16
Cursor 如何索引你的代码库?
技术博客
三元索引代码索引+3
作者: Manthan Gupta
发表时间:
Cursor用语义向量索引与本地稀疏n-gram正则索引协同检索代码:AST切块、自训练嵌入模型、Turbopuffer按代码库命名空间存储,Merkle树只同步变更并提供访问证明,simhash复用团队索引,动态上下文按需读取文件,最终在超大仓库中显著降低首次查询、搜索延迟、成本与Agent token消耗。
浏览作者 Manthan Gupta 的公开文章、摘要与延伸阅读。肖恩子的知识花园
Cursor用语义向量索引与本地稀疏n-gram正则索引协同检索代码:AST切块、自训练嵌入模型、Turbopuffer按代码库命名空间存储,Merkle树只同步变更并提供访问证明,simhash复用团队索引,动态上下文按需读取文件,最终在超大仓库中显著降低首次查询、搜索延迟、成本与Agent token消耗。
 英文
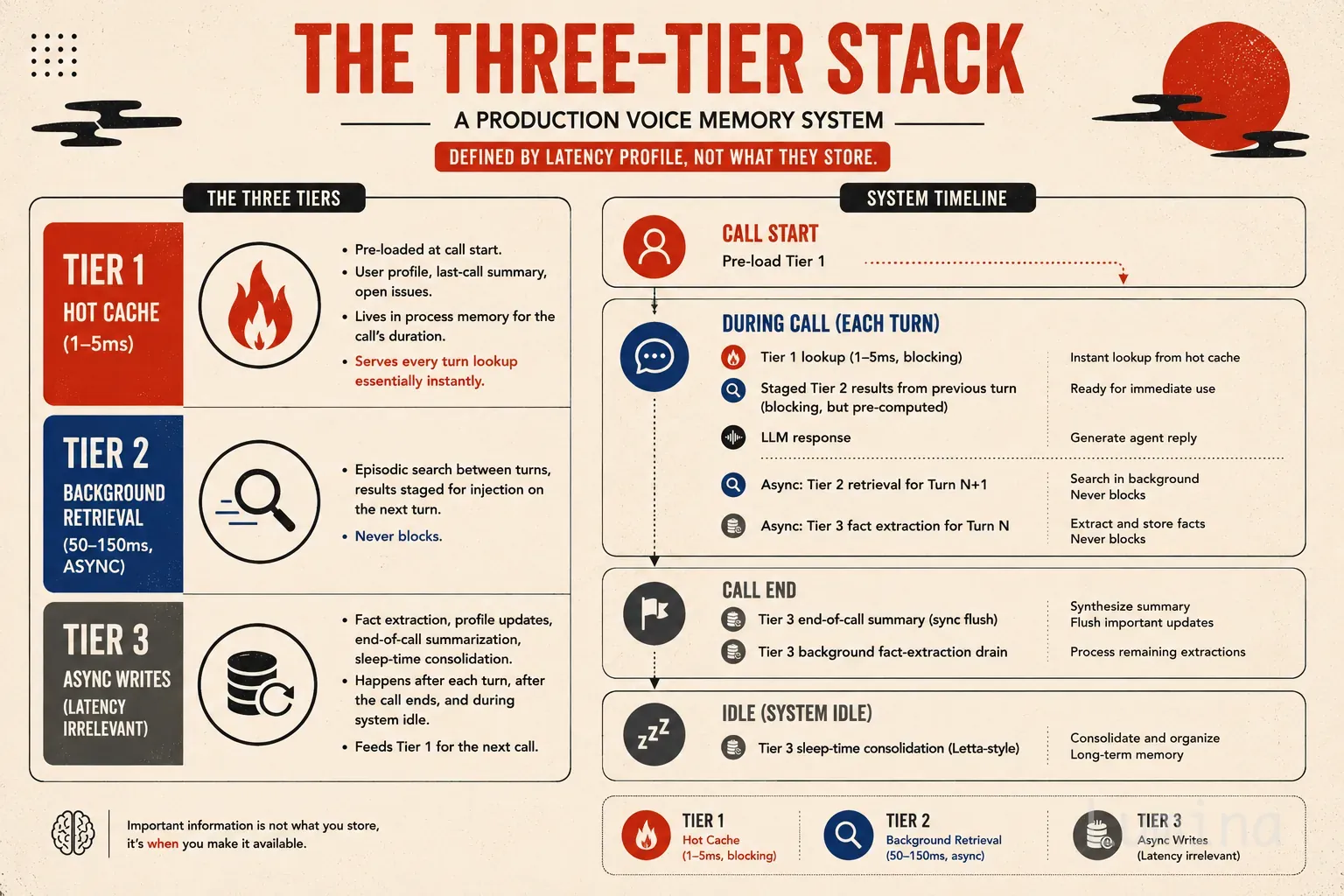
英文语音智能体的记忆不能沿用文本架构,500至800毫秒响应预算下,同步向量检索和实时总结会破坏对话节奏;可行方案是反转读写路径:通话前预加载用户画像、上次摘要和未结事项,通话中只查热缓存,语义检索和事实写入异步执行,通话后总结并在空闲期整合,最终记忆质量取决于预先准备和筛选,而非临场检索能力。
