 英文
英文6
AI 智能体软件包安全问题
技术博客
MCP安全供应链安全+3
作者: Andrew Nesbitt
发表时间:
Agent应用的十大风险几乎都可归结为包管理供应链问题,核心路径包括名称混淆、注册表与元数据投毒、依赖解析篡改、安装或导入时执行恶意代码、插件自动加载与凭证窃取;由于代理会自动发现、安装、执行并传播依赖,且权限更高、缺少人工复核,传统包管理漏洞被放大为更快扩散、更难察觉的系统性失陷。
浏览 技术博客 分类下的公开文章、摘要与延伸阅读。肖恩子的知识花园
英文Agent应用的十大风险几乎都可归结为包管理供应链问题,核心路径包括名称混淆、注册表与元数据投毒、依赖解析篡改、安装或导入时执行恶意代码、插件自动加载与凭证窃取;由于代理会自动发现、安装、执行并传播依赖,且权限更高、缺少人工复核,传统包管理漏洞被放大为更快扩散、更难察觉的系统性失陷。
核心是配置 Hysteria2 与 Clash 客户端直连运行:Cloudflare 子域名解析到 VPS,必须关闭代理改为 DNS Only,否则 QUIC 不可用;服务端监听 443,填写子域名、邮箱和强密码;客户端同步相同域名与密码到 proxy.yaml,最终实现基于 QUIC 的 HY2 节点接入与分流使用。
 英文
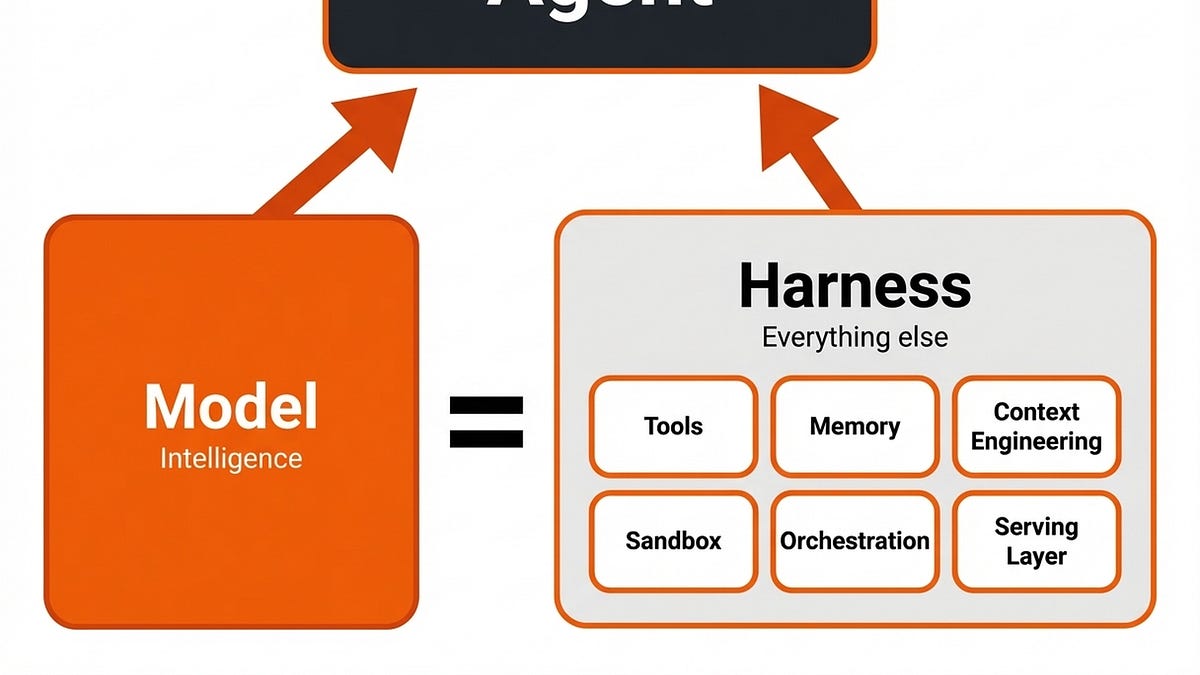
英文智能体能力主要取决于包裹LLM的“agent harness”,而非模型本身;其核心是编排循环、工具调用、记忆、上下文管理、状态持久化、错误处理、安全护栏、验证与多智能体协作,把无状态模型变成可执行系统。生产级效果差异往往来自harness设计,优秀方向是用更薄但更稳的基础设施提升性能。
 英文
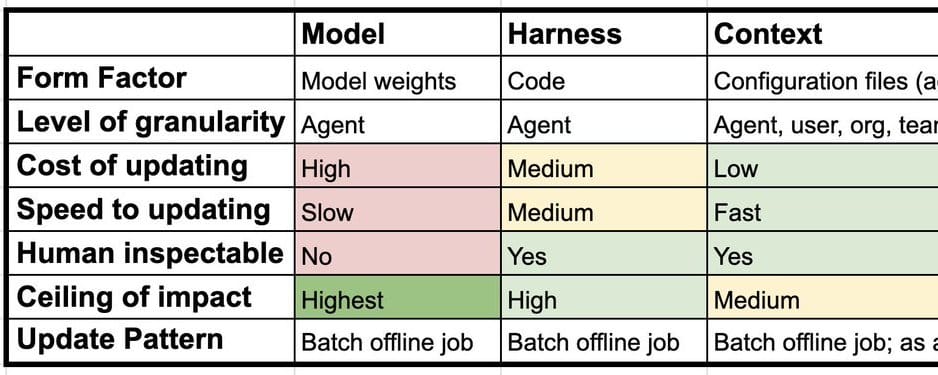
英文AI智能体的持续学习不只发生在模型权重,还包括驱动代理的harness和可配置的context,三层都能基于执行轨迹持续更新;模型更新面临灾难性遗忘,harness可通过分析任务日志迭代代码,context可在代理、用户或组织层离线或实时写入记忆;构建会长期变强的智能体,关键不只是训模型,而是用轨迹统筹优化三层。
