 英文
英文16
为什么我们要重新思考AI时代的缓存机制
技术博客
AI爬虫CDN缓存+3
作者: Cloudflare
发表时间:
Cloudflare称其网络32%流量来自自动化请求,AI爬虫因高并发、长尾扫描、高唯一URL和低复用率,显著拉高CDN缓存未命中,增加源站负载、带宽成本并拖慢真人访问,部分网站已被迫封禁爬虫;传统通用缓存不再适配,需按人类与AI流量分层路由,并采用AI感知缓存算法和独立缓存层。
浏览最新公开文章、摘要与延伸阅读。肖恩子的知识花园
英文Cloudflare称其网络32%流量来自自动化请求,AI爬虫因高并发、长尾扫描、高唯一URL和低复用率,显著拉高CDN缓存未命中,增加源站负载、带宽成本并拖慢真人访问,部分网站已被迫封禁爬虫;传统通用缓存不再适配,需按人类与AI流量分层路由,并采用AI感知缓存算法和独立缓存层。
 英文
英文作者用LLM把论文、文章、仓库和图片等原始资料持续编译成由Markdown构成的个人知识库,并在Obsidian中查看与管理,LLM负责摘要、分类、链接、问答、可视化和数据校验,用户几乎不手动编辑;在中小规模下无需复杂RAG也能高效检索与研究,且查询结果会反哺知识库,最终指向可产品化的知识操作系统。
 中文
中文DeepSeek进入调整期,部分核心作者离职,V4延期、产品化和估值管理提速;公司仍坚持扁平组织、不加班、重研究与原创探索,聚焦效率优化、架构改进和国产生态适配。团队虽有流动但未失序,更多成员留下,未来将加强Agent产品布局,在理想导向与商业竞争间寻找平衡。
 英文
英文文章基于源码拆解Claude Code的实际运行机制,聚焦用户输入后系统如何进入代理循环、调用50多种工具并进行多代理协同,进一步揭示其尚未发布的功能线索。Claude Code并非单一对话程序,而是具备复杂编排与扩展能力的代理式开发系统。
 英文
英文METR提出“时间跨度”指标衡量AI独立完成长软件任务的能力,基于170项任务测试发现,大模型可胜任任务对应的人类工作时长约每7个月翻倍,已从秒级提升到数小时至约12小时,按趋势未来数年或可处理相当于专家数周的任务;但真实软件工作更混乱,自动化基准与现实可用性存在明显差距,现有结论应谨慎外推。
 中文
中文OpenClaw官方中国ClawHub站,为中国开发者提供Clawhub社区高质量Agent Skill的镜像加速服务。
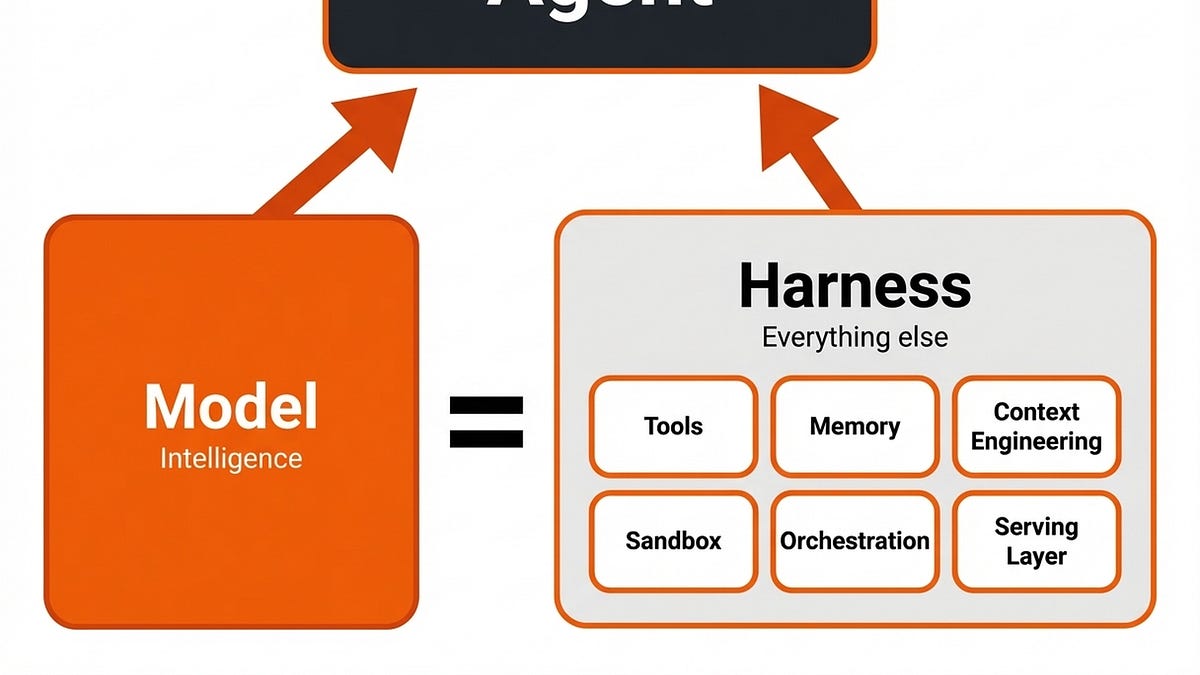 英文
英文作者认为生产级AI代理成败不在模型,而在其外部的“harness”系统;团队删去LlamaIndex、MCP和复杂RAG后,用简单API与自定义ReAct引擎,配合工具、记忆、护栏、编排、沙箱和上下文管理才真正跑通。企业应把重心从换模型转向构建可恢复、可持久、可部署的基础设施。
 中文
中文张雪从贫寒修车学徒转向造车创业,因坚持自研发动机与资本分歧,放弃凯越股权后重建张雪机车,并在一年内推出新车与819cc三缸平台,最终以中国自研赛车在WSBK葡萄牙站连夺两冠,打破欧日品牌长期垄断,证明持续研发和赛道验证能让中国摩托车品牌进入世界竞争核心。
AI编码代理将很快把漏洞研究成本压到近乎零,通过批量扫源代码并自动验证,高危零日会大规模出现,冲击将先落在浏览器、系统、数据库及大量难更新的联网设备上,改变攻防经济与互联网风险结构;作者判断这一趋势已基本锁定,防御和监管都可能跟不上。