 英文
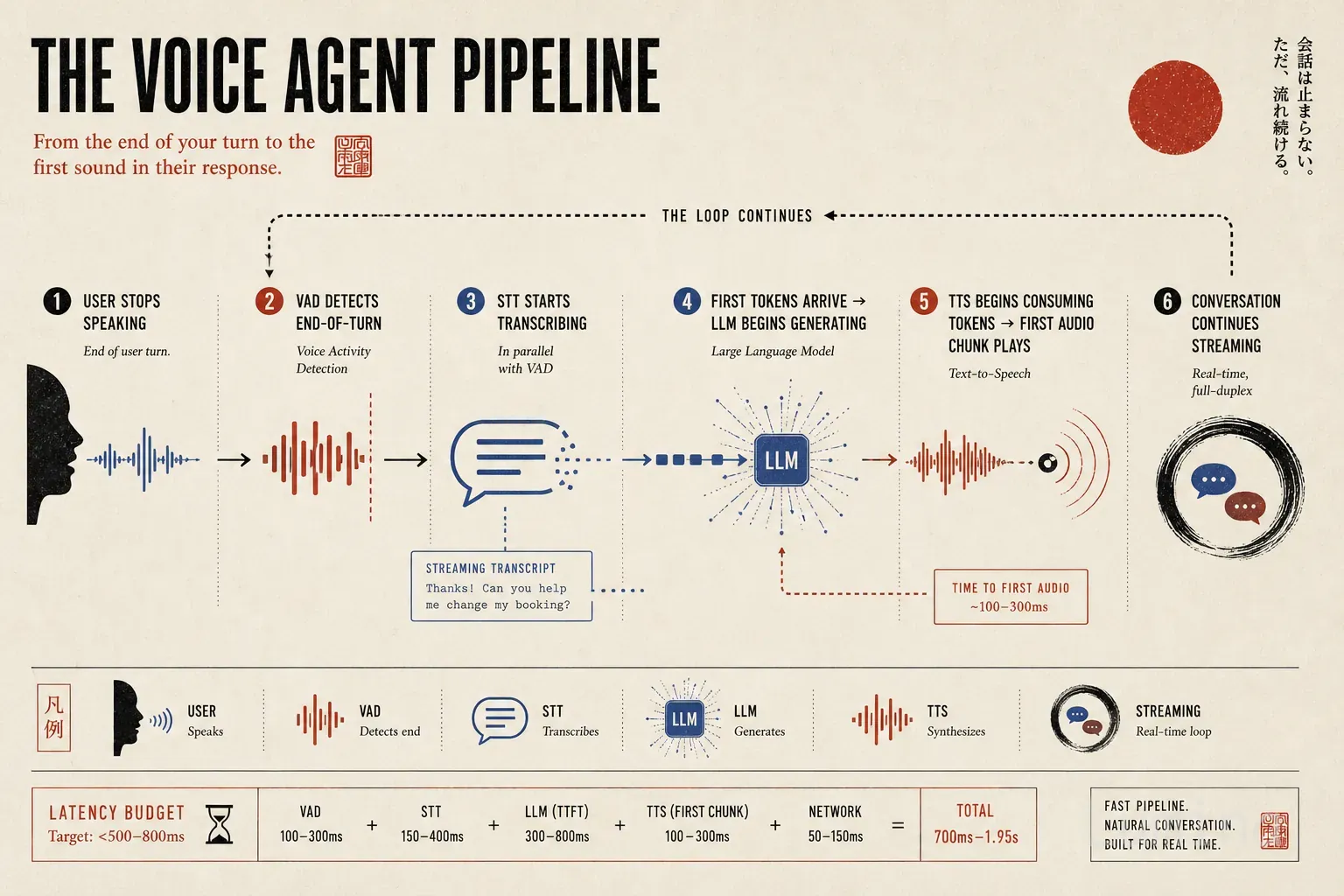
英文语音代理不是给LLM加语音,而是受延迟约束的STT、LLM、TTS流水线;生产主流仍是可观测的级联架构,需用流式、全双工、打断检测和轮次管理把响应压到500至800毫秒内,否则体验会显得机械或失效。
 英文
英文AI产品把记忆当默认卖点,但作者认为它本质是高成本的产品与系统税:常导致答案被旧偏好锚定、上下文膨胀、调试更难,并放大隐私泄露与安全投毒风险。多数场景应先做显式配置、工作流状态和任务级检索,只有长期连续型产品才值得谨慎引入记忆。
Hermes采用四层记忆架构,小型MEMORY.md和USER.md保存稳定高价值事实,SQLite会话库按需检索历史,Skills沉淀可复用流程,Honcho可选扩展深层用户建模;其关键动作是冻结系统提示、把大部分记忆转移到工具检索,并在压缩上下文前先提炼持久信息,结果是在控制成本与缓存稳定性的同时保持连续性与实用性。
Clawdbot是MIT开源本地个人AI助手,集成Discord等并可自动处理邮件日程等任务,核心用Markdown持久记忆配SQLite向量与全文索引,回答前语义加关键词混合检索并在会话压缩前静默写入防丢,多代理记忆隔离,结果是上下文长期可追溯且由用户本机掌控并降低调用成本。