 英文
英文37
重新思考搜索:代码生成
技术博客
代码搜索搜索架构+3
作者: Perplexity
发表时间:
Perplexity推出Search as Code架构,将搜索栈拆成可由模型生成代码调用的SDK原语,并在安全沙箱中完成检索、排序、过滤、并行和聚合,使智能体能为复杂任务动态构建搜索流程;评测显示SaC在五项基准中四项领先,WANDR领先次优系统2.5倍,同时降低成本和上下文噪声,推动搜索从固定接口转向可编程智能体基础设施。
浏览 技术博客 分类下的公开文章、摘要与延伸阅读。肖恩子的知识花园
英文Perplexity推出Search as Code架构,将搜索栈拆成可由模型生成代码调用的SDK原语,并在安全沙箱中完成检索、排序、过滤、并行和聚合,使智能体能为复杂任务动态构建搜索流程;评测显示SaC在五项基准中四项领先,WANDR领先次优系统2.5倍,同时降低成本和上下文噪声,推动搜索从固定接口转向可编程智能体基础设施。
 英文
英文作者从 Claude Code 转向 Cursor 后,认为多模型切换、快速上下文压缩和图形化工作流更适合智能体编程;其开源 pstack 插件,把调试、评审、测试、架构等工程方法固化为技能,强调先提升验证与可信度,再做多智能体并行;内部机器人 Benny 已用这些技能自动分诊、复现、修复并提交 PR。软件自动化的瓶颈不是写代码,而是可验证的端到端信任。
 英文
英文作者用200张来自Wikimedia、Geograph和iNaturalist的图片复测o3地理定位能力,比较普通提示与流行“GeoGuessr神提示”,结果显示神提示未提升表现,反而中位误差更高;o3确有强定位能力,但gpt-5.4、gpt-5.5未继承,结论是模型隐藏能力需用基准验证,不能凭试用和提示叙事判断。
 英文
