内容

封面图提示词:A bright, beautiful 16:9 oriental fantasy painterly anime environment key art. A luminous xianxia-inspired natural sanctuary at sunrise: vast lotus ponds and jade-green shallows surround broken white stone terraces, a huge ancient sacred tree arches overhead, golden sunlight pours through translucent leaves, floating petals and tiny glowing motes sparkle in the air. A small robed traveler stands on a mossy stone platform facing an elegant benevolent spirit creature made of light and water, creating a tranquil magical encounter. Wide cinematic composition, diagonal environmental framing, high-key cyan-green sky, warm amber water reflections, fresh lotus greens, turquoise and soft magenta accents, delicate clouds, misty mountains in the far distance, lush layered foliage, ornate but readable forms, poetic and serene mood, loose gouache-like brushwork, soft painterly texture, luminous atmosphere, game splash art quality. No text, no logo, no watermark, no UI, no dark horror mood, no photorealism, no cyberpunk, no battle scene.
AI代币期货
本周上海期货交易所已经把目光投向了另一种数字资产——AI代币。据路透社报道,SHFE正在设计基于AI代币的期货合约,试图为每日消耗量已达140万亿的AI推理需求提供价格锚定。意图将大模型的输入输出单位,变成像原油、铜、大豆一样可交易、可对冲的标准化合约。
这场实验的真正意义或许不止给企业一张对冲AI成本的保单。可能更标志着AI经济向"工业化原材料"前进,当推理代币进入期货交易所,就能争夺未来AI产业的定价权。与此同时,美国CME和ICE也在推进GPU算力期货,只是双方选择了截然不同的计价维度:中国押注软件层的"代币消耗",美国固守硬件层的"GPU算力"。
当然,这张合约距离真正敲钟还有漫长的路要走。没有现货基准、模型代币价值不可衡量、监管对"虚拟货币"的敏感红线,都是横在SHFE面前的结构性难题。但无论如何,当140万亿代币的日流转量已经堪比一个小型经济体的GDP,市场需要的不只是更快的模型,更是一套让算力成本可预测、可定价、可交易的金融语法。上海期货交易所的这张草图,或许正是为那个语法写下的第一个标点。
个人动态
Aether:可演进的视觉素材库插件
Aether 是用于稳定复用视觉风格的 Codex 插件,可把参考图、提示词想法和生成结果沉淀为视觉记忆,后续自动召回风格、光影、色彩、构图、氛围、角色和负面规则来精修提示词,并根据新素材决定新建、归类、变体或合并,形成可演进素材库。
项目的起因是本周在使用AI生图的过程中,发现虽然模型的能力已经很强,但仅凭我那贫瘠的词汇描述,效果还是不稳定。因此想到能否使用AI多模态的能力,提前沉淀可复用的视觉素材,在使用的时候结合个人想法灵活组合,以达到生图稳定效果。目前还在不断优化中,感兴趣的朋友可以试用提建议,也欢迎直接PR共建。

热点事件
| 事件 | 一句话说明 |
|---|---|
| Claude Opus 4.8 发布 | Anthropic 发布 Claude Opus 4.8,新增“努力程度”控制、动态工作流研究预览和更便宜的快速模式。 |
| Anthropic 完成 650 亿美元融资 | Anthropic 最新融资轮筹集 650 亿美元,投后估值达 9650 亿美元,接近万亿美元规模。 |
| NVIDIA 与清华发布 Gamma-World | NVIDIA、清华等团队推出多智能体世界模型 Gamma-World,并登上 HuggingFace 日榜。 |
| OpenRouter 完成 1.13 亿美元 B 轮融资 | OpenRouter 估值升至 13 亿美元,其 AI 模型调用中转业务每周处理约 25 万亿 Token。 |
| Cognition 完成 10 亿美元 D 轮融资 | Cognition 估值达到 260 亿美元,年化收入超过 4.92 亿美元,企业客户使用量同比增长超过 10 倍。 |
| Snowflake 与 AWS 签署 60 亿美元合作 | 双方五年合作凸显企业 AI 负载从单纯 GPU 训练转向云资源、推理成本与治理数据平台协同优化。 |
| Google DeepMind 发布 AlphaProof Nexus | Google DeepMind 发布 AlphaProof Nexus,候选内容称该系统解决了 9 道埃尔德什数学难题。 |
| NVIDIA 开源 Polar 框架 | NVIDIA 开源面向代码智能体的强化学习训练框架 Polar,降低 Codex、Claude Code 等接入 GRPO 训练的成本。 |
| 苹果发布 PICO 图像编解码器研究 | 苹果研究团队发布 PICO,提出以人眼体验为目标的学习型压缩方案,平衡压缩率、画质和移动端速度。 |
| 昆仑万维发布 SkyClaw-v1.0 | 昆仑万维发布 SkyClaw-v1.0 Agent 模型,面向复杂工具调用、长链条推理和百万级上下文任务。 |
更多资讯可查看Infinitum AI日报:https://infinitum.shawnxie.top/daily
佳文共赏
假如…… 我们正身处人工智能泡沫之中