 英文
英文编码代理的核心不在模型本身,而在其外层执行框架:通过实时仓库上下文、可复用提示缓存、受控工具调用、上下文压缩、结构化会话记忆和有边界的子代理协作,让LLM在代码检索、修改、测试和多轮连续任务中更高效、更可靠;因此优秀的coding harness往往比单纯更强的模型更能决定实际编码表现。
 英文
英文LangChain评测显示,开源模型GLM-5与MiniMax M2.7在文件操作、工具调用和指令遵循等代理核心任务上已接近闭源前沿模型,且成本和延迟显著更低,适合生产环境;Deep Agents已支持一键接入、本地或多提供商部署,并可在会话中切换模型,目前开源模型已能承担大量代理执行任务。
 英文
英文构建Claude应用的核心不是堆更多控制层,而是持续删减过时假设:优先用其已擅长的通用工具,让模型自己编排动作、管理与持久化上下文,仅在安全、体验、审计边界上保留必要工具与缓存设计;模型能力进化越快,agent harness越应轻量,否则会拖慢性能、抬高成本并限制效果。
 英文
英文Cloudflare称其网络32%流量来自自动化请求,AI爬虫因高并发、长尾扫描、高唯一URL和低复用率,显著拉高CDN缓存未命中,增加源站负载、带宽成本并拖慢真人访问,部分网站已被迫封禁爬虫;传统通用缓存不再适配,需按人类与AI流量分层路由,并采用AI感知缓存算法和独立缓存层。
 英文
英文作者认为生产级AI代理成败不在模型,而在其外部的“harness”系统;团队删去LlamaIndex、MCP和复杂RAG后,用简单API与自定义ReAct引擎,配合工具、记忆、护栏、编排、沙箱和上下文管理才真正跑通。企业应把重心从换模型转向构建可恢复、可持久、可部署的基础设施。
 英文
英文开发正从单AI协作转向多代理编排,核心做法是用子代理或代理团队并行分工、共享任务与隔离上下文,再用计划审批、测试钩子、文件锁和人工审查建立质量门禁,结论是多代理能显著提升吞吐与专业化,但真正瓶颈已从生成转向验证,成败取决于规格清晰度、协调机制和持续积累的AGENTS.md知识。