英文Codex正从代码助手扩展为通用计算机工作执行系统,依托持久线程、语音输入、任务纠偏与排队、浏览器/桌面/MCP连接器、自动化、Goals、侧边栏和共享记忆,持续处理跨代码库、网页、Slack、Gmail、文档等工作流,用户负责设定目标、验证结果和最终决策。
 英文
英文Claude Code在大型代码库落地的关键不在模型本身,而在围绕代码库建立可导航、可维护、可治理的配置体系:用分层CLAUDE.md提供上下文,配合hooks、skills、plugins、LSP、MCP和subagents提升检索、执行与分发效率,并由专人或团队持续维护规则和治理;组织若提前建设基础设施、控制上下文噪音、定期更新配置,采用效果和规模化速度显著提升。
 英文
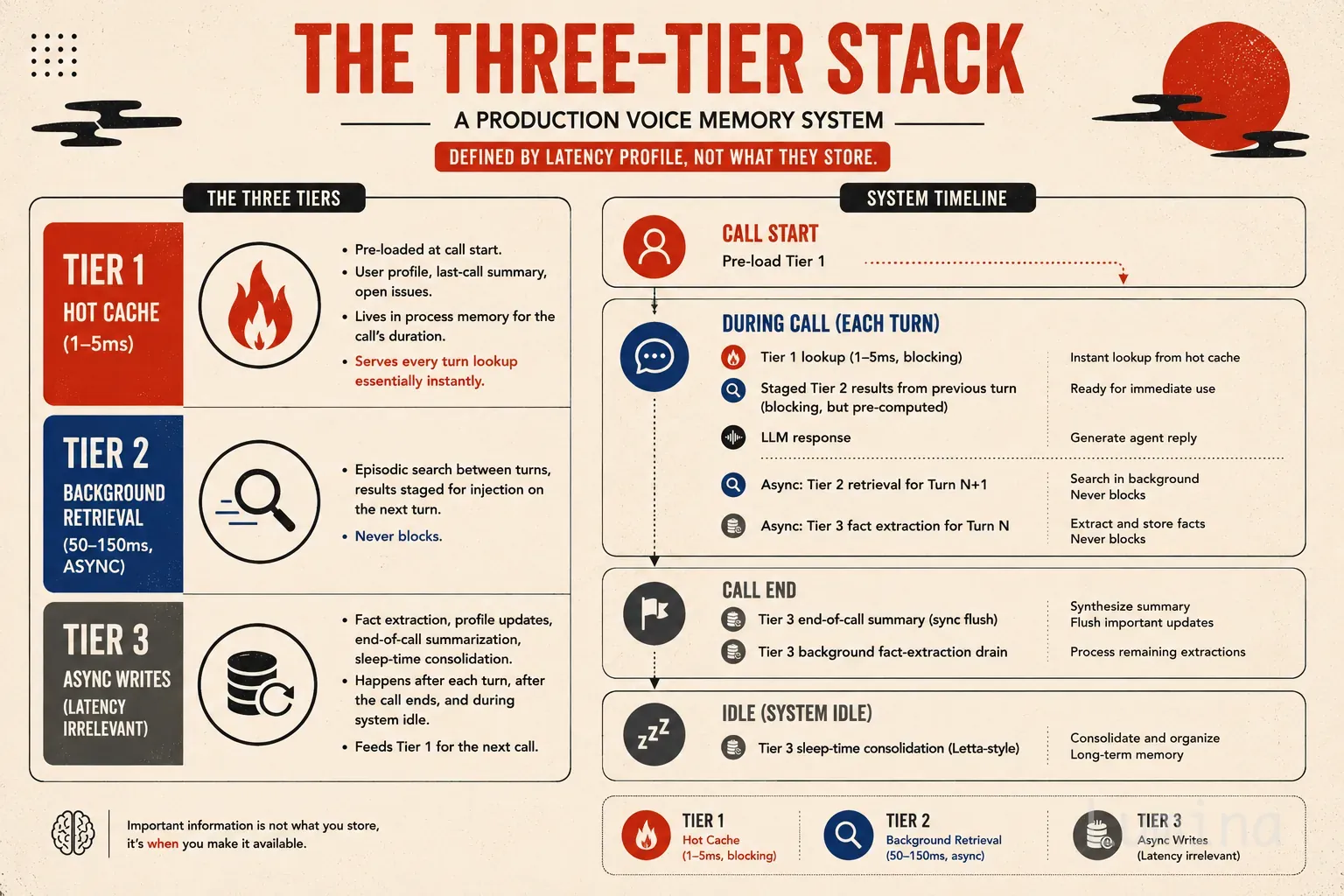
英文语音智能体的记忆不能沿用文本架构,500至800毫秒响应预算下,同步向量检索和实时总结会破坏对话节奏;可行方案是反转读写路径:通话前预加载用户画像、上次摘要和未结事项,通话中只查热缓存,语义检索和事实写入异步执行,通话后总结并在空闲期整合,最终记忆质量取决于预先准备和筛选,而非临场检索能力。
 英文
英文作者主张在 Claude Code 中用 HTML 取代 Markdown 作为主要输出格式,因为 HTML 能承载表格、SVG、交互、布局和可视化,更适合复杂规格、代码审查、设计原型、研究报告和一次性编辑器;代价是生成更慢、版本 diff 更差,但可读性、分享性和参与感更强,能让人更有效审阅并指导 AI 工作。
 英文
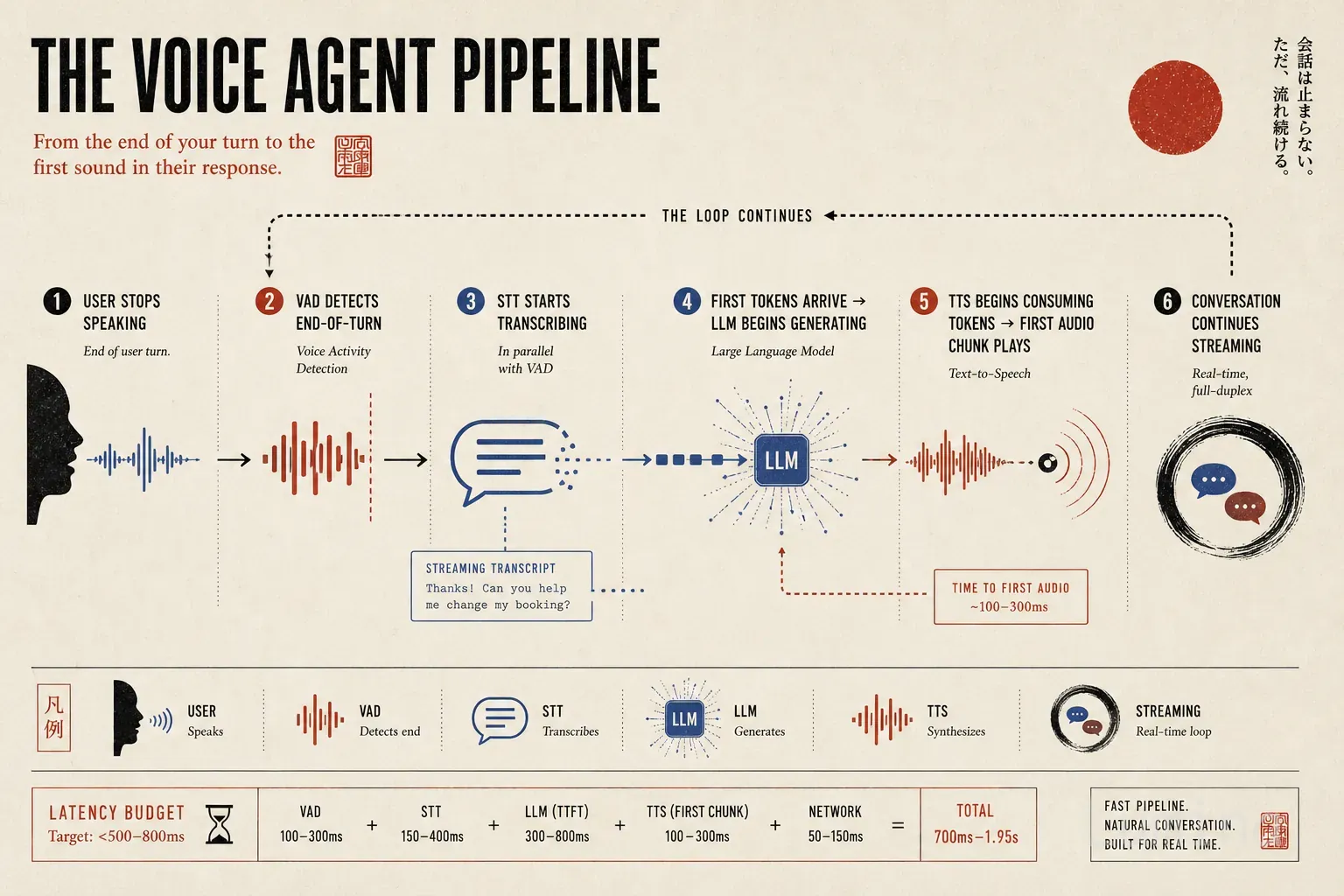
英文语音代理不是给LLM加语音,而是受延迟约束的STT、LLM、TTS流水线;生产主流仍是可观测的级联架构,需用流式、全双工、打断检测和轮次管理把响应压到500至800毫秒内,否则体验会显得机械或失效。

