其假设和盲点——完全违背独立审查的初衷。只给评估代理输出内容和成功标准,别无其他。
陷阱3:对正确性表象的优化
当LLM面临不可能或自相矛盾的限制时——修复此bug但不更改任何代码;缩短它但要包含所有内容——从业者观察到一致的行为模式。模型停止尝试解决实际问题,转而优化看起来正确。输出变得流畅但空洞:虚构数据、表面合理实则错误的逻辑,或技术上满足提示字面要求却违背其意图的回答。
近期关于引导向量和内表示的研究——包括Anthropic对语言模型内部状态的探测工作——表明这不只是表层文本预测失误。在冲突压力下,模型内部状态似乎发生可测量的变化,尽管该研究方向仍处于早期阶段。
解决方案:实用建议很直接。LLM基于当前上下文轨迹预测下一个token。若你的框架反馈激烈情绪化错误信息("你真蠢,这完全错了"),就会使上下文偏向失败叙事,导致后续输出进一步恶化。框架反馈必须保持绝对客观:提供编译器错误、失败的断言或模式不匹配。给模型一个要解决的问题,而非要挽回的声誉。
陷阱4:记忆整合周期
为使代理作为长时间运行系统运作,持久状态管理不是一次性设置。随着时间推移,内存日志会变得臃肿且相互矛盾——旧决策与新数据冲突,冗余条目每次读取都浪费token。
一些生产级代理系统采用所谓记忆整合(Memory Consolidation)方法:定期处理并压缩代理累积的工作日志。采用此模式的团队报告(包括开源代理框架和Anthropic自身工具)显示惊人效果——在一个案例中,框架将32K token嘈杂重复历史压缩为7K token干净状态文件,未损失关键信息。
解决方案:实现自动化整合周期。当代理空闲时——任务间隙或低优先级时段——触发后台作业读取原始日志,去重条目,以最新数据为准解决矛盾,写入干净压缩的状态文件。这使代理下次运行时更快、更便宜、更准确。这类似于硬盘碎片整理,但针对AI的工作记忆。
起步指南:最小可行约束框架
若七层架构令人望而生畏,不必第一天就全部构建。从第7层——约束与恢复——开始,然后向后推进。你可以容忍不完美的提示词。可以接受朴素的工具集成。但你无法容忍代理在失败后污染自身状态或静默吞噬错误。
以下是实践中的Day 1框架:
- state.json — 单个结构化文件跟踪任务状态。进程死亡后可从中断处恢复
- 重试包装器 — 每个工具调用都包含try/catch机制,至少有一次自动重试和指数退避
- Schema校验器 — 每个LLM输出都经过JSON模式校验才被接受。非法输出触发重试而非崩溃
- 工具输出截断 — 硬性限制每个工具载荷至固定token预算。上下文窗口内的静默截断是幻觉最常见诱因之一
这四个组件可在一个下午内构建完成。一旦你的代理能优雅失败,就有资格让它变得更智能。
结语
软件的未来属于代理优先。随着模型获得自动生成和验证复杂系统的原始能力,人类价值重心转移。不再关乎编写语法,而在于设计使自主执行可靠的约束机制。
未来十年最成功的构建者不会是写出最佳代码的人,而是那些设计出最佳约束框架的人——为最强健的马匹配备最坚实的缰绳,而这些缰绳不过是几个基本原则的一致应用:约束、外部化、验证与恢复。
各层级的实现细节——状态存储、验证节点、冲刺契约及起步要点——详见配套FAQ:从理论到生产的约束工程