英文
英文25
以AI为核心不等于单纯使用AI
技术博客
AI优先单体仓库+3
作者: Peter Pang
发表时间:
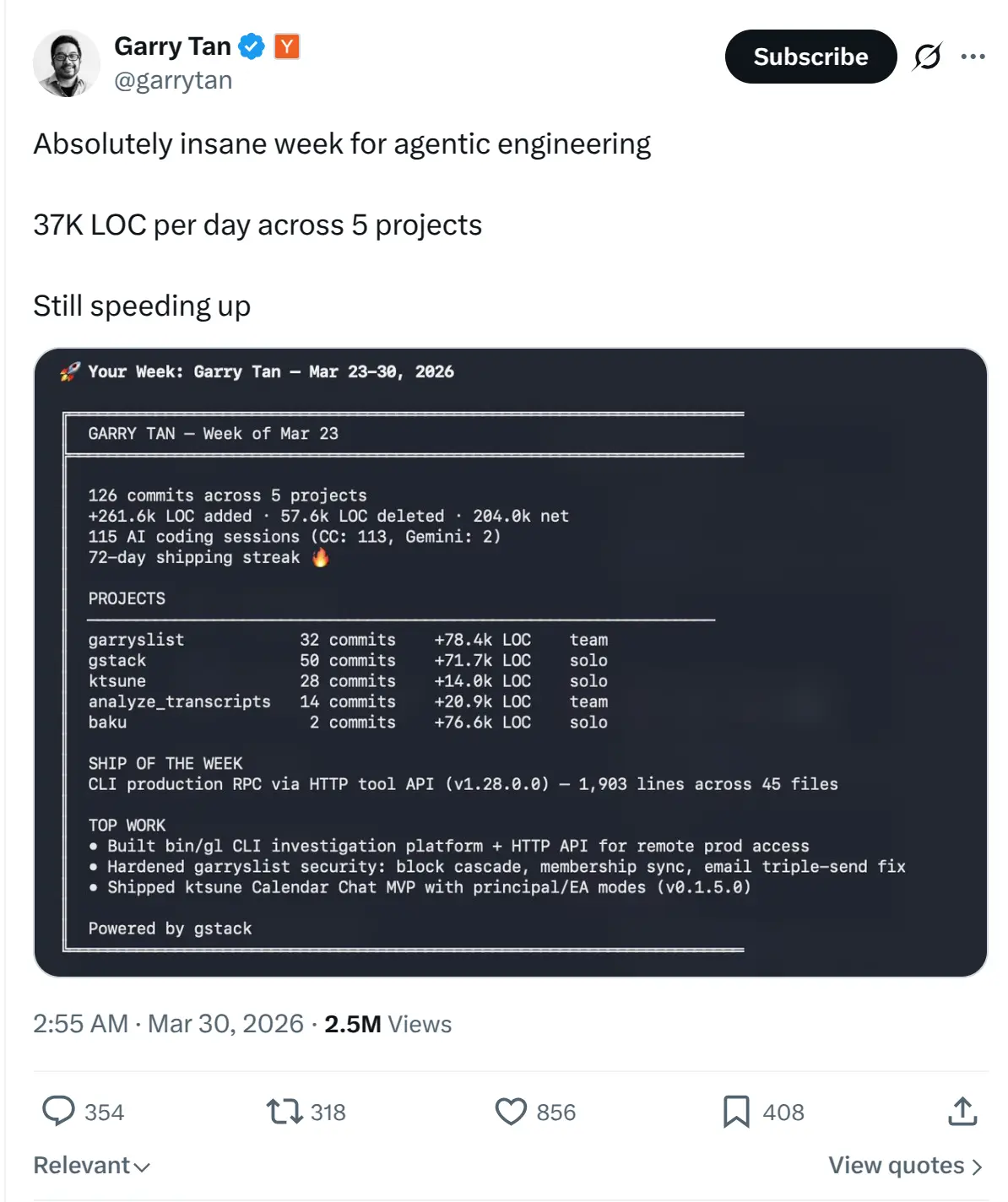
多数企业只是把AI嵌入原流程,效率仅小幅提升;真正的AI-first是围绕“AI主建、人类监督”重构产品、研发、测试与组织,并统一代码架构与自动化反馈闭环。作者团队借此把发布频率提升到日更级,缩短从想法到上线的周期,同时提高质量与转化,可见竞争力来自流程重构而非单点用AI。
浏览最新公开文章、摘要与延伸阅读。肖恩子的知识花园
英文多数企业只是把AI嵌入原流程,效率仅小幅提升;真正的AI-first是围绕“AI主建、人类监督”重构产品、研发、测试与组织,并统一代码架构与自动化反馈闭环。作者团队借此把发布频率提升到日更级,缩短从想法到上线的周期,同时提高质量与转化,可见竞争力来自流程重构而非单点用AI。
 中文
中文该GitHub仓库汇总全球100多个设计系统,覆盖企业、政府与品牌规范,并按组件、语音语调、设计工具包和源代码四项标签分类,帮助开发者快速筛选可参考资源;其结论是可高效对比主流设计规范,但开源标记不等于可任意使用,需核查许可证,且设计系统、UI库、模式库概念并不完全相同。
 中文
中文Archon是开源AI编程工作流引擎,用YAML把规划、实现、验证、审查到PR创建固化为可重复流程,结合确定性节点、AI循环和人工审批解决AI代理行为不一致问题,并通过独立git工作树支持多任务并行无冲突运行,提供CLI、Web UI及多平台接入与17种预置流程,最终让AI开发更标准化、可控且可异步扩展。
 英文
英文AI 编码代理读取文档依赖可发现性、可解析性、上下文 token 成本和访问权限,传统面向人类的页面分析几乎捕捉不到其行为;若文档过长、结构差或被 robots.txt 阻挡,代理会跳过、截断或幻觉生成。解决方案是做 AEO:提供 llms.txt、skill.md、AGENTS.md、Markdown 源、token 标注并监测 AI 流量,以提升代理调用成功率与文档实际可用性。
 中文
中文OpenAI推出免费学习平台OpenAI Academy,为全球教育、企业、政府等用户提供专家活动、社区协作和知识资源,系统教授从AI基础到高级集成的实用技能,支持线上线下参与与按兴趣地域连接,帮助用户更快获取产品前沿信息并用生成式AI提升问题解决、创造力与生产力。
 英文
英文多智能体协作应先选最简单可行方案,再按瓶颈演进:质量可显式校验用生成者—验证者,任务可清晰拆分用编排者—子代理,长期并行且相互独立用代理团队,事件驱动且生态扩张用消息总线,需要实时共享发现、避免单点故障用共享状态;关键在于任务依赖、上下文持续性与信息流方式是否匹配。
 英文
英文Anthropic推出Managed Agents,将长时代理拆成会话、编排器和沙箱三层接口并彻底解耦,使组件可独立替换、崩溃恢复和跨环境连接,同时把凭证隔离在沙箱外、将上下文持久化到会话日志而非模型窗口。让安全性、可调试性、扩展性显著提升,首字延迟大幅下降,并能适配未来更强模型与多代理协作。