Ed Zitron认为AI行业已陷入由OpenAI、Anthropic、NVIDIA、云巨头和风投共同维持的泡沫,核心矛盾是算力承诺、GPU销售、数据中心建设和真实收入之间数学上无法闭合;需求主要由少数AI公司和云厂商互相投喂制造,企业ROI不清、用户增长和利润率恶化,一旦数据中心融资放缓或OpenAI、Anthropic增速不达预期,将引发GPU减值、债务违约、云厂商收入缺口、供应链崩溃和风投清算,结论是AI泡沫不是是否破裂,而是何时以何种方式爆炸。
通过人工智能扩展人类智能

现代AI并非复制人类智能,也不是简单统计工具,而是学习并延展沉淀在人类语言中的认知结构,因此能生成流畅文本、代码和推理,却因缺乏与现实世界的直接经验而容易幻觉、组合推理失败、视觉理解脆弱。AI风险不在于其拥有自主意图,而在于无责任地放大未扎根现实的模式,可信AI必须依赖人类设计的治理、评估、审计和安全约束。
AI 辅助工程师正在过劳,这样好吗?

AI辅助编程提升产出速度,却把开发者推入更高强度的提示、审查、调试和返工循环,削弱写代码带来的成就感、掌控感与系统理解,造成任务量膨胀、认知疲劳和职业认同动摇。可持续使用AI的关键不是追求全天候效率,而是重建边界、保留手写与思考时间、控制任务节奏,并把AI作为辅助而非压力放大器。
Codex 自我蒸馏提示词
使用 Codex 回溯近30天会话、记忆与纪事,识别重复、高成本、可复用的工作流程,优先复用现有技能、子代理或自动化,只为高置信度缺口创建最小资产,并输出候选短名单、创建结果、跳过项及需更多证据的事项,避免推测、重叠和宽泛封装。能有效沉淀有用技能、子代理或自动化。
选择保持人性
AI写作和学习工具正在制造低信息密度内容,并诱发“认知投降”:用户把思考、写作、判断交给AI。研究显示,直接给答案会削弱学习和判断,定制化引导则能提升成绩。关键不在是否使用AI,而在有意识地区分哪些任务可外包、哪些能力必须保留。
你今天消耗了多少个词元
企业为证明AI工具投资价值,开始用AI生成代码行数、token消耗等指标衡量开发者生产力,但这些数字可被误触或刻意刷高,且与问题是否被正确解决无关;真正高效的工程往往是删减、简化和提升可靠性,按输出体量考核只会奖励无效活动,最终衡量的是订阅消耗而非生产力。
使用 AI 更慢地写出更好的代码
作者反驳“AI 编程只会快速制造低质代码”,主张用 LLM 放慢开发、提升质量:让多个模型联合审查 PR、交叉验证并排序缺陷,再由开发者筛选修复关键问题;这种方法未必提高产出速度,却能发现新旧漏洞、避免错误方案、加深对代码库理解,最终让 AI 成为谨慎、高质量编程的辅助工具。
用 Pi 构建 Pi

Pi团队用Pi维护Pi时发现,LLM生成的议题和PR大量涌入,常把真实观察扩写成错误诊断、伪复现和过度设计,误导代理与维护者,增加审查和修复成本;近90天外部3145项中多数被自动关闭,PR合并率仅约8%。作者主张提交者只提供可验证事实,维护者坚持全局不变量和上游协作,开源价值不在孤立产码,而在共同维护可靠基础。
技术博客
编排税就是你

多代理并行不等于个人产能并行,真正瓶颈是开发者的判断、审查与合并能力;若盲目启动大量代理,只会增加上下文切换、浅层评审和认知债务。有效做法是按可审查速率限制代理数量,区分可委托任务与需亲自判断任务,批量评审并让机器自证,把注意力当作稀缺串行资源来架构。
我是如何使用 Cursor 的

作者从 Claude Code 转向 Cursor 后,认为多模型切换、快速上下文压缩和图形化工作流更适合智能体编程;其开源 pstack 插件,把调试、评审、测试、架构等工程方法固化为技能,强调先提升验证与可信度,再做多智能体并行;内部机器人 Benny 已用这些技能自动分诊、复现、修复并提交 PR。软件自动化的瓶颈不是写代码,而是可验证的端到端信任。
开源项目
DeepSeek-Reasonix:专为DeepSeek优化的AI编码智能体框架

DeepSeek-Reasonix是面向DeepSeek优化的开源终端AI编码智能体框架,以前缀缓存稳定性为核心,通过缓存优先循环、工具调用修复和成本控制降低长会话token开销,支持CLI、桌面端、QQ频道、MCP、技能与记忆系统。
资源推荐
SpriteCook:AI像素艺术生成工具
SpriteCook面向游戏开发者提供AI像素艺术生成,覆盖角色、资产包、动画和静态转动态资产制作,并配套手动编辑、模板、文档、社区支持。
学习资料
从零训练大语言模型
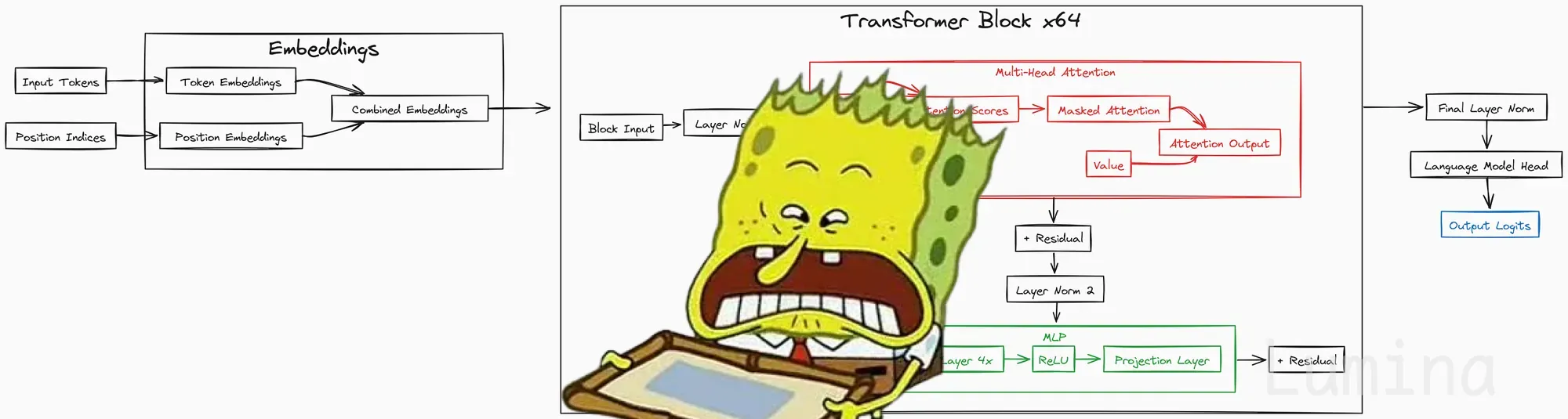
教程用PyTorch从零复现Transformer语言模型,覆盖The Pile数据下载、预处理、训练、生成与代码解析,支持1300万至20亿参数规模;项目模块化实现MLP、自注意力、因果掩码、Transformer块、嵌入和位置编码,并给出GPU显存与可训练规模参考。
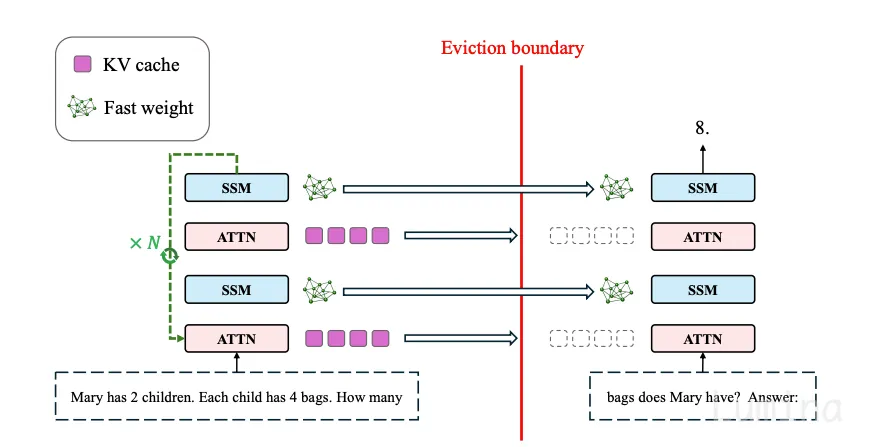
语言模型需要“睡眠”吗?借助离线循环机制优化在线推理
LLM Sleep提出在上下文窗口满后暂停输入,执行多次离线递归前向传播,用学习规则更新SSM快速权重,再清空KV缓存继续预测;其核心判断是长上下文失败主要源于被驱逐信息缺乏足够计算转化,而非内存容量不足。实验显示睡眠循环越多,Rule 110、Depo多跳检索、GSM-Infinite和滑动窗口任务的深度推理表现越好,收益集中在难例;代价是训练成本随循环深度线性上升且更不稳